 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSURL-2019 Task 7: Named Entity Recognition in Farsi
Mar 19, 2020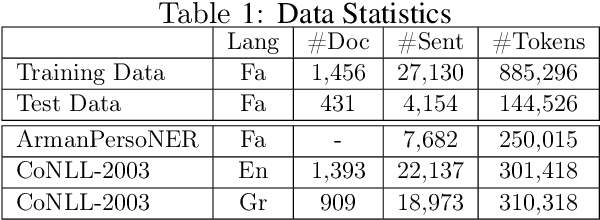
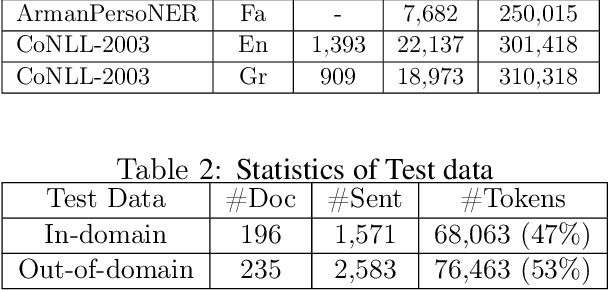
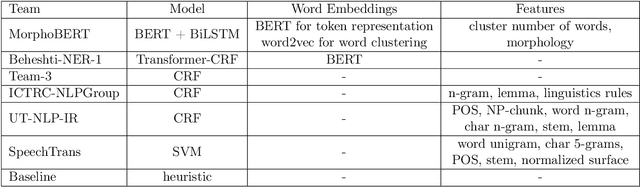
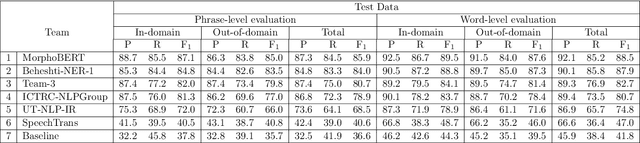
NSURL-2019 Task 7 focuses on Named Entity Recognition (NER) in Farsi. This task was chosen to compare different approaches to find phrases that specify Named Entities in Farsi texts, and to establish a standard testbed for future researches on this task in Farsi. This paper describes the process of making training and test data, a list of participating teams (6 teams), and evaluation results of their systems. The best system obtained 85.4% of F1 score based on phrase-level evaluation on seven classes of NEs including person, organization, location, date, time, money and percent.
Aspect Category Detection via Topic-Attention Network
Jan 04, 2019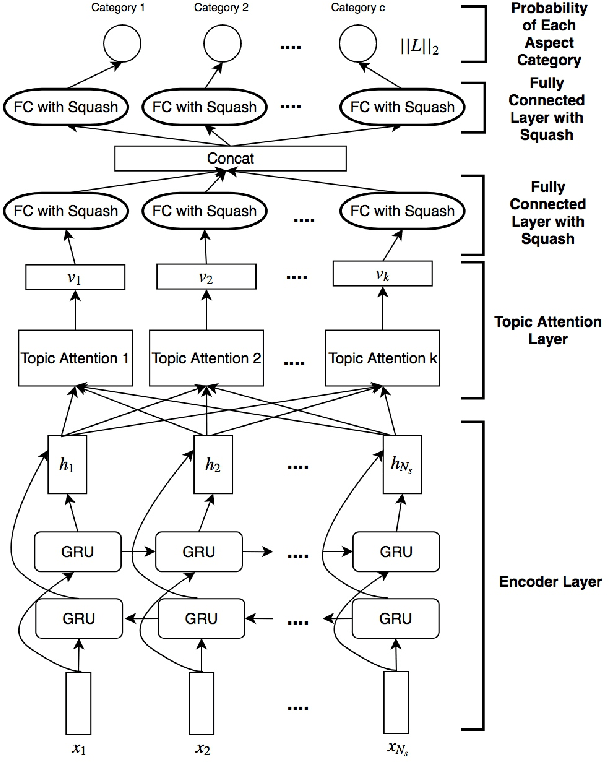
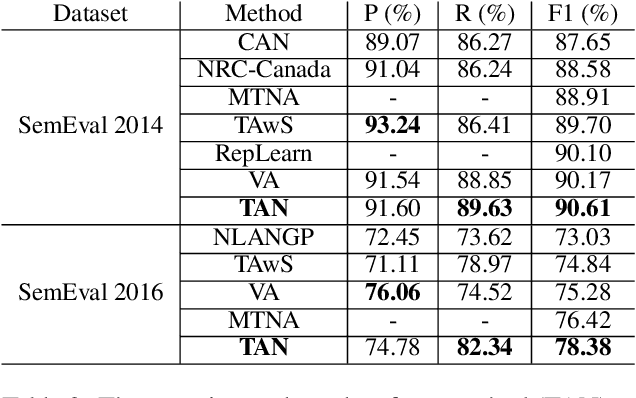
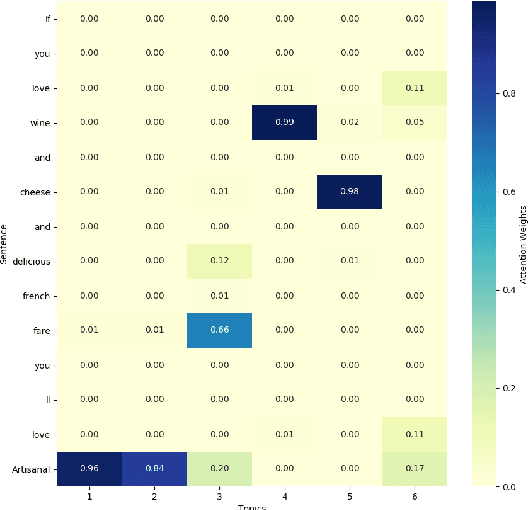
The e-commerce has started a new trend in natural language processing through sentiment analysis of user-generated reviews. Different consumers have different concerns about various aspects of a specific product or service. Aspect category detection, as a subtask of aspect-based sentiment analysis, tackles the problem of categorizing a given review sentence into a set of pre-defined aspect categories. In recent years, deep learning approaches have brought revolutionary advances in multiple branches of natural