 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Modulated Avatars from Video
Aug 25, 2023It is now possible to reconstruct dynamic human motion and shape from a sparse set of cameras using Neural Radiance Fields (NeRF) driven by an underlying skeleton. However, a challenge remains to model the deformation of cloth and skin in relation to skeleton pose. Unlike existing avatar models that are learned implicitly or rely on a proxy surface, our approach is motivated by the observation that different poses necessitate unique frequency assignments. Neglecting this distinction yields noisy artifacts in smooth areas or blurs fine-grained texture and shape details in sharp regions. We develop a two-branch neural network that is adaptive and explicit in the frequency domain. The first branch is a graph neural network that models correlations among body parts locally, taking skeleton pose as input. The second branch combines these correlation features to a set of global frequencies and then modulates the feature encoding. Our experiments demonstrate that our network outperforms state-of-the-art methods in terms of preserving details and generalization capabilities.
NPC: Neural Point Characters from Video
Apr 04, 2023High-fidelity human 3D models can now be learned directly from videos, typically by combining a template-based surface model with neural representations. However, obtaining a template surface requires expensive multi-view capture systems, laser scans, or strictly controlled conditions. Previous methods avoid using a template but rely on a costly or ill-posed mapping from observation to canonical space. We propose a hybrid point-based representation for reconstructing animatable characters that does not require an explicit surface model, while being generalizable to novel poses. For a given video, our method automatically produces an explicit set of 3D points representing approximate canonical geometry, and learns an articulated deformation model that produces pose-dependent point transformations. The points serve both as a scaffold for high-frequency neural features and an anchor for efficiently mapping between observation and canonical space. We demonstrate on established benchmarks that our representation overcomes limitations of prior work operating in either canonical or in observation space. Moreover, our automatic point extraction approach enables learning models of human and animal characters alike, matching the performance of the methods using rigged surface templates despite being more general. Project website: https://lemonatsu.github.io/npc/
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023



Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Scaling Neural Face Synthesis to High FPS and Low Latency by Neural Caching
Nov 10, 2022Recent neural rendering approaches greatly improve image quality, reaching near photorealism. However, the underlying neural networks have high runtime, precluding telepresence and virtual reality applications that require high resolution at low latency. The sequential dependency of layers in deep networks makes their optimization difficult. We break this dependency by caching information from the previous frame to speed up the processing of the current one with an implicit warp. The warping with a shallow network reduces latency and the caching operations can further be parallelized to improve the frame rate. In contrast to existing temporal neural networks, ours is tailored for the task of rendering novel views of faces by conditioning on the change of the underlying surface mesh. We test the approach on view-dependent rendering of 3D portrait avatars, as needed for telepresence, on established benchmark sequences. Warping reduces latency by 70$\%$ (from 49.4ms to 14.9ms on commodity GPUs) and scales frame rates accordingly over multiple GPUs while reducing image quality by only 1$\%$, making it suitable as part of end-to-end view-dependent 3D teleconferencing applications. Our project page can be found at: https://yu-frank.github.io/lowlatency/.
