 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied AI-Driven Operation of Smart Cities: A Concise Review
Aug 22, 2021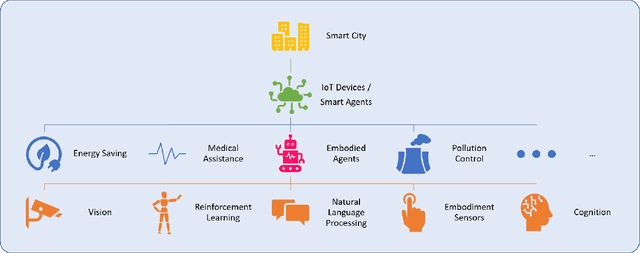
A smart city can be seen as a framework, comprised of Information and Communication Technologies (ICT). An intelligent network of connected devices that collect data with their sensors and transmit them using cloud technologies in order to communicate with other assets in the ecosystem plays a pivotal role in this framework. Maximizing the quality of life of citizens, making better use of resources, cutting costs, and improving sustainability are the ultimate goals that a smart city is after. Hence, data collected from connected devices will continuously get thoroughly analyzed to gain better insights into the services that are being offered across the city; with this goal in mind that they can be used to make the whole system more efficient. Robots and physical machines are inseparable parts of a smart city. Embodied AI is the field of study that takes a deeper look into these and explores how they can fit into real-world environments. It focuses on learning through interaction with the surrounding environment, as opposed to Internet AI which tries to learn from static datasets. Embodied AI aims to train an agent that can See (Computer Vision), Talk (NLP), Navigate and Interact with its environment (Reinforcement Learning), and Reason (General Intelligence), all at the same time. Autonomous driving cars and personal companions are some of the examples that benefit from Embodied AI nowadays. In this paper, we attempt to do a concise review of this field. We will go through its definitions, its characteristics, and its current achievements along with different algorithms, approaches, and solutions that are being used in different components of it (e.g. Vision, NLP, RL). We will then explore all the available simulators and 3D interactable databases that will make the research in this area feasible. Finally, we will address its challenges and identify its potentials for future research.
DRDrV3: Complete Lesion Detection in Fundus Images Using Mask R-CNN, Transfer Learning, and LSTM
Aug 18, 2021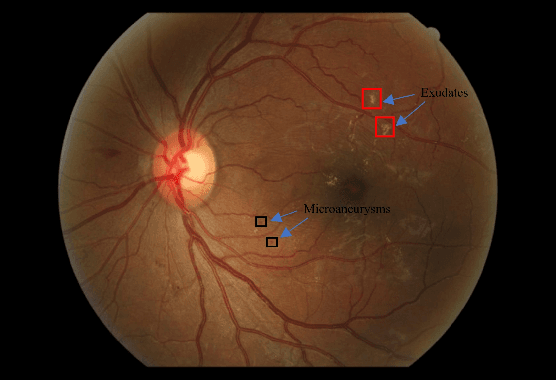

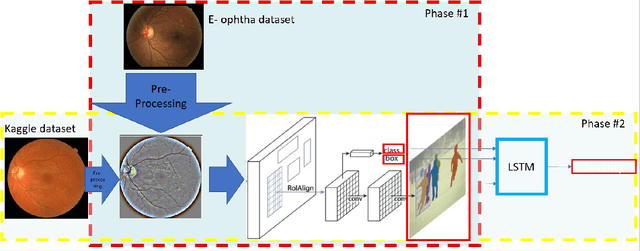

Medical Imaging is one of the growing fields in the world of computer vision. In this study, we aim to address the Diabetic Retinopathy (DR) problem as one of the open challenges in medical imaging. In this research, we propose a new lesion detection architecture, comprising of two sub-modules, which is an optimal solution to detect and find not only the type of lesions caused by DR, their corresponding bounding boxes, and their masks; but also the severity level of the overall case. Aside from traditional accuracy, we also use two popular evaluation criteria to evaluate the outputs of our models, which are intersection over union (IOU) and mean average precision (mAP). We hypothesize that this new solution enables specialists to detect lesions with high confidence and estimate the severity of the damage with high accuracy.