language processing including sentiment analysis. In this paper, we propose a deep neural network method based on attention mechanism to identify different aspect categories of a given review sentence. Our model utilizes several attentions with different topic contexts, enabling it to attend to different parts of a review sentence based on different topics. Experimental results on two datasets in the restaurant domain released by SemEval workshop demonstrates that our approach outperforms existing methods on both datasets. Visualization of the topic attention weights shows the effectiveness of our model in identifying words related to different topics.
An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure
Dec 08, 2018
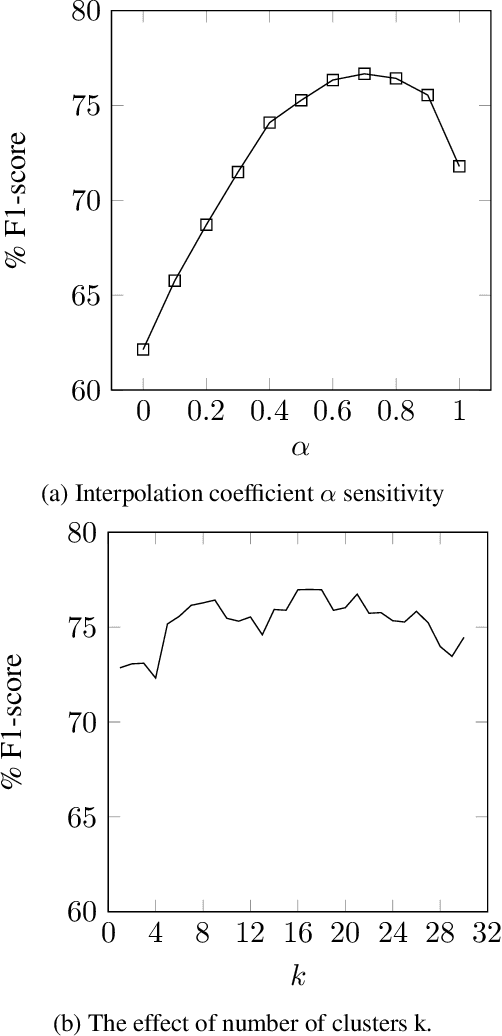
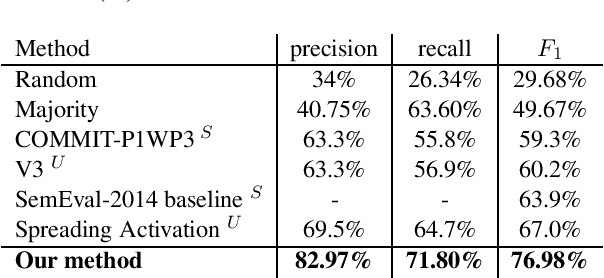
Aspect category detection is one of the important and challenging subtasks of aspect-based sentiment analysis. Given a set of pre-defined categories, this task aims to detect categories which are indicated implicitly or explicitly in a given review sentence. Supervised machine learning approaches perform well to accomplish this subtask. Note that, the performance of these methods depends on the availability of labeled train data, which is often difficult and costly to obtain. Besides, most of these supervised methods require feature engineering to perform well. In this paper, we propose an unsupervised method to address aspect category detection task without the need for any feature engineering. Our method utilizes clusters of unlabeled reviews