UNeRF: Time and Memory Conscious U-Shaped Network for Training Neural Radiance Fields
Jun 23, 2022
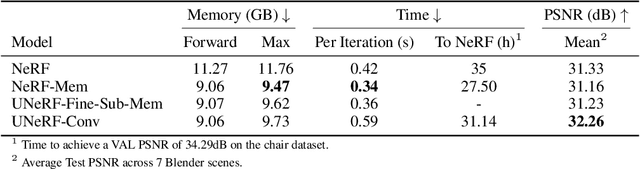
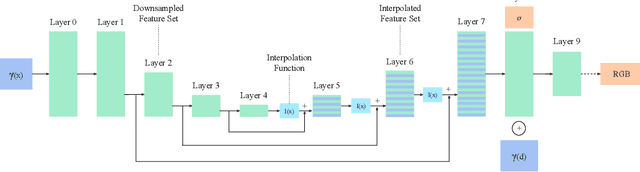

Neural Radiance Fields (NeRFs) increase reconstruction detail for novel view synthesis and scene reconstruction, with applications ranging from large static scenes to dynamic human motion. However, the increased resolution and model-free nature of such neural fields come at the cost of high training times and excessive memory requirements. Recent advances improve the inference time by using complementary data structures yet these methods are ill-suited for dynamic scenes and often increase memory consumption. Little has been done to reduce the resources required at training time. We propose a method to exploit the redundancy of NeRF's sample-based computations by partially sharing evaluations across neighboring sample points. Our UNeRF architecture is inspired by the UNet, where spatial resolution is reduced in the middle of the network and information is shared between adjacent samples. Although this change violates the strict and conscious separation of view-dependent appearance and view-independent density estimation in the NeRF method, we show that it improves novel view synthesis. We also introduce an alternative subsampling strategy which shares computation while minimizing any violation of view invariance. UNeRF is a plug-in module for the original NeRF network. Our major contributions include reduction of the memory footprint, improved accuracy, and reduced amortized processing time both during training and inference. With only weak assumptions on locality, we achieve improved resource utilization on a variety of neural radiance fields tasks. We demonstrate applications to the novel view synthesis of static scenes as well as dynamic human shape and motion.
AutoLink: Self-supervised Learning of Human Skeletons and Object Outlines by Linking Keypoints
May 21, 2022
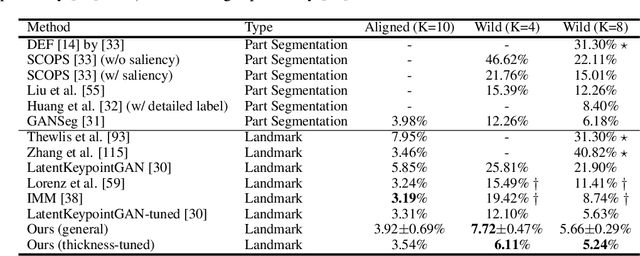
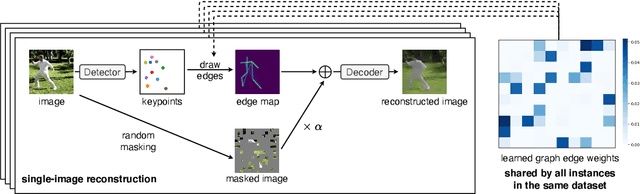
Structured representations such as keypoints are widely used in pose transfer, conditional image generation, animation, and 3D reconstruction. However, their supervised learning requires expensive annotation for each target domain. We propose a self-supervised method that learns to disentangle object structure from the appearance with a graph of 2D keypoints linked by straight edges. Both the keypoint location and their pairwise edge weights are learned, given only a collection of images depicting the same object class. The graph is interpretable, for example, AutoLink recovers the