 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task Grouping and Overlap in Multi-task Learning
Jun 27, 2012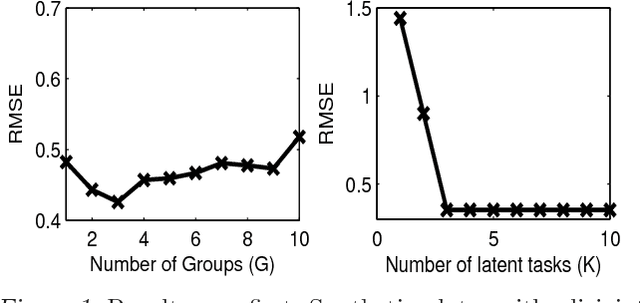

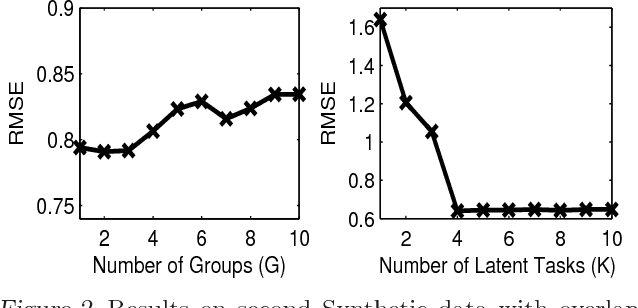

In the paradigm of multi-task learning, mul- tiple related prediction tasks are learned jointly, sharing information across the tasks. We propose a framework for multi-task learn- ing that enables one to selectively share the information across the tasks. We assume that each task parameter vector is a linear combi- nation of a finite number of underlying basis tasks. The coefficients of the linear combina- tion are sparse in nature and the overlap in the sparsity patterns of two tasks controls the amount of sharing across these. Our model is based on on the assumption that task pa- rameters within a group lie in a low dimen- sional subspace but allows the tasks in differ- ent groups to overlap with each other in one or more bases. Experimental results on four datasets show that our approach outperforms competing methods.
A Binary Classification Framework for Two-Stage Multiple Kernel Learning
Jun 27, 2012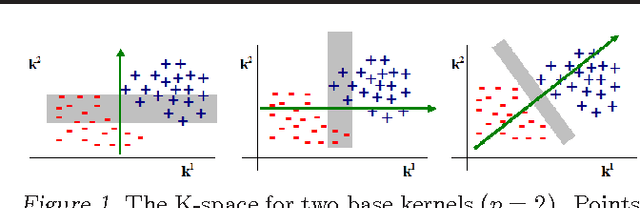
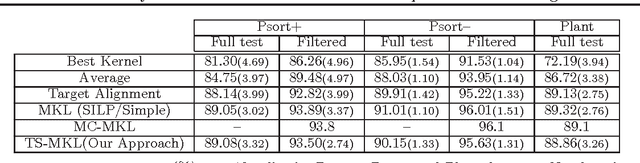
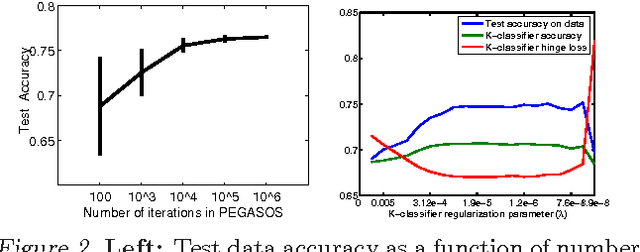
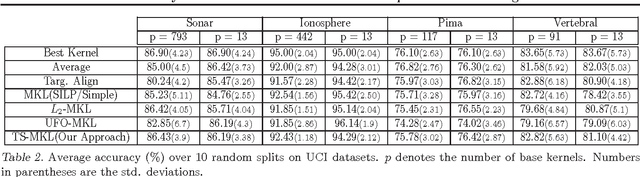
With the advent of kernel methods, automating the task of specifying a suitable kernel has become increasingly important. In this context, the Multiple Kernel Learning (MKL) problem of finding a combination of pre-specified base kernels that is suitable for the task at hand has received significant attention from researchers. In this paper we show that Multiple Kernel Learning can be framed as a standard binary classification problem with additional constraints that ensure the positive definiteness of the learned kernel. Framing MKL in this way has the distinct advantage that it makes it easy to leverage the extensive research in binary classification to develop better performing and more scalable MKL algorithms that are conceptually simpler, and, arguably, more accessible to practitioners. Experiments on nine data sets from different domains show that, despite its simplicity, the proposed technique compares favorably with current leading MKL approaches.