and soft cosine similarity measure to accomplish aspect category detection task. Experimental results on SemEval-2014 restaurant dataset shows that proposed unsupervised approach outperforms several baselines by a substantial margin.
PEYMA: A Tagged Corpus for Persian Named Entities
Jan 30, 2018
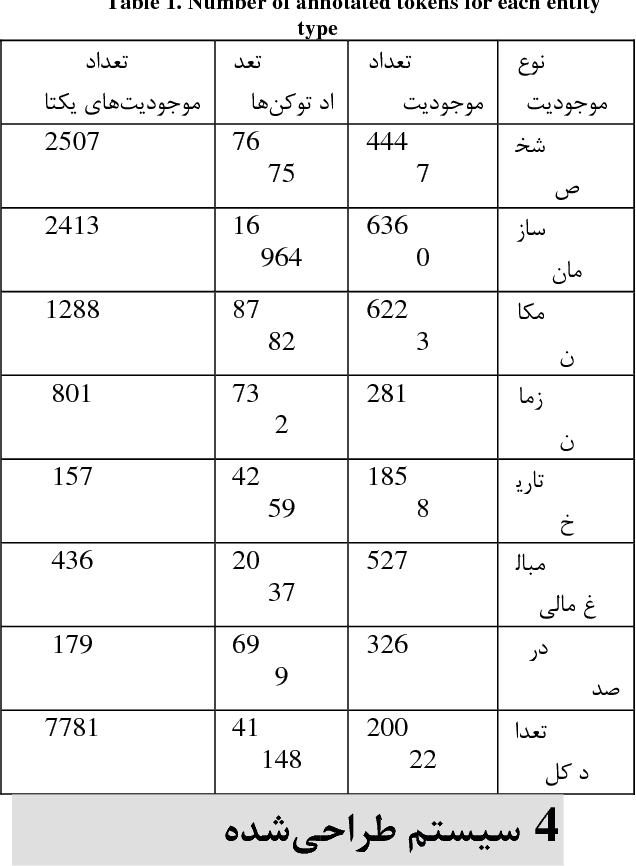
The goal in the NER task is to classify proper nouns of a text into classes such as person, location, and organization. This is an important preprocessing step in many NLP tasks such as question-answering and summarization. Although many research studies have been conducted in this area in English and the state-of-the-art NER systems have reached performances of higher than 90 percent in terms of F1 measure, there are very few research studies for this task in Persian. One of the main important causes of this may be the lack of a standard Persian NER dataset to train and test NER systems. In this research we create a standard, big-enough tagged Persian NER dataset which will be distributed for free for research purposes. In order to construct such a standard dataset, we studied standard NER datasets which are constructed for English researches and found out that almost all of these datasets are constructed using news texts. So we collected documents from ten news websites. Later, in order to provide annotators with some guidelines to tag these documents, after studying guidelines used for constructing CoNLL and MUC standard English datasets, we set our own guidelines considering the Persian linguistic rules.