human skeleton topology when applied to images showing people. Our key ingredients are i) an encoder that predicts keypoint locations in an input image, ii) a shared graph as a latent variable that links the same pairs of keypoints in every image, iii) an intermediate edge map that combines the latent graph edge weights and keypoint locations in a soft, differentiable manner, and iv) an inpainting objective on randomly masked images. Although simpler, AutoLink outperforms existing self-supervised methods on the established keypoint and pose estimation benchmarks and paves the way for structure-conditioned generative models on more diverse datasets.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 17, 2022
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
DANBO: Disentangled Articulated Neural Body Representations via Graph Neural Networks
May 03, 2022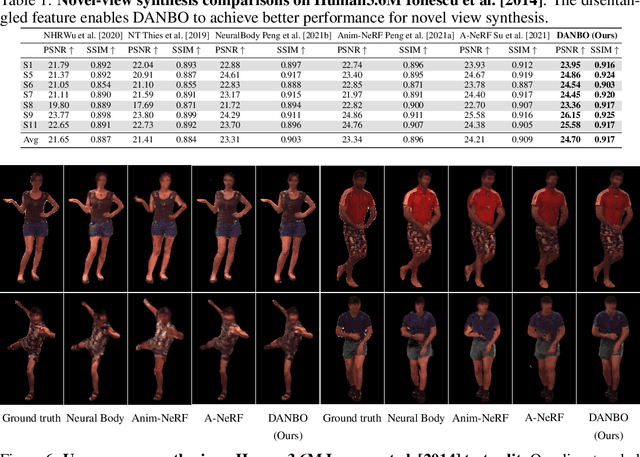
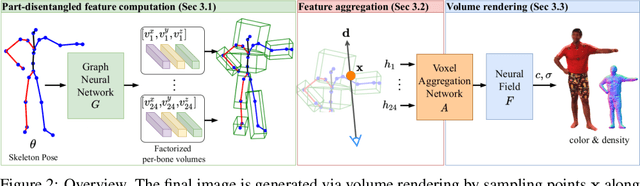
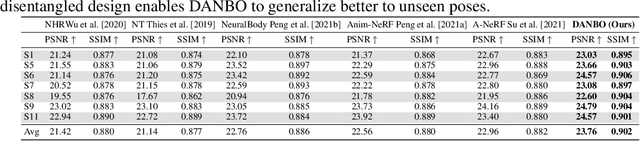
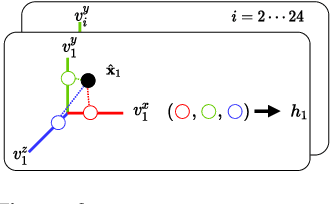
Deep learning greatly improved the realism of animatable human models by learning geometry and appearance from collections of 3D scans, template meshes, and multi-view imagery. High-resolution models enable photo-realistic avatars but at the cost of requiring studio settings not available to end users. Our goal is to create avatars directly from raw images without relying on expensive studio setups and surface tracking. While a few such approaches exist, those have limited generalization capabilities and are prone to learning spurious (chance) correlations between irrelevant body parts, resulting in implausible deformations and missing body parts on unseen poses. We introduce a three-stage method that induces two inductive biases to better disentangled pose-dependent deformation. First, we model correlations of body parts explicitly with a graph neural network. Second, to further reduce the effect of chance correlations, we introduce localized per-bone features that use a factorized volumetric representation and a new aggregation function. We demonstrate that our model produces realistic body shapes under challenging unseen poses and shows high-quality image synthesis. Our proposed representation strikes a better trade-off between model capacity, expressiveness, and robustness than competing methods. Project website: https://lemonatsu.github.io/danbo.
A Simple Method to Boost Human Pose Estimation Accuracy by Correcting the Joint Regressor for the Human3.6m Dataset
Apr 29, 2022
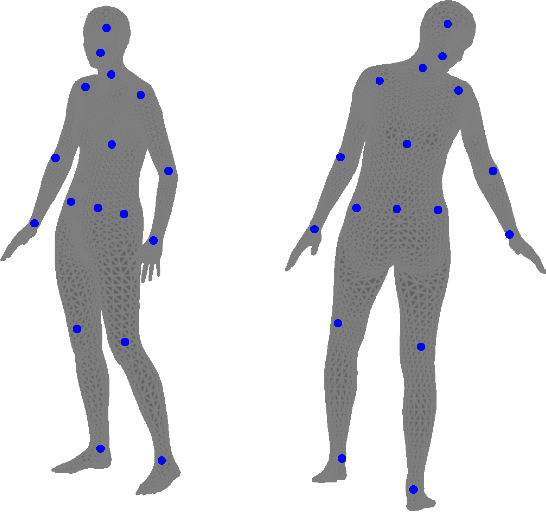


