 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Encode Knowledge of Linguistic Constraint Violations?
May 14, 2026Large Language Models (LLMs) achieve strong linguistic performance, yet their internal mechanisms for producing these predictions remain unclear. We investigate the hypothesis that LLMs encode representations of linguistic constraint violations within their parameters, which are selectively activated when processing ungrammatical sentences. To test this, we use sparse autoencoders to decompose polysemantic activations into sparse, monosemantic features and recover candidates for violation-related features. We introduce a sensitivity score for identifying features that are preferentially activated on constraint-violated versus well-formed inputs, enabling unsupervised detection of potential violation-specific features. We further propose a conjunctive falsification framework with three criteria evaluated jointly. Overall, the results are negative in two respects: (1) the falsification criteria are not jointly satisfied across linguistic phenomena, and (2) no features are consistently shared across all categories. While some phenomena show partial evidence of selective causal structure, the overall pattern provides limited support for a unified set of grammatical violation detectors in current LMs.
HighRES: Highlight-based Reference-less Evaluation of Summarization
Jun 04, 2019
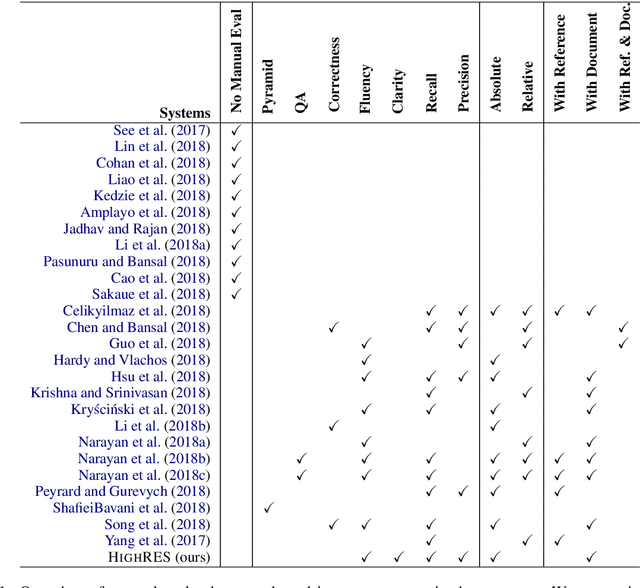


There has been substantial progress in summarization research enabled by the availability of novel, often large-scale, datasets and recent advances on neural network-based approaches. However, manual evaluation of the system generated summaries is inconsistent due to the difficulty the task poses to human non-expert readers. To address this issue, we propose a novel approach for manual evaluation, Highlight-based Reference-less Evaluation of Summarization (HighRES), in which summaries are assessed by multiple annotators against the source document via manually highlighted salient content in the latter. Thus summary assessment on the source document by human judges is facilitated, while the highlights can be used for evaluating multiple systems. To validate our approach we employ crowd-workers to augment with highlights a recently proposed dataset and compare two state-of-the-art systems. We demonstrate that HighRES improves inter-annotator agreement in comparison to using the source document directly, while they help emphasize differences among systems that would be ignored under other evaluation approaches.
Guided Neural Language Generation for Abstractive Summarization using Abstract Meaning Representation
Aug 28, 2018
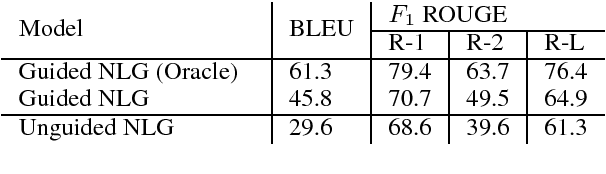
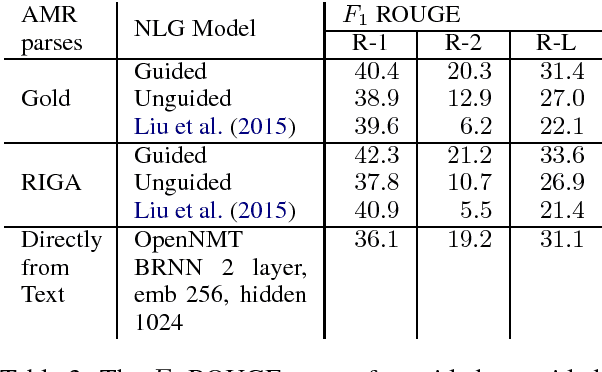

Recent work on abstractive summarization has made progress with neural encoder-decoder architectures. However, such models are often challenged due to their lack of explicit semantic modeling of the source document and its summary. In this paper, we extend previous work on abstractive summarization using Abstract Meaning Representation (AMR) with a neural language generation stage which we guide using the source document. We demonstrate that this guidance improves summarization results by 7.4 and 10.5 points in ROUGE-2 using gold standard AMR parses and parses obtained from an off-the-shelf parser respectively. We also find that the summarization performance using the latter is 2 ROUGE-2 points higher than that of a well-established neural encoder-decoder approach trained on a larger dataset. Code is available at \url{https://github.com/sheffieldnlp/AMR2Text-summ}