 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Circuit Simulation with Memristors: Design and Evaluation Using MemTorch for MNIST and CIFAR
Jul 18, 2024Memristors offer significant advantages as in-memory computing devices due to their non-volatility, low power consumption, and history-dependent conductivity. These attributes are particularly valuable in the realm of neuromorphic circuits for neural networks, which currently face limitations imposed by the Von Neumann architecture and high energy demands. This study evaluates the feasibility of using memristors for in-memory processing by constructing and training three digital convolutional neural networks with the datasets MNIST, CIFAR10 and CIFAR100. Subsequent conversion of these networks into memristive systems was performed using Memtorch. The simulations, conducted under ideal conditions, revealed minimal precision losses of nearly 1% during inference. Additionally, the study analyzed the impact of tile size and memristor-specific non-idealities on performance, highlighting the practical implications of integrating memristors in neuromorphic computing systems. This exploration into memristive neural network applications underscores the potential of Memtorch in advancing neuromorphic architectures.
PLAM: a Posit Logarithm-Approximate Multiplier for Power Efficient Posit-based DNNs
Feb 18, 2021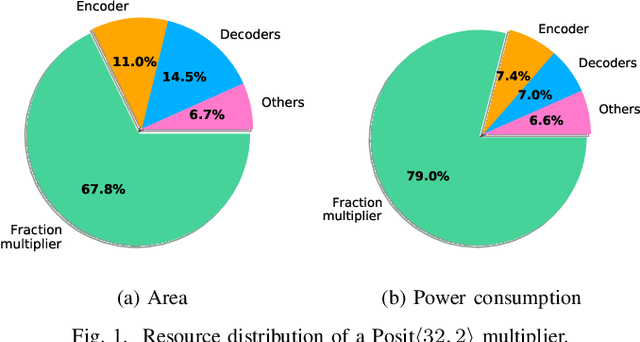

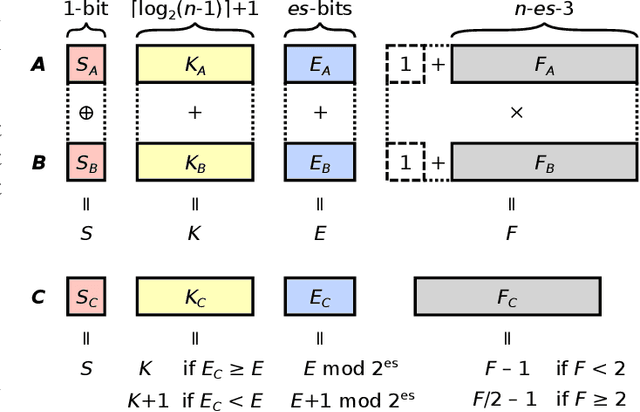
The Posit Number System was introduced in 2017 as a replacement for floating-point numbers. Since then, the community has explored its application in Neural Network related tasks and produced some unit designs which are still far from being competitive with their floating-point counterparts. This paper proposes a Posit Logarithm-Approximate Multiplication (PLAM) scheme to significantly reduce the complexity of posit multipliers, the most power-hungry units within Deep Neural Network architectures. When comparing with state-of-the-art posit multipliers, experiments show that the proposed technique reduces the area, power, and delay of hardware multipliers up to 72.86%, 81.79%, and 17.01%, respectively, without accuracy degradation.
Template-Based Posit Multiplication for Training and Inferring in Neural Networks
Jul 09, 2019
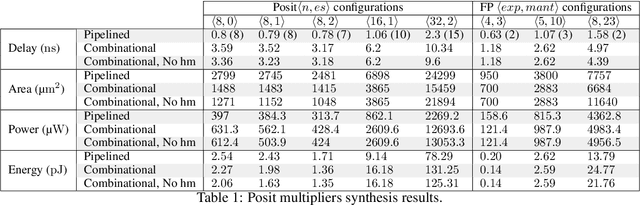