Sarcasm Detection: A Comparative Study
Jul 07, 2021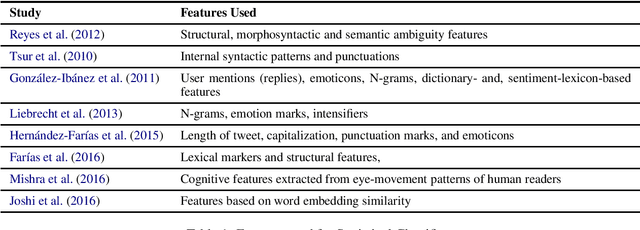
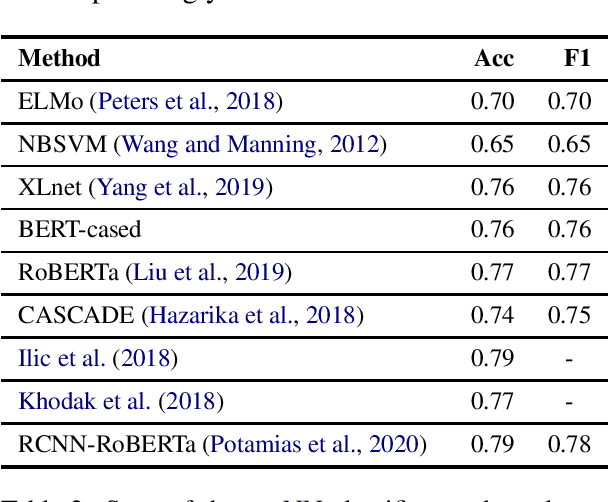
Sarcasm detection is the task of identifying irony containing utterances in sentiment-bearing text. However, the figurative and creative nature of sarcasm poses a great challenge for affective computing systems performing sentiment analysis. This article compiles and reviews the salient work in the literature of automatic sarcasm detection. Thus far, three main paradigm shifts have occurred in the way researchers have approached this task: 1) semi-supervised pattern extraction to identify implicit sentiment, 2) use of hashtag-based supervision, and 3) incorporation of context beyond target text. In this article, we provide a comprehensive review of the datasets, approaches, trends, and issues in sarcasm and irony detection.
Automatic Generation of Descriptive Titles for Video Clips Using Deep Learning
Apr 07, 2021


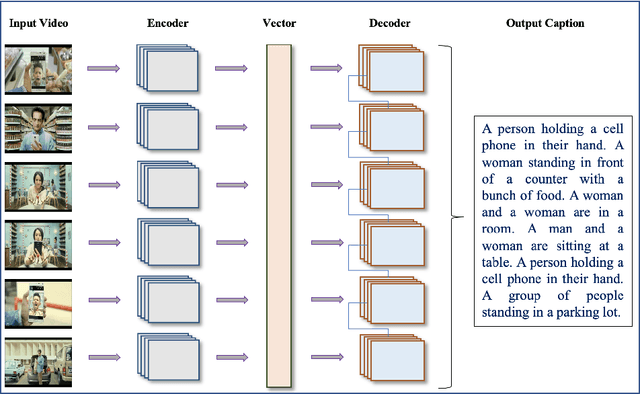
Over the last decade, the use of Deep Learning in many applications produced results that are comparable to and in some cases surpassing human expert performance. The application domains include diagnosing diseases, finance, agriculture, search engines, robot vision, and many others. In this paper, we are proposing an architecture that utilizes image/video captioning methods and Natural Language Processing systems to generate a title and a concise abstract for a video. Such a system can potentially be utilized in many application domains, including, the cinema industry, video search engines, security surveillance, video databases/warehouses, data centers, and others. The proposed system functions and operates as followed: it reads a video; representative image frames are identified and selected; the image frames are captioned; NLP is applied to all generated captions together with text summarization; and finally, a title and an abstract are generated for the video. All functions are performed automatically. Preliminary results are provided in this paper using publicly available datasets. This paper is not concerned about the efficiency of the system at the execution time. We hope to be able to address execution efficiency issues in our subsequent publications.