Persian Wordnet Construction using Supervised Learning
Apr 11, 2017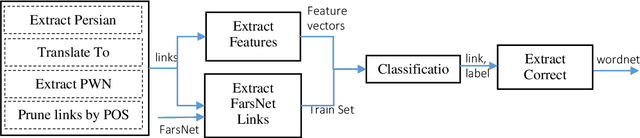
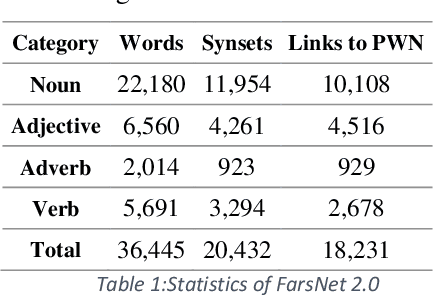
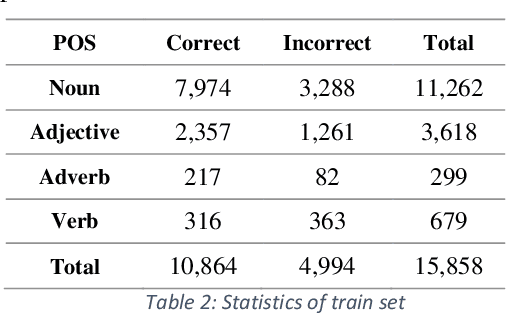
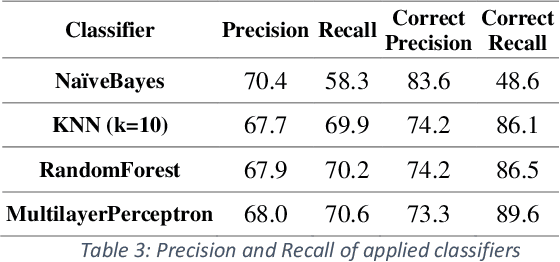
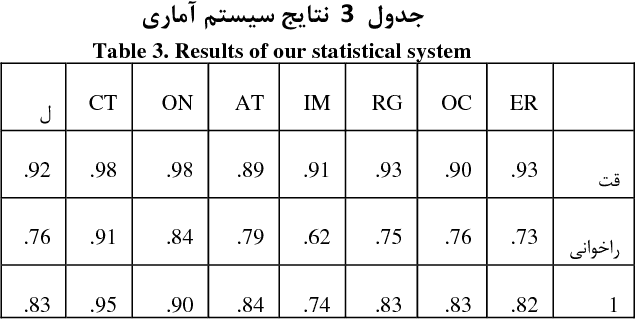
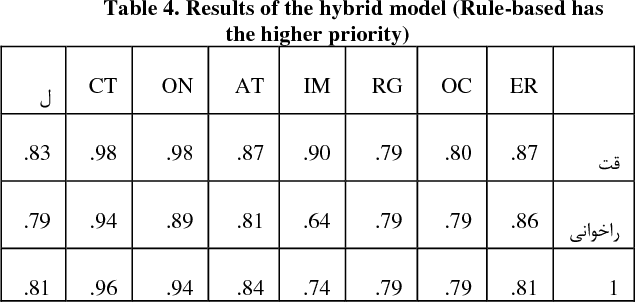
This paper presents an automated supervised method for Persian wordnet construction. Using a Persian corpus and a bi-lingual dictionary, the initial links between Persian words and Princeton WordNet synsets have been generated. These links will be discriminated later as correct or incorrect by employing seven features in a trained classification system. The whole method is just a classification system, which has been trained on a train set containing FarsNet as a set of correct instances. State of the art results on the automatically derived Persian wordnet is achieved. The resulted wordnet with a precision of 91.18% includes more than 16,000 words and 22,000 synsets.