Efficient Protocols for Distributed Classification and Optimization
Apr 16, 2012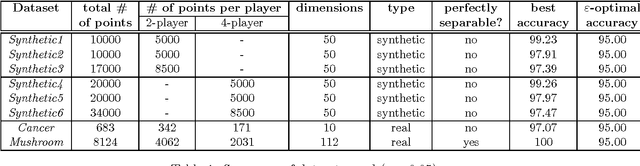
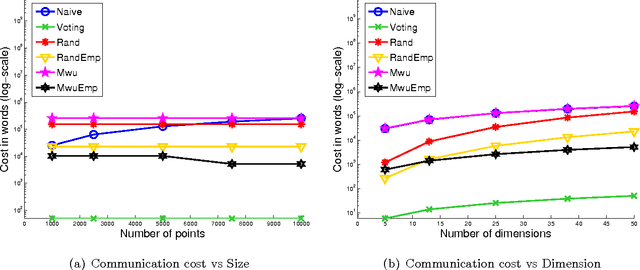
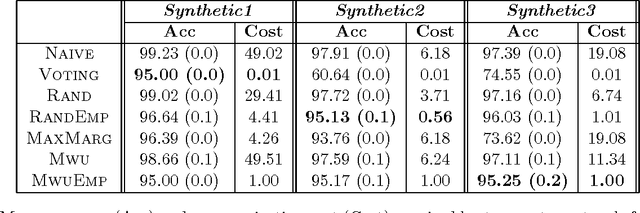
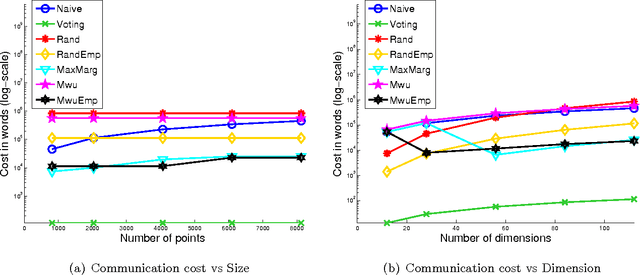
In distributed learning, the goal is to perform a learning task over data distributed across multiple nodes with minimal (expensive) communication. Prior work (Daume III et al., 2012) proposes a general model that bounds the communication required for learning classifiers while allowing for $\eps$ training error on linearly separable data adversarially distributed across nodes. In this work, we develop key improvements and extensions to this basic model. Our first result is a two-party multiplicative-weight-update based protocol that uses $O(d^2 \log{1/\eps})$ words of communication to classify distributed data in arbitrary dimension $d$, $\eps$-optimally. This readily extends to classification over $k$ nodes with $O(kd^2 \log{1/\eps})$ words of communication. Our proposed protocol is simple to implement and is considerably more efficient than baselines compared, as demonstrated by our empirical results. In addition, we illustrate general algorithm design paradigms for doing efficient learning over distributed data. We show how to solve fixed-dimensional and high dimensional linear programming efficiently in a distributed setting where constraints may be distributed across nodes. Since many learning problems can be viewed as convex optimization problems where constraints are generated by individual points, this models many typical distributed learning scenarios. Our techniques make use of a novel connection from multipass streaming, as well as adapting the multiplicative-weight-update framework more generally to a distributed setting. As a consequence, our methods extend to the wide range of problems solvable using these techniques.
Protocols for Learning Classifiers on Distributed Data
Feb 27, 2012
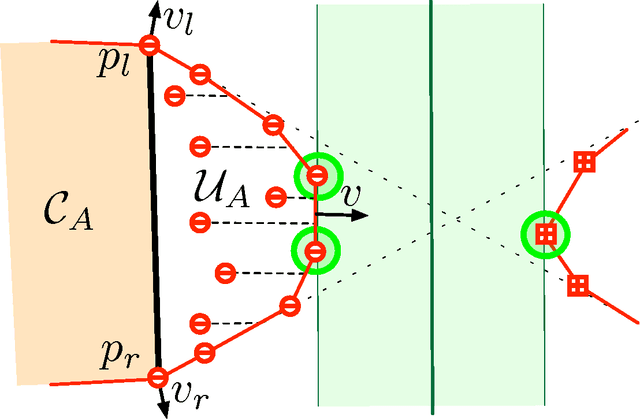
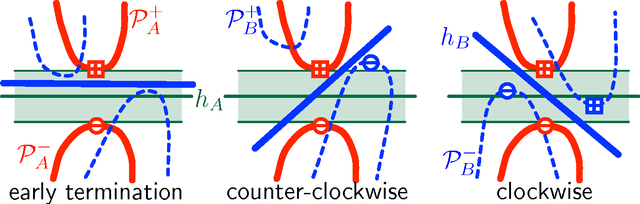
We consider the problem of learning classifiers for labeled data that has been distributed across several nodes. Our goal is to find a single classifier, with small approximation error, across all datasets while minimizing the communication between nodes. This setting models real-world communication bottlenecks in the processing of massive distributed datasets. We present several very general sampling-based solutions as well as some two-way protocols which have a provable exponential speed-up over any one-way protocol. We focus on core problems for noiseless data distributed across two or more nodes. The techniques we introduce are reminiscent of active learning, but rather than actively probing labels, nodes actively communicate with each other, each node simultaneously learning the important data from another node.
