 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIGMO: Categorical invariant representations in a deep generative framework
May 27, 2022
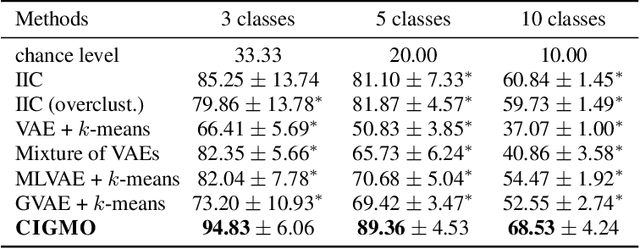

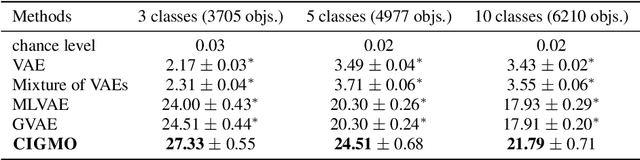
Data of general object images have two most common structures: (1) each object of a given shape can be rendered in multiple different views, and (2) shapes of objects can be categorized in such a way that the diversity of shapes is much larger across categories than within a category. Existing deep generative models can typically capture either structure, but not both. In this work, we introduce a novel deep generative model, called CIGMO, that can learn to represent category, shape, and view factors from image data. The model is comprised of multiple modules of shape representations that are each specialized to a particular category and disentangled from view representation, and can be learned using a group-based weakly supervised learning method. By empirical investigation, we show that our model can effectively discover categories of object shapes despite large view variation and quantitatively supersede various previous methods including the state-of-the-art invariant clustering algorithm. Further, we show that our approach using category-specialization can enhance the learned shape representation to better perform down-stream tasks such as one-shot object identification as well as shape-view disentanglement.
A simple probabilistic deep generative model for learning generalizable disentangled representations from grouped data
Sep 07, 2018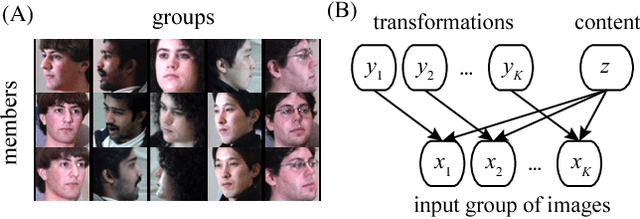
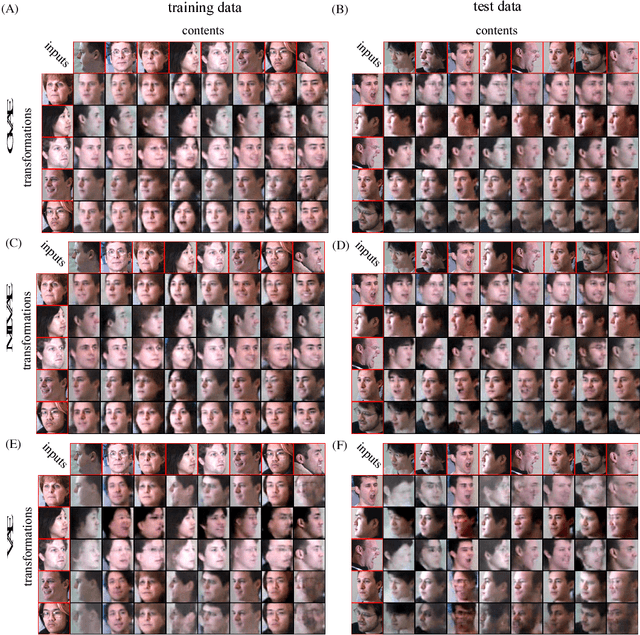
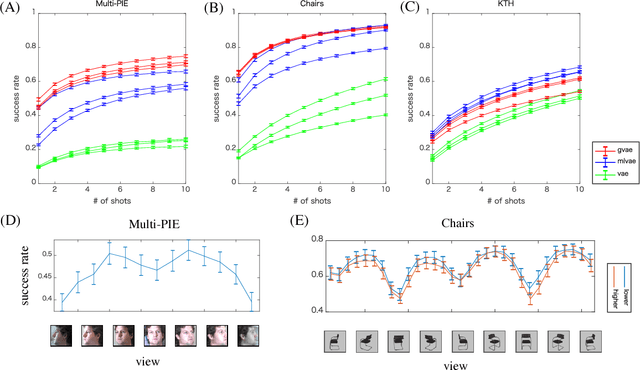
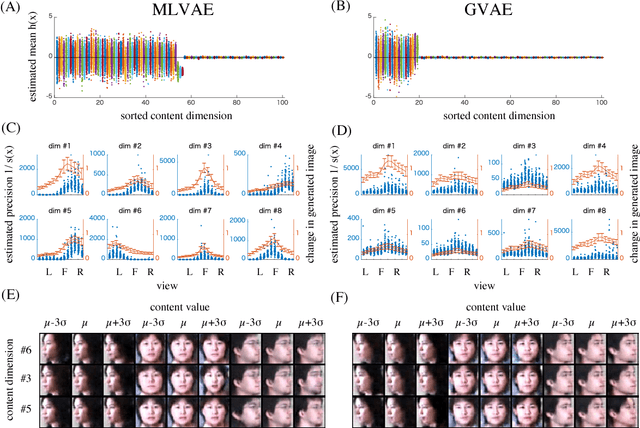
The disentangling problem is to discover multiple complex factors of variations hidden in data. One recent approach is to take a dataset with grouping structure and separately estimate a factor common within a group (content) and a factor specific to each group member (transformation). Notably, this approach can learn to represent a continuous space of contents, which allows for generalization to data with unseen contents. In this study, we aim at cultivating this approach within probabilistic deep generative models. Motivated by technical complication in existing group-based methods, we propose a simpler probabilistic method, called group-contrastive variational autoencoders. Despite its simplicity, our approach achieves reasonable disentanglement with generalizability for three grouped datasets of 3D object images. In comparison with a previous model, although conventional qualitative evaluation shows little difference, our qualitative evaluation using few-shot classification exhibits superior performances for some datasets. We analyze the content representations from different methods and discuss their transformation-dependency and potential performance impacts.