Dimension Projection among Languages based on Pseudo-relevant Documents for Query Translation
Oct 08, 2016
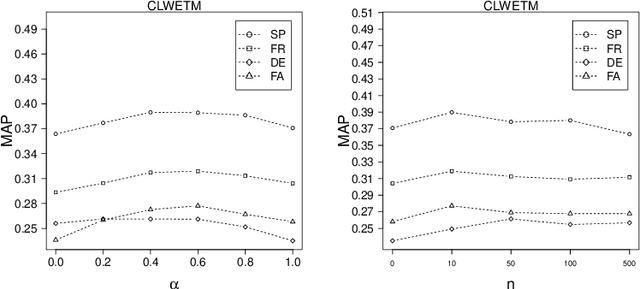
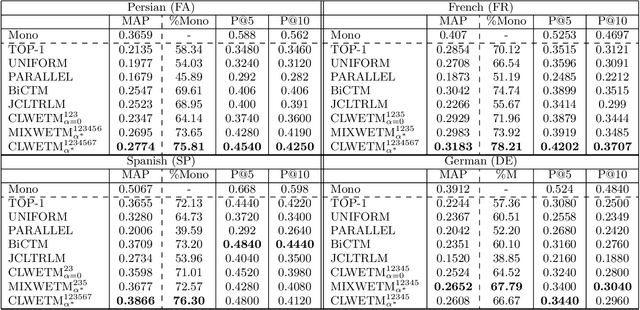
Using top-ranked documents in response to a query has been shown to be an effective approach to improve the quality of query translation in dictionary-based cross-language information retrieval. In this paper, we propose a new method for dictionary-based query translation based on dimension projection of embedded vectors from the pseudo-relevant documents in the source language to their equivalents in the target language. To this end, first we learn low-dimensional vectors of the words in the pseudo-relevant collections separately and then aim to find a query-dependent transformation matrix between the vectors of translation pairs appeared in the collections. At the next step, representation of each query term is projected to the target language and then, after using a softmax function, a query-dependent translation model is built. Finally, the model is used for query translation. Our experiments on four CLEF collections in French, Spanish, German, and Italian demonstrate that the proposed method outperforms a word embedding baseline based on bilingual shuffling and a further number of competitive baselines. The proposed method reaches up to 87% performance of machine translation (MT) in short queries and considerable improvements in verbose queries.
SS4MCT: A Statistical Stemmer for Morphologically Complex Texts
Jun 20, 2016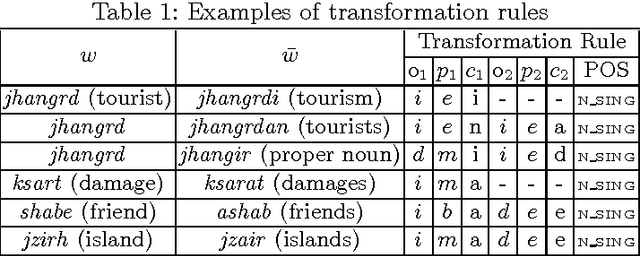
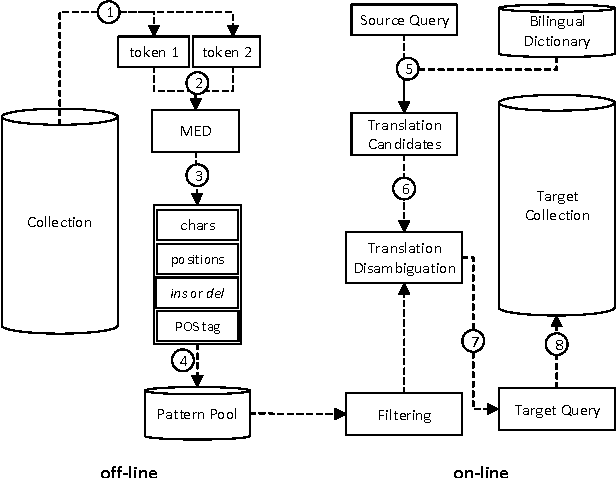

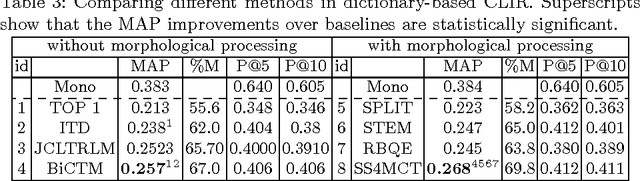
There have been multiple attempts to resolve various inflection matching problems in information retrieval. Stemming is a common approach to this end. Among many techniques for stemming, statistical stemming has been shown to be effective in a number of languages, particularly highly inflected languages. In this paper we propose a method for finding affixes in different positions of a word. Common statistical techniques heavily rely on string similarity in terms of prefix and suffix matching. Since infixes are common in irregular/informal inflections in morphologically complex texts, it is required to find infixes for stemming. In this paper we propose a method whose aim is to find statistical inflectional rules based on minimum edit distance table of word pairs and the likelihoods of the rules in a language. These rules are used to statistically stem words and can be used in different text mining tasks. Experimental results on CLEF 2008 and CLEF 2009 English-Persian CLIR tasks indicate that the proposed method significantly outperforms all the baselines in terms of MAP.
