 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020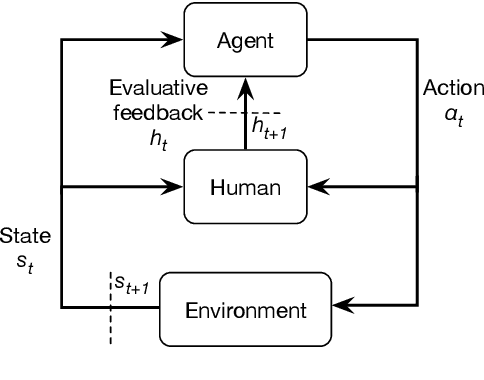
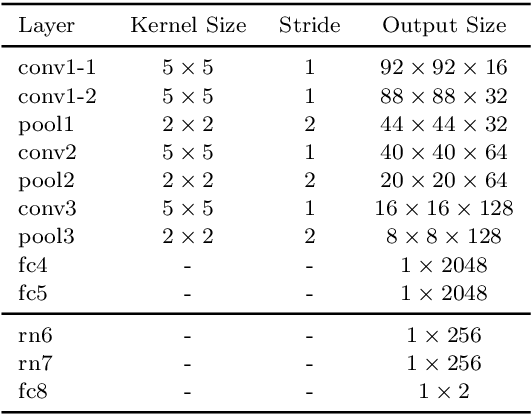
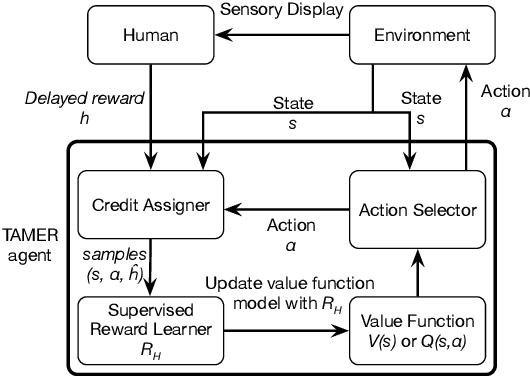
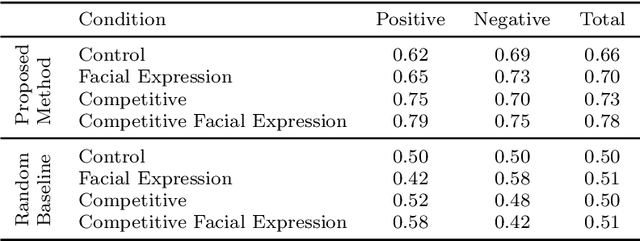
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
Detecting F-formations & Roles in Crowded Social Scenes with Wearables: Combining Proxemics & Dynamics using LSTMs
Nov 17, 2019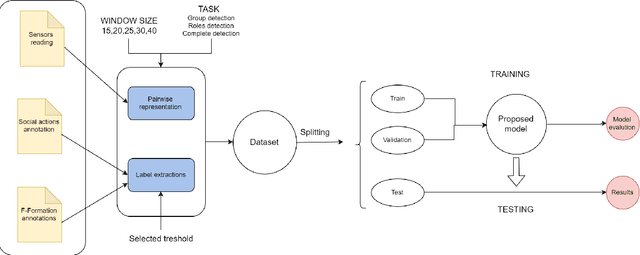
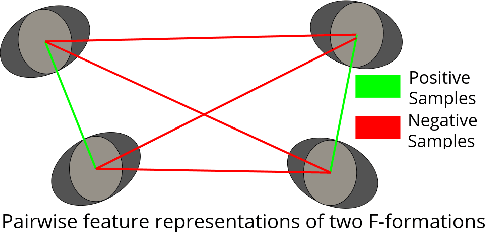
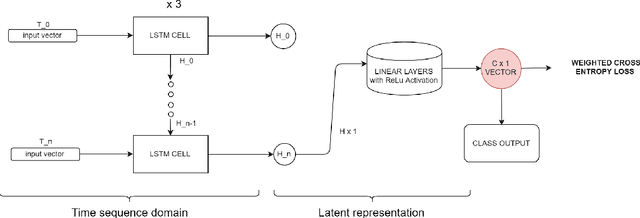
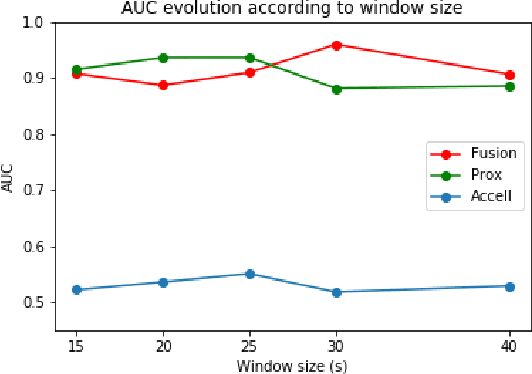
In this paper, we investigate the use of proxemics and dynamics for automatically identifying conversing groups, or so-called F-formations. More formally we aim to automatically identify whether wearable sensor data coming from 2 people is indicative of F-formation membership. We also explore the problem of jointly detecting membership and more descriptive information about the pair relating to the role they take in the conversation (i.e. speaker or listener). We jointly model the concepts of proxemics and dynamics using binary proximity and acceleration obtained through a single wearable sensor per person. We test our approaches on the publicly available MatchNMingle dataset which was collected during real-life mingling events. We find out that fusion of these two modalities performs significantly better than them independently, providing an AUC of 0.975 when data from 30-second windows are used. Furthermore, our investigation into roles detection shows that each role pair requires a different time resolution for accurate detection.