Many human pose estimation methods estimate Skinned Multi-Person Linear (SMPL) models and regress the human joints from these SMPL estimates. In this work, we show that the most widely used SMPL-to-joint linear layer (joint regressor) is inaccurate, which may mislead pose evaluation results. To achieve a more accurate joint regressor, we propose a method to create pseudo-ground-truth SMPL poses, which can then be used to train an improved regressor. Specifically, we optimize SMPL estimates coming from a state-of-the-art method so that its projection matches the silhouettes of humans in the scene, as well as the ground-truth 2D joint locations. While the quality of this pseudo-ground-truth is challenging to assess due to the lack of actual ground-truth SMPL, with the Human 3.6m dataset, we qualitatively show that our joint locations are more accurate and that our regressor leads to improved pose estimations results on the test set without any need for retraining. We release our code and joint regressor at https://github.com/ubc-vision/joint-regressor-refinement
Domain Knowledge-Informed Self-Supervised Representations for Workout Form Assessment
Feb 28, 2022
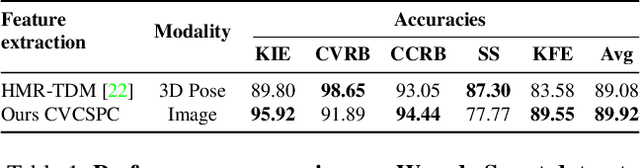
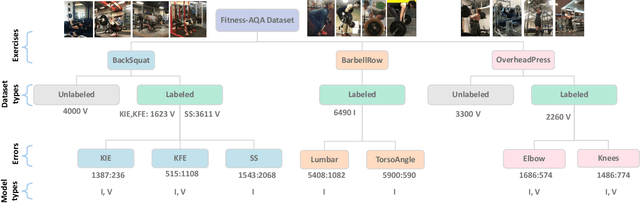
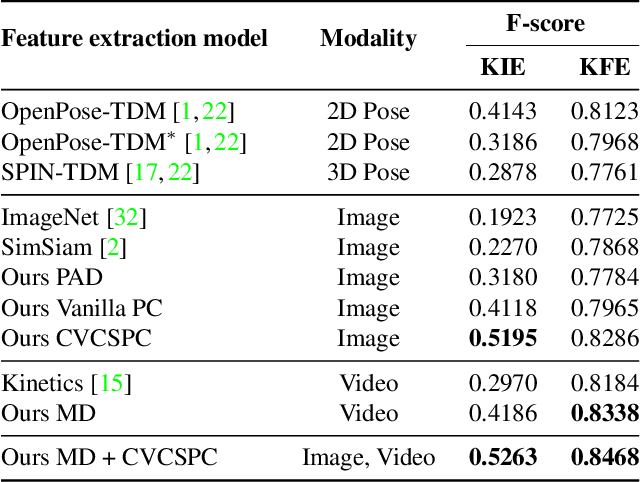
Maintaining proper form while exercising is important for preventing injuries and maximizing muscle mass gains. While fitness apps are becoming popular, they lack the functionality to detect errors in workout form. Detecting such errors naturally requires estimating users' body pose. However, off-the-shelf pose estimators struggle to perform well on the videos recorded in gym scenarios due to factors such as camera angles, occlusion from gym equipment, illumination, and clothing. To aggravate the problem, the errors to be detected in the workouts are very subtle. To that end, we propose to learn exercise-specific representations from unlabeled samples such that a small dataset annotated by experts suffices for supervised error detection. In particular, our domain knowledge-informed self-supervised approaches exploit the harmonic motion of the exercise actions, and capitalize on the large variances in camera angles, clothes, and illumination to learn powerful representations. To facilitate our self-supervised pretraining, and supervised finetuning, we curated a new exercise dataset, Fitness-AQA, comprising of three exercises: BackSquat, BarbellRow, and OverheadPress. It has been annotated by expert trainers for multiple crucial and typically occurring exercise errors. Experimental results show that our self-supervised representations outperform off-the-shelf 2D- and 3D-pose estimators and several other baselines.