A Geometric View of Conjugate Priors
May 01, 2010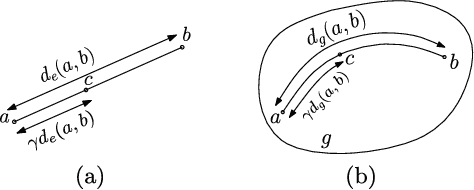
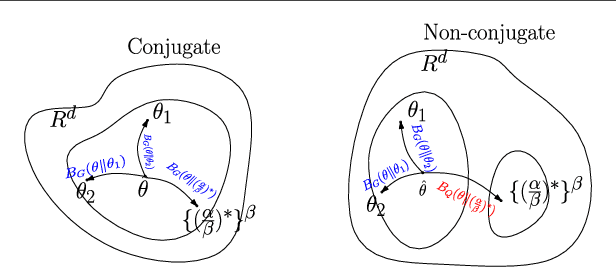
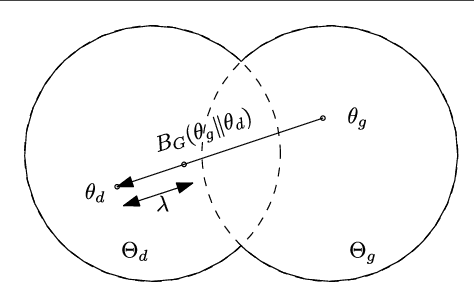
In Bayesian machine learning, conjugate priors are popular, mostly due to mathematical convenience. In this paper, we show that there are deeper reasons for choosing a conjugate prior. Specifically, we formulate the conjugate prior in the form of Bregman divergence and show that it is the inherent geometry of conjugate priors that makes them appropriate and intuitive. This geometric interpretation allows one to view the hyperparameters of conjugate priors as the {\it effective} sample points, thus providing additional intuition. We use this geometric understanding of conjugate priors to derive the hyperparameters and expression of the prior used to couple the generative and discriminative components of a hybrid model for semi-supervised learning.
Exponential Family Hybrid Semi-Supervised Learning
Mar 02, 2010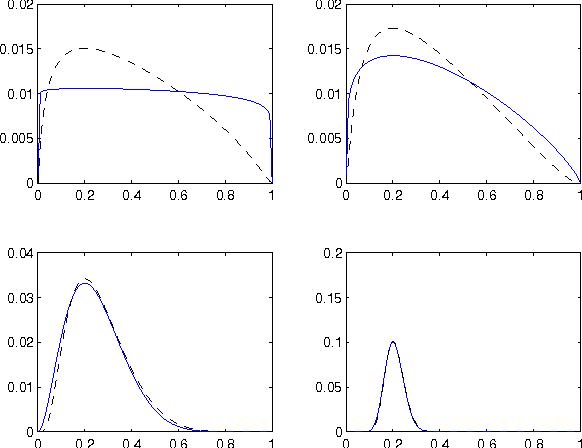
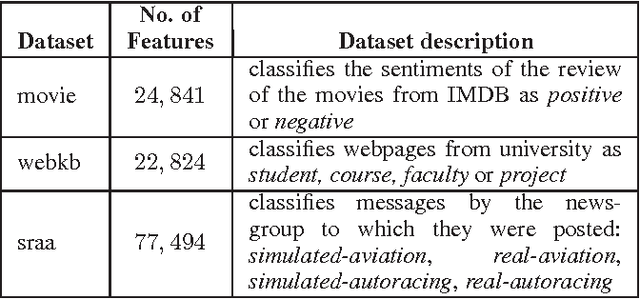
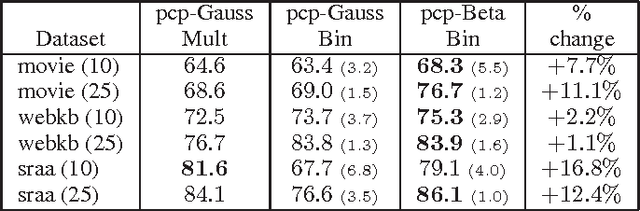
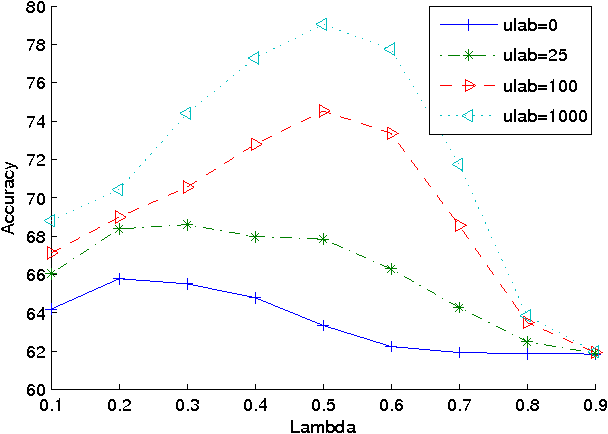
We present an approach to semi-supervised learning based on an exponential family characterization. Our approach generalizes previous work on coupled priors for hybrid generative/discriminative models. Our model is more flexible and natural than previous approaches. Experimental results on several data sets show that our approach also performs better in practice.
* 6 pages, 3 figures