Towards automatic estimation of conversation floors within F-formations
Jul 31, 2019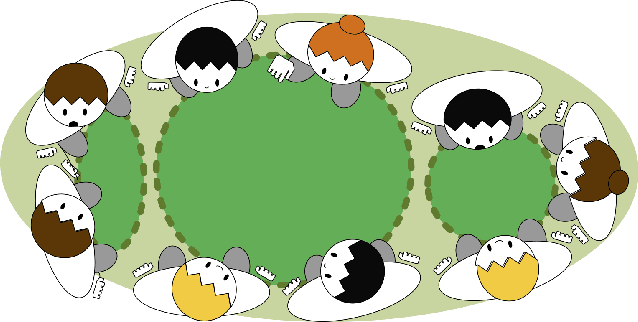
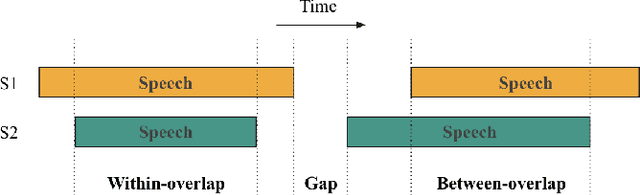

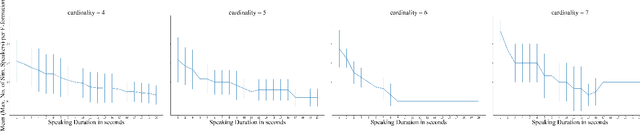
The detection of free-standing conversing groups has received significant attention in recent years. In the absence of a formal definition, most studies operationalize the notion of a conversation group either through a spatial or a temporal lens. Spatially, the most commonly used representation is the F-formation, defined by social scientists as the configuration in which people arrange themselves to sustain an interaction. However, the use of this representation is often accompanied with the simplifying assumption that a single conversation occurs within an F-formation. Temporally, various categories have been used to organize conversational units; these include, among others, turn, topic, and floor. Some of these concepts are hard to define objectively by themselves. The present work constitutes an initial exploration into unifying these perspectives by primarily posing the question: can we use the observation of simultaneous speaker turns to infer whether multiple conversation floors exist within an F-formation? We motivate a metric for the existence of distinct conversation floors based on simultaneous speaker turns, and provide an analysis using this metric to characterize conversations across F-formations of varying cardinality. We contribute two key findings: firstly, at the average speaking turn duration of about two seconds for humans, there is evidence for the existence of multiple floors within an F-formation; and secondly, an increase in the cardinality of an F-formation correlates with a decrease in duration of simultaneous speaking turns.
Improving Temporal Interpolation of Head and Body Pose using Gaussian Process Regression in a Matrix Completion Setting
Aug 06, 2018
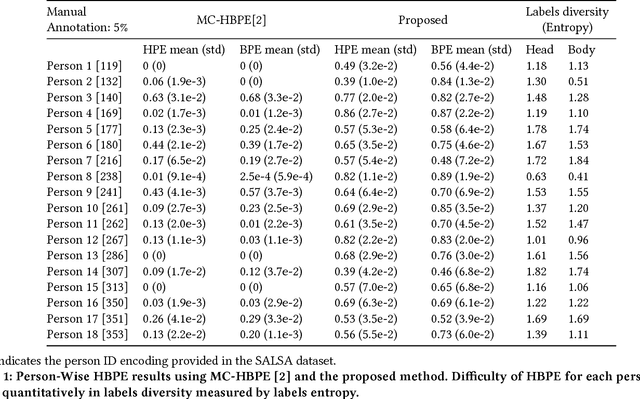

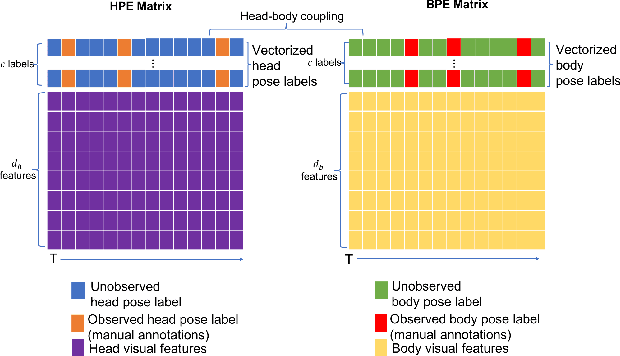
This paper presents a model for head and body pose estimation (HBPE) when labelled samples are highly sparse. The current state-of-the-art multimodal approach to HBPE utilizes the matrix completion method in a transductive setting to predict pose labels for unobserved samples. Based on this approach, the proposed method tackles HBPE when manually annotated ground truth labels are temporally sparse. We posit that the current state of the art approach oversimplifies the temporal sparsity assumption by using Laplacian smoothing. Our final solution uses: i) Gaussian process regression in place of Laplacian smoothing, ii) head and body coupling, and iii) nuclear norm minimization in the matrix completion setting. The model is applied to the challenging SALSA dataset for benchmark against the state-of-the-art method. Our presented formulation outperforms the state-of-the-art significantly in this particular setting, e.g. at 5% ground truth labels as training data, head pose accuracy and body pose accuracy is approximately 62% and 70%, respectively. As well as fitting a more flexible model to missing labels in time, we posit that our approach also loosens the head and body coupling constraint, allowing for a more expressive model of the head and body pose typically seen during conversational interaction in groups. This provides a new baseline to improve upon for future integration of multimodal sensor data for the purpose of HBPE.