 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoom Clearance with Feudal Hierarchical Reinforcement Learning
May 24, 2021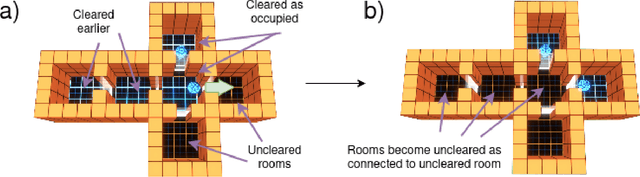
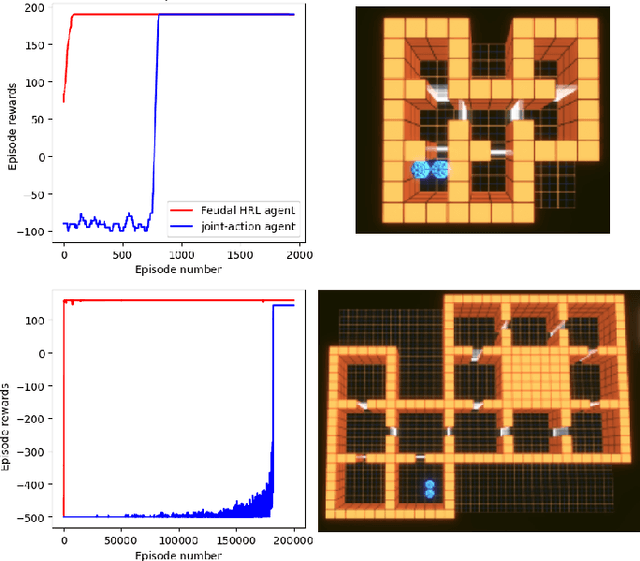
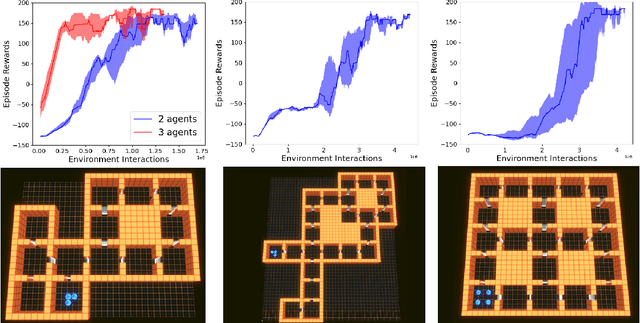

Reinforcement learning (RL) is a general framework that allows systems to learn autonomously through trial-and-error interaction with their environment. In recent years combining RL with expressive, high-capacity neural network models has led to impressive performance in a diverse range of domains. However, dealing with the large state and action spaces often required for problems in the real world still remains a significant challenge. In this paper we introduce a new simulation environment, "Gambit", designed as a tool to build scenarios that can drive RL research in a direction useful for military analysis. Using this environment we focus on an abstracted and simplified room clearance scenario, where a team of blue agents have to make their way through a building and ensure that all rooms are cleared of (and remain clear) of enemy red agents. We implement a multi-agent version of feudal hierarchical RL that introduces a command hierarchy where a commander at the higher level sends orders to multiple agents at the lower level who simply have to learn to follow these orders. We find that breaking the task down in this way allows us to solve a number of non-trivial floorplans that require the coordination of multiple agents much more efficiently than the standard baseline RL algorithms we compare with. We then go on to explore how qualitatively different behaviour can emerge depending on what we prioritise in the agent's reward function (e.g. clearing the building quickly vs. prioritising rescuing civilians).