The Use of Video Captioning for Fostering Physical Activity
Apr 07, 2021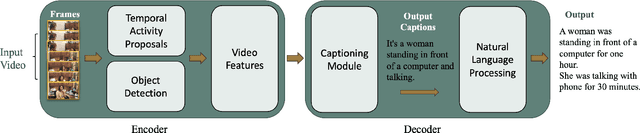
Video Captioning is considered to be one of the most challenging problems in the field of computer vision. Video Captioning involves the combination of different deep learning models to perform object detection, action detection, and localization by processing a sequence of image frames. It is crucial to consider the sequence of actions in a video in order to generate a meaningful description of the overall action event. A reliable, accurate, and real-time video captioning method can be used in many applications. However, this paper focuses on one application: video captioning for fostering and facilitating physical activities. In broad terms, the work can be considered to be assistive technology. Lack of physical activity appears to be increasingly widespread in many nations due to many factors, the most important being the convenience that technology has provided in workplaces. The adopted sedentary lifestyle is becoming a significant public health issue. Therefore, it is essential to incorporate more physical movements into our daily lives. Tracking one's daily physical activities would offer a base for comparison with activities performed in subsequent days. With the above in mind, this paper proposes a video captioning framework that aims to describe the activities in a video and estimate a person's daily physical activity level. This framework could potentially help people trace their daily movements to reduce an inactive lifestyle's health risks. The work presented in this paper is still in its infancy. The initial steps of the application are outlined in this paper. Based on our preliminary research, this project has great merit.
A Concise Review of Transfer Learning
Apr 05, 2021The availability of abundant labeled data in recent years led the researchers to introduce a methodology called transfer learning, which utilizes existing data in situations where there are difficulties in collecting new annotated data. Transfer learning aims to boost the performance of a target learner by applying another related source data. In contrast to the traditional machine learning and data mining techniques, which assume that the training and testing data lie from the same feature space and distribution, transfer learning can handle situations where there is a discrepancy between domains and distributions. These characteristics give the model the potential to utilize the available related source data and extend the underlying knowledge to the target task achieving better performance. This survey paper aims to give a concise review of traditional and current transfer learning settings, existing challenges, and related approaches.
Malware Detection using Artificial Bee Colony Algorithm
Dec 01, 2020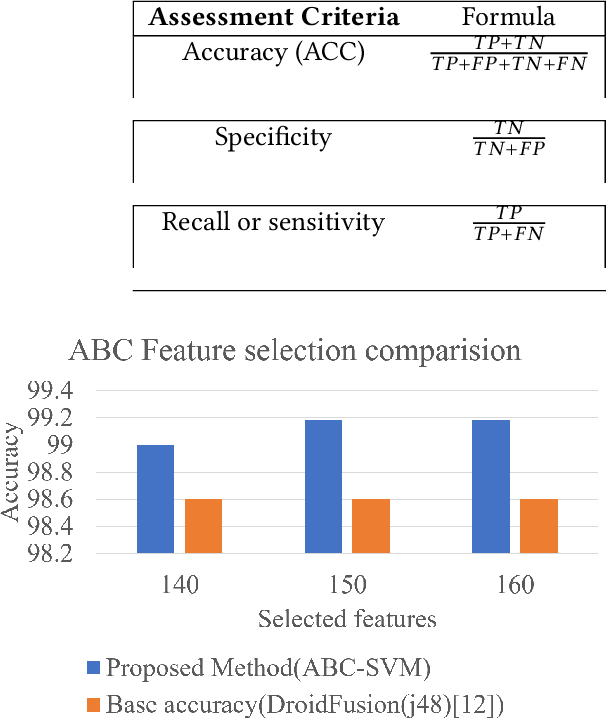

Malware detection has become a challenging task due to the increase in the number of malware families. Universal malware detection algorithms that can detect all the malware families are needed to make the whole process feasible. However, the more universal an algorithm is, the higher number of feature dimensions it needs to work with, and that inevitably causes the emerging problem of Curse of Dimensionality (CoD). Besides, it is also difficult to make this solution work due to the real-time behavior of malware analysis. In this paper, we address this problem and aim to propose a feature selection based malware detection algorithm using an evolutionary algorithm that is referred to as Artificial Bee Colony (ABC). The proposed algorithm enables researchers to decrease the feature dimension and as a result, boost the process of malware detection. The experimental results reveal that the proposed method outperforms the state-of-the-art.
