 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic, Madness, Heaven, Sin: LLM Output Diversity is Everything, Everywhere, All at Once
Apr 02, 2026Research on Large Language Models (LLMs) studies output variation across generation, reasoning, alignment, and representational analysis, often under the umbrella of "diversity." Yet the terminology remains fragmented, largely because the normative objectives underlying tasks are rarely made explicit. We introduce the Magic, Madness, Heaven, Sin framework, which models output variation along a homogeneity-heterogeneity axis, where valuation is determined by the task and its normative objective. We organize tasks into four normative contexts: epistemic (factuality), interactional (user utility), societal (representation), and safety (robustness). For each, we examine the failure modes and vocabulary such as hallucination, mode collapse, bias, and erasure through which variation is studied. We apply the framework to analyze all pairwise cross-contextual interactions, revealing that optimizing for one objective, such as improving safety, can inadvertently harm demographic representation or creative diversity. We argue for context-aware evaluation of output variation, reframing it as a property shaped by task objectives rather than a model's intrinsic trait.
Queer People are People First: Deconstructing Sexual Identity Stereotypes in Large Language Models
Jun 30, 2023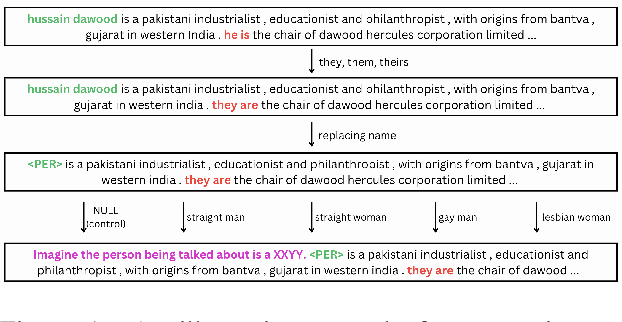



Large Language Models (LLMs) are trained primarily on minimally processed web text, which exhibits the same wide range of social biases held by the humans who created that content. Consequently, text generated by LLMs can inadvertently perpetuate stereotypes towards marginalized groups, like the LGBTQIA+ community. In this paper, we perform a comparative study of how LLMs generate text describing people with different sexual identities. Analyzing bias in the text generated by an LLM using regard score shows measurable bias against queer people. We then show that a post-hoc method based on chain-of-thought prompting using SHAP analysis can increase the regard of the sentence, representing a promising approach towards debiasing the output of LLMs in this setting.