Solving Challenging Dexterous Manipulation Tasks With Trajectory Optimisation and Reinforcement Learning
Sep 09, 2020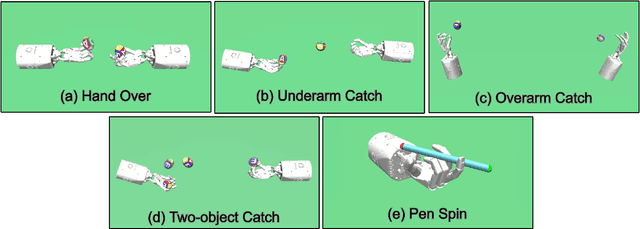
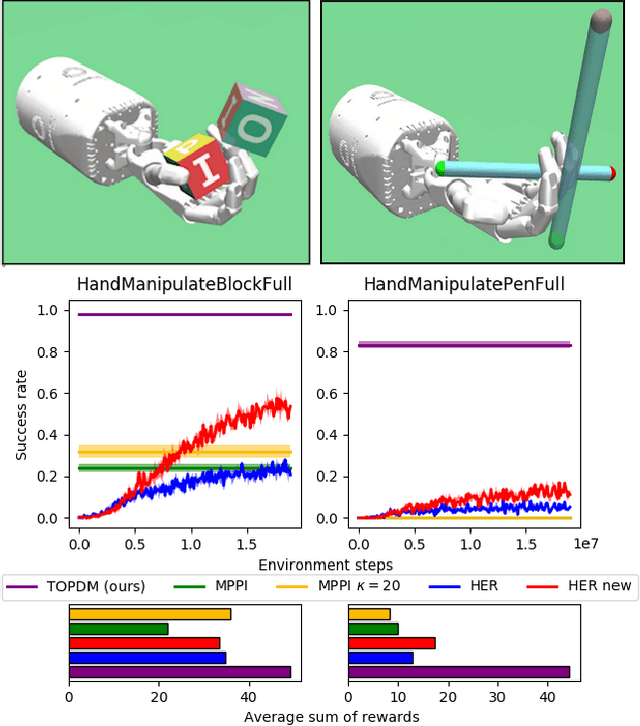
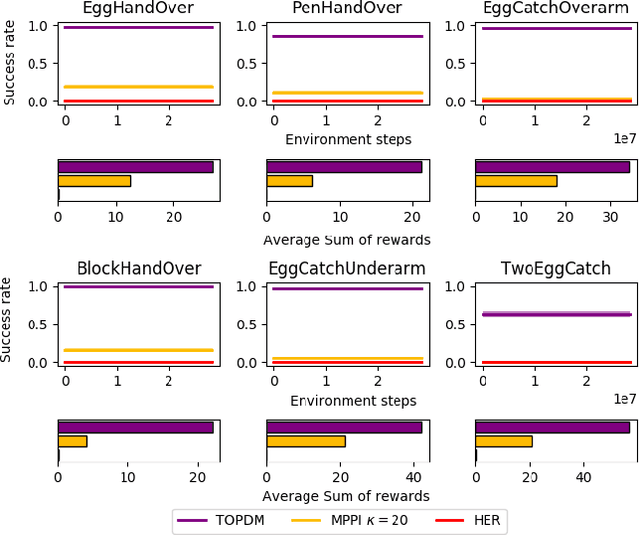
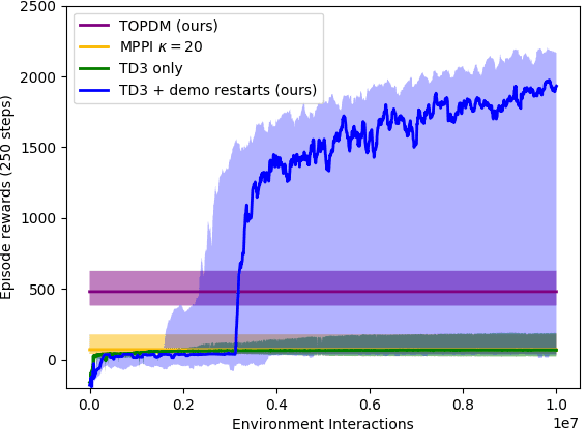
Training agents to autonomously learn how to use anthropomorphic robotic hands has the potential to lead to systems capable of performing a multitude of complex manipulation tasks in unstructured and uncertain environments. In this work, we first introduce a suite of challenging simulated manipulation tasks that current reinforcement learning and trajectory optimisation techniques find difficult. These include environments where two simulated hands have to pass or throw objects between each other, as well as an environment where the agent must learn to spin a long pen between its fingers. We then introduce a simple trajectory optimisation that performs significantly better than existing methods on these environments. Finally, on the challenging PenSpin task we combine sub-optimal demonstrations generated through trajectory optimisation with off-policy reinforcement learning, obtaining performance that far exceeds either of these approaches individually, effectively solving the environment.