DRDr II: Detecting the Severity Level of Diabetic Retinopathy Using Mask RCNN and Transfer Learning
Nov 30, 2020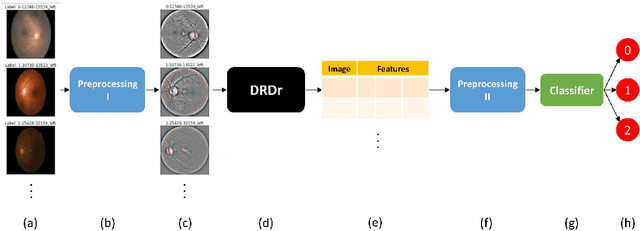
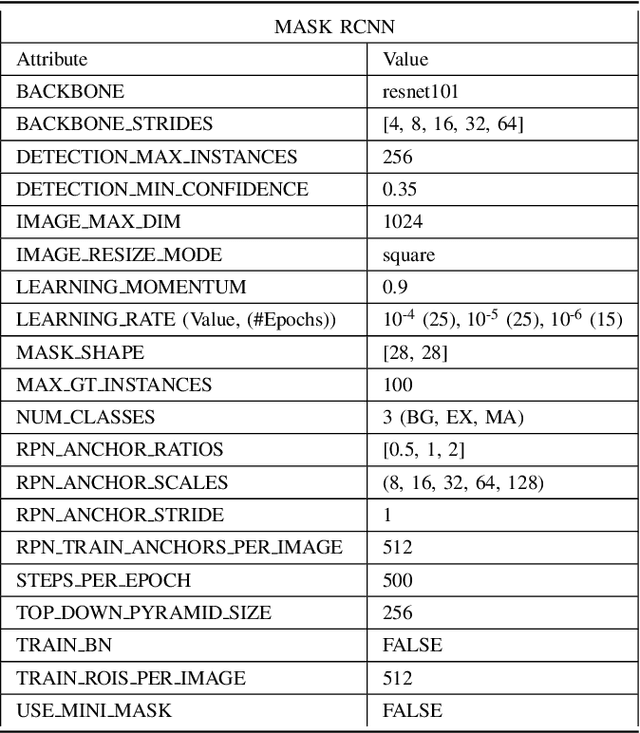
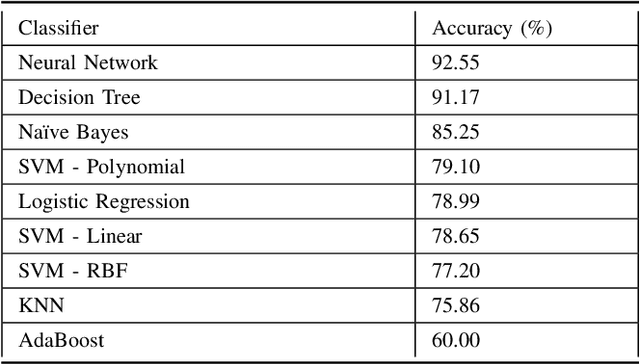
DRDr II is a hybrid of machine learning and deep learning worlds. It builds on the successes of its antecedent, namely, DRDr, that was trained to detect, locate, and create segmentation masks for two types of lesions (exudates and microaneurysms) that can be found in the eyes of the Diabetic Retinopathy (DR) patients; and uses the entire model as a solid feature extractor in the core of its pipeline to detect the severity level of the DR cases. We employ a big dataset with over 35 thousand fundus images collected from around the globe and after 2 phases of preprocessing alongside feature extraction, we succeed in predicting the correct severity levels with over 92% accuracy.
A Brief Review of Domain Adaptation
Oct 07, 2020Classical machine learning assumes that the training and test sets come from the same distributions. Therefore, a model learned from the labeled training data is expected to perform well on the test data. However, This assumption may not always hold in real-world applications where the training and the test data fall from different distributions, due to many factors, e.g., collecting the training and test sets from different sources, or having an out-dated training set due to the change of data over time. In this case, there would be a discrepancy across domain distributions, and naively applying the trained model on the new dataset may cause degradation in the performance. Domain adaptation is a sub-field within machine learning that aims to cope with these types of problems by aligning the disparity between domains such that the trained model can be generalized into the domain of interest. This paper focuses on unsupervised domain adaptation, where the labels are only available in the source domain. It addresses the categorization of domain adaptation from different viewpoints. Besides, It presents some successful shallow and deep domain adaptation approaches that aim to deal with domain adaptation problems.
