 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowW2N: Whispered-to-Normal Speech Conversion via Flow-Matching
Mar 04, 2026Whispered-to-normal (W2N) speech conversion aims to reconstruct missing phonation from whispered input while preserving content and speaker identity. This task is challenging due to temporal misalignment between whisper and voiced recordings and lack of paired data. We propose FlowW2N, a conditional flow matching approach that trains exclusively on synthetic, time-aligned whisper-normal pairs and conditions on domain-invariant features. We exploit high-level ASR embeddings that exhibits strong invariance between synthetic and real whispered speech, enabling generalization to real whispers despite never observing it during training. We verify this invariance across ASR layers and propose a selection criterion optimizing content informativeness and cross-domain invariance. Our method achieves SOTA intelligibility on the CHAINS and wTIMIT datasets, reducing Word Error Rate by 26-46% relative to prior work while using only 10 steps at inference and requiring no real paired data.
Instance-level loss based multiple-instance learning for acoustic scene classification
Mar 16, 2022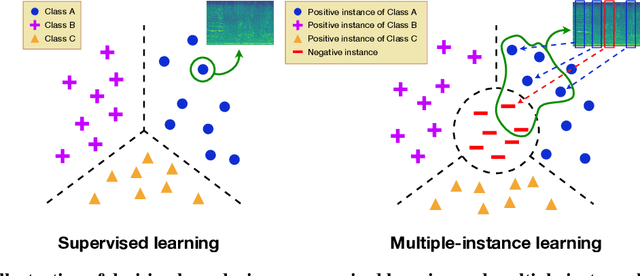


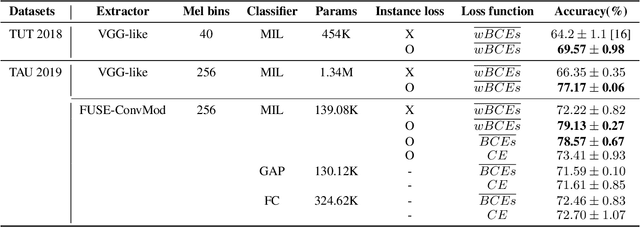
In acoustic scene classification (ASC) task, an acoustic scene consists of diverse attributes and is inferred by identifying combinations of some distinct attributes among them. This study aims to extract and cluster these attributes effectively using a multiple-instance learning (MIL) framework for ASC. MIL, known as one of the weakly supervised learning methods, is a way to extract instances from input data and infer a scene corresponding to the input data with those unlabeled instances. We develop the MIL framework more suitable for ASC systems, adopting instance-level labels and instance-level loss, which are effective in extracting and clustering instances. As a result, the witness rate increases significantly compared to the framework without instance-level loss and labels. Also in several MIL-based ASC systems, the classification accuracy improves by about 5 to 11% than without instance-level loss. In addition, we designed a fully separated convolutional module which is a low-complexity neural network consisting of pointwise, frequency-sided depthwise, and temporal-sided depthwise convolutional filters. Considering both complexity and performance, our proposed system is more practical compared to previous systems on the DCASE 2019 challenge task 1-A leader board. We surpassed the third-place model by achieving a performance of 82.3\% with only the model complexity of 417K, which is at least 40 times fewer than other systems.