A Probabilistic Translation Method for Dictionary-based Cross-lingual Information Retrieval in Agglutinative Languages
Nov 05, 2014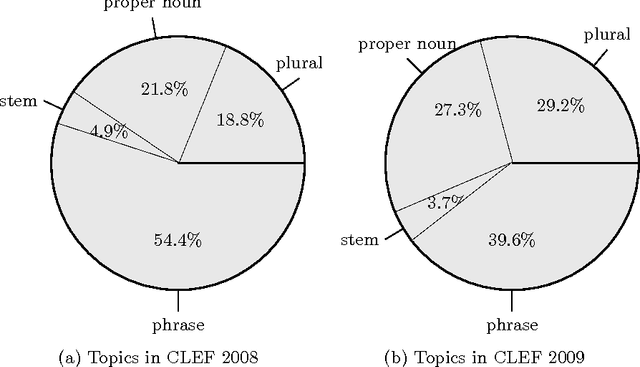


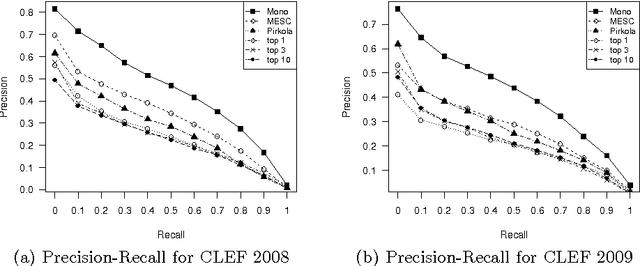
Translation ambiguity, out of vocabulary words and missing some translations in bilingual dictionaries make dictionary-based Cross-language Information Retrieval (CLIR) a challenging task. Moreover, in agglutinative languages which do not have reliable stemmers, missing various lexical formations in bilingual dictionaries degrades CLIR performance. This paper aims to introduce a probabilistic translation model to solve the ambiguity problem, and also to provide most likely formations of a dictionary candidate. We propose Minimum Edit Support Candidates (MESC) method that exploits a monolingual corpus and a bilingual dictionary to translate users' native language queries to documents' language. Our experiments show that the proposed method outperforms state-of-the-art dictionary-based English-Persian CLIR.
Learning to Exploit Different Translation Resources for Cross Language Information Retrieval
May 20, 2014One of the important factors that affects the performance of Cross Language Information Retrieval(CLIR)is the quality of translations being employed in CLIR. In order to improve the quality of translations, it is important to exploit available resources efficiently. Employing different translation resources with different characteristics has many challenges. In this paper, we propose a method for exploiting available translation resources simultaneously. This method employs Learning to Rank(LTR) for exploiting different translation resources. To apply LTR methods for query translation, we define different translation relation based features in addition to context based features. We use the contextual information contained in translation resources for extracting context based features.The proposed method uses LTR to construct a translation ranking model based on defined features. The constructed model is used for ranking translation candidates of query words. To evaluate the proposed method we do English-Persian CLIR, in which we employ the translation ranking model to find translations of English queries and employ the translations to retrieve Persian documents. Experimental results show that our approach significantly outperforms single resource based CLIR methods.