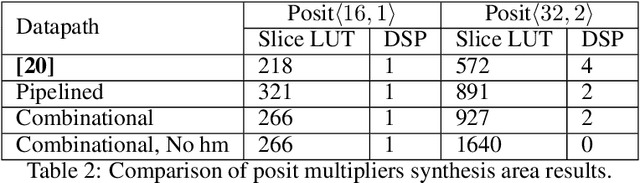
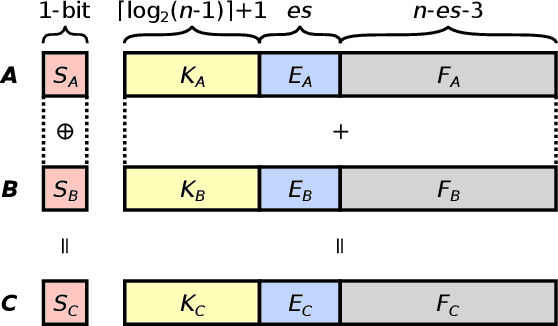
The posit number system is arguably the most promising and discussed topic in Arithmetic nowadays. The recent breakthroughs claimed by the format proposed by John L. Gustafson have put posits in the spotlight. In this work, we first describe an algorithm for multiplying two posit numbers, even when the number of exponent bits is zero. This configuration, scarcely tackled in literature, is particularly interesting because it allows the deployment of a fast sigmoid function. The proposed multiplication algorithm is then integrated as a template into the well-known FloPoCo framework. Synthesis results are shown to compare with the floating point multiplication offered by FloPoCo as well. Second, the performance of posits is studied in the scenario of Neural Networks in both training and inference stages. To the best of our knowledge, this is the first time that training is done with posit format, achieving promising results for a binary classification problem even with reduced posit configurations. In the inference stage, 8-bit posits are as good as floating point when dealing with the MNIST dataset, but lose some accuracy with CIFAR-10.
Dyna-H: a heuristic planning reinforcement learning algorithm applied to role-playing-game strategy decision systems
Jul 30, 2011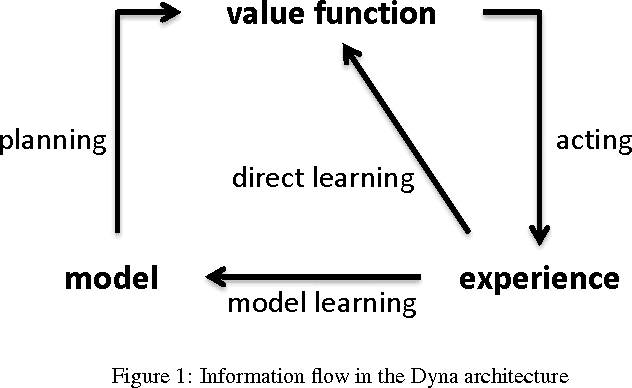
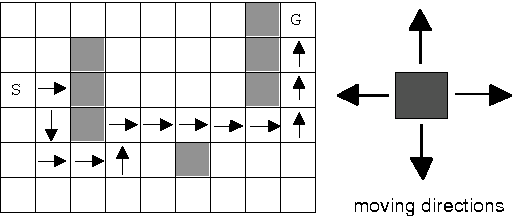

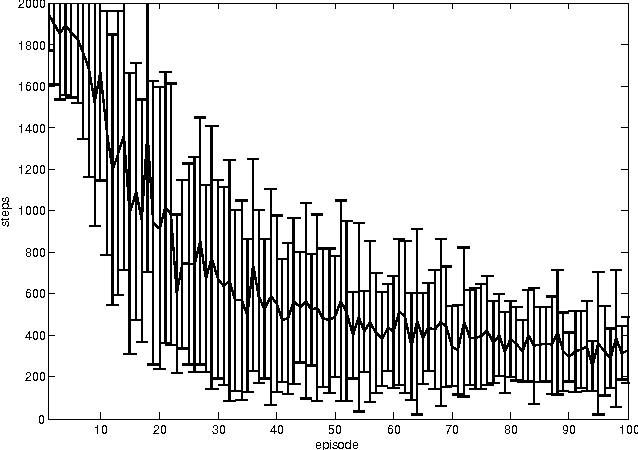
In a Role-Playing Game, finding optimal trajectories is one of the most important tasks. In fact, the strategy decision system becomes a key component of a game engine. Determining the way in which decisions are taken (online, batch or simulated) and the consumed resources in decision making (e.g. execution time, memory) will influence, in mayor degree, the game performance. When classical search algorithms such as A* can be used, they are the very first option. Nevertheless, such methods rely on precise and complete models of the search space, and there are many interesting scenarios where their application is not possible. Then, model free methods for sequential decision making under uncertainty are the best choice. In this paper, we propose a heuristic planning strategy to incorporate the ability of heuristic-search in path-finding into a Dyna agent. The proposed Dyna-H algorithm, as A* does, selects branches more likely to produce outcomes than other branches. Besides, it has the advantages of being a model-free online reinforcement learning algorithm. The proposal was evaluated against the one-step Q-Learning and Dyna-Q algorithms obtaining excellent experimental results: Dyna-H significantly overcomes both methods in all experiments. We suggest also, a functional analogy between the proposed sampling from worst trajectories heuristic and the role of dreams (e.g. nightmares) in human behavior.