DeepMSRF: A novel Deep Multimodal Speaker Recognition framework with Feature selection
Jul 21, 2020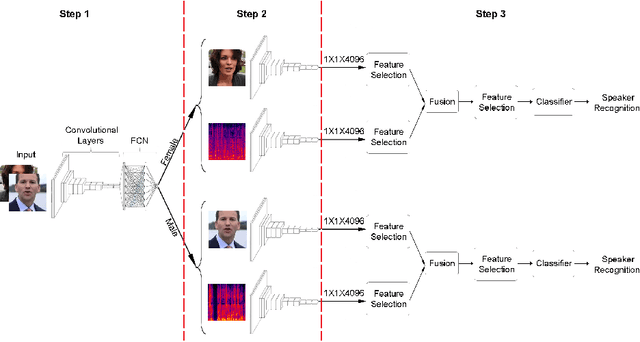
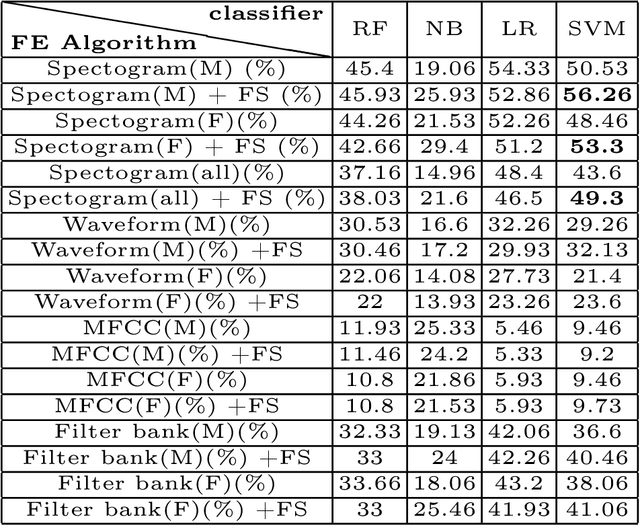
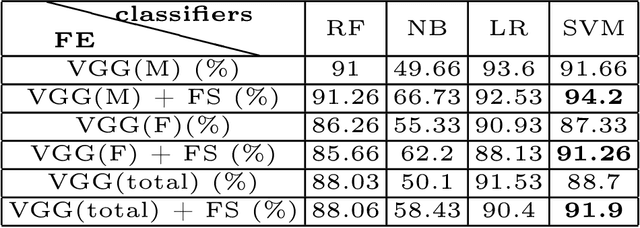
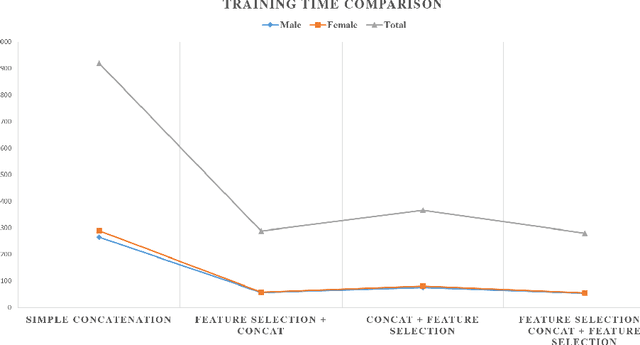
For recognizing speakers in video streams, significant research studies have been made to obtain a rich machine learning model by extracting high-level speaker's features such as facial expression, emotion, and gender. However, generating such a model is not feasible by using only single modality feature extractors that exploit either audio signals or image frames, extracted from video streams. In this paper, we address this problem from a different perspective and propose an unprecedented multimodality data fusion framework called DeepMSRF, Deep Multimodal Speaker Recognition with Feature selection. We execute DeepMSRF by feeding features of the two modalities, namely speakers' audios and face images. DeepMSRF uses a two-stream VGGNET to train on both modalities to reach a comprehensive model capable of accurately recognizing the speaker's identity. We apply DeepMSRF on a subset of VoxCeleb2 dataset with its metadata merged with VGGFace2 dataset. The goal of DeepMSRF is to identify the gender of the speaker first, and further to recognize his or her name for any given video stream. The experimental results illustrate that DeepMSRF outperforms single modality speaker recognition methods with at least 3 percent accuracy.