PlanGAN: Model-based Planning With Sparse Rewards and Multiple Goals
Jun 01, 2020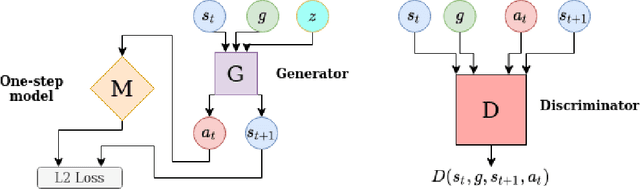
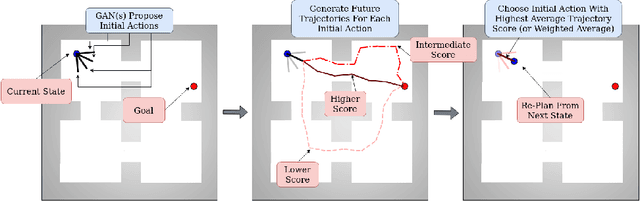

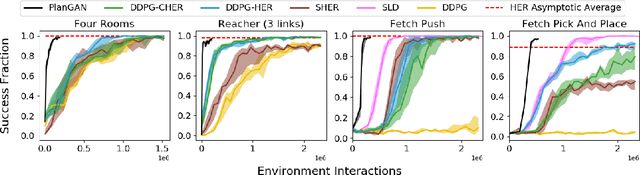
Learning with sparse rewards remains a significant challenge in reinforcement learning (RL), especially when the aim is to train a policy capable of achieving multiple different goals. To date, the most successful approaches for dealing with multi-goal, sparse reward environments have been model-free RL algorithms. In this work we propose PlanGAN, a model-based algorithm specifically designed for solving multi-goal tasks in environments with sparse rewards. Our method builds on the fact that any trajectory of experience collected by an agent contains useful information about how to achieve the goals observed during that trajectory. We use this to train an ensemble of conditional generative models (GANs) to generate plausible trajectories that lead the agent from its current state towards a specified goal. We then combine these imagined trajectories into a novel planning algorithm in order to achieve the desired goal as efficiently as possible. The performance of PlanGAN has been tested on a number of robotic navigation/manipulation tasks in comparison with a range of model-free reinforcement learning baselines, including Hindsight Experience Replay. Our studies indicate that PlanGAN can achieve comparable performance whilst being around 4-8 times more sample efficient.
Application of Self-Play Reinforcement Learning to a Four-Player Game of Imperfect Information
Aug 30, 2018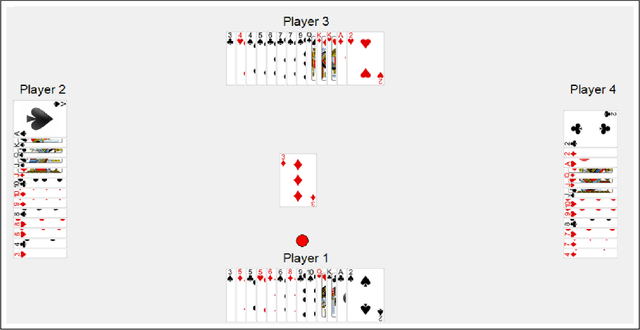

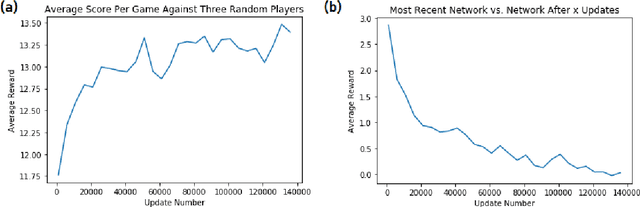
We introduce a new virtual environment for simulating a card game known as "Big 2". This is a four-player game of imperfect information with a relatively complicated action space (being allowed to play 1,2,3,4 or 5 card combinations from an initial starting hand of 13 cards). As such it poses a challenge for many current reinforcement learning methods. We then use the recently proposed "Proximal Policy Optimization" algorithm to train a deep neural network to play the game, purely learning via self-play, and find that it is able to reach a level which outperforms amateur human players after only a relatively short amount of training time and without needing to search a tree of future game states.