 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving out-of-focus blur from a single image
Aug 28, 2018



Reproducing an all-in-focus image from an image with defocus regions is of practical value in many applications, eg, digital photography, and robotics. Using the output of some existing defocus map estimator, existing approaches first segment a de-focused image into multiple regions blurred by Gaussian kernels with different variance each, and then de-blur each region using the corresponding Gaussian kernel. In this paper, we proposed a blind deconvolution method specifically designed for removing defocus blurring from an image, by providing effective solutions to two critical problems: 1) suppressing the artifacts caused by segmentation error by introducing an additional variable regularized by weighted $\ell_0$-norm; and 2) more accurate defocus kernel estimation using non-parametric symmetry and low-rank based constraints on the kernel. The experiments on real datasets showed the advantages of the proposed method over existing ones, thanks to the effective treatments of the two important issues mentioned above during deconvolution.
Weighted total variation based convex clustering
Aug 28, 2018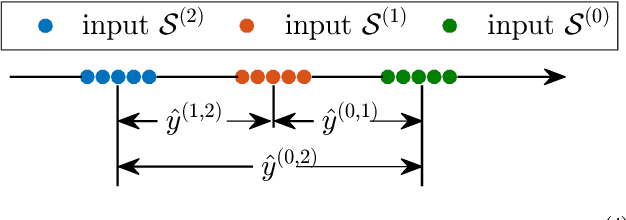
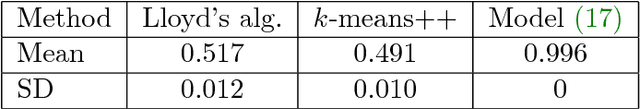
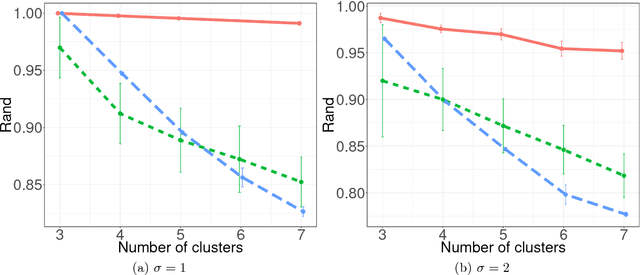
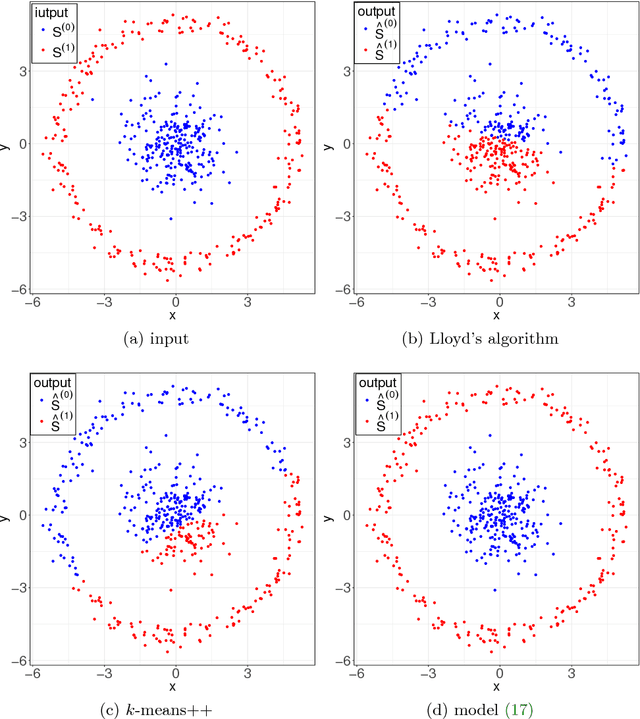
Data clustering is a fundamental problem with a wide range of applications. Standard methods, eg the $k$-means method, usually require solving a non-convex optimization problem. Recently, total variation based convex relaxation to the $k$-means model has emerged as an attractive alternative for data clustering. However, the existing results on its exact clustering property, ie, the condition imposed on data so that the method can provably give correct identification of all cluster memberships, is only applicable to very specific data and is also much more restrictive than that of some other methods. This paper aims at the revisit of total variation based convex clustering, by proposing a weighted sum-of-$\ell_1$-norm relating convex model. Its exact clustering property established in this paper, in both deterministic and probabilistic context, is applicable to general data and is much sharper than the existing results. These results provided good insights to advance the research on convex clustering. Moreover, the experiments also demonstrated that the proposed convex model has better empirical performance when be compared to standard clustering methods, and thus it can see its potential in practice.