 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1D-Convolutional transformer for Parkinson disease diagnosis from gait
Nov 06, 2023



This paper presents an efficient deep neural network model for diagnosing Parkinson's disease from gait. More specifically, we introduce a hybrid ConvNet-Transformer architecture to accurately diagnose the disease by detecting the severity stage. The proposed architecture exploits the strengths of both Convolutional Neural Networks and Transformers in a single end-to-end model, where the former is able to extract relevant local features from Vertical Ground Reaction Force (VGRF) signal, while the latter allows to capture long-term spatio-temporal dependencies in data. In this manner, our hybrid architecture achieves an improved performance compared to using either models individually. Our experimental results show that our approach is effective for detecting the different stages of Parkinson's disease from gait data, with a final accuracy of 88%, outperforming other state-of-the-art AI methods on the Physionet gait dataset. Moreover, our method can be generalized and adapted for other classification problems to jointly address the feature relevance and spatio-temporal dependency problems in 1D signals. Our source code and pre-trained models are publicly available at https://github.com/SafwenNaimi/1D-Convolutional-transformer-for-Parkinson-disease-diagnosis-from-gait.
Automating lichen monitoring in ecological studies using instance segmentation of time-lapse images
Oct 26, 2023Lichens are symbiotic organisms composed of fungi, algae, and/or cyanobacteria that thrive in a variety of environments. They play important roles in carbon and nitrogen cycling, and contribute directly and indirectly to biodiversity. Ecologists typically monitor lichens by using them as indicators to assess air quality and habitat conditions. In particular, epiphytic lichens, which live on trees, are key markers of air quality and environmental health. A new method of monitoring epiphytic lichens involves using time-lapse cameras to gather images of lichen populations. These cameras are used by ecologists in Newfoundland and Labrador to subsequently analyze and manually segment the images to determine lichen thalli condition and change. These methods are time-consuming and susceptible to observer bias. In this work, we aim to automate the monitoring of lichens over extended periods and to estimate their biomass and condition to facilitate the task of ecologists. To accomplish this, our proposed framework uses semantic segmentation with an effective training approach to automate monitoring and biomass estimation of epiphytic lichens on time-lapse images. We show that our method has the potential to significantly improve the accuracy and efficiency of lichen population monitoring, making it a valuable tool for forest ecologists and environmental scientists to evaluate the impact of climate change on Canada's forests. To the best of our knowledge, this is the first time that such an approach has been used to assist ecologists in monitoring and analyzing epiphytic lichens.
HCT: Hybrid Convnet-Transformer for Parkinson's disease detection and severity prediction from gait
Oct 26, 2023



In this paper, we propose a novel deep learning method based on a new Hybrid ConvNet-Transformer architecture to detect and stage Parkinson's disease (PD) from gait data. We adopt a two-step approach by dividing the problem into two sub-problems. Our Hybrid ConvNet-Transformer model first distinguishes healthy versus parkinsonian patients. If the patient is parkinsonian, a multi-class Hybrid ConvNet-Transformer model determines the Hoehn and Yahr (H&Y) score to assess the PD severity stage. Our hybrid architecture exploits the strengths of both Convolutional Neural Networks (ConvNets) and Transformers to accurately detect PD and determine the severity stage. In particular, we take advantage of ConvNets to capture local patterns and correlations in the data, while we exploit Transformers for handling long-term dependencies in the input signal. We show that our hybrid method achieves superior performance when compared to other state-of-the-art methods, with a PD detection accuracy of 97% and a severity staging accuracy of 87%. Our source code is available at: https://github.com/SafwenNaimi
Real-time instance segmentation with polygons using an Intersection-over-Union loss
May 09, 2023Predicting a binary mask for an object is more accurate but also more computationally expensive than a bounding box. Polygonal masks as developed in CenterPoly can be a good compromise. In this paper, we improve over CenterPoly by enhancing the classical regression L1 loss with a novel region-based loss and a novel order loss, as well as with a new training process for the vertices prediction head. Moreover, the previous methods that predict polygonal masks use different coordinate systems, but it is not clear if one is better than another, if we abstract the architecture requirement. We therefore investigate their impact on the prediction. We also use a new evaluation protocol with oracle predictions for the detection head, to further isolate the segmentation process and better compare the polygonal masks with binary masks. Our instance segmentation method is trained and tested with challenging datasets containing urban scenes, with a high density of road users. Experiments show, in particular, that using a combination of a regression loss and a region-based loss allows significant improvements on the Cityscapes and IDD test set compared to CenterPoly. Moreover the inference stage remains fast enough to reach real-time performance with an average of 0.045 s per frame for 2048$\times$1024 images on a single RTX 2070 GPU. The code is available $\href{https://github.com/KatiaJDL/CenterPoly-v2}{\text{here}}$.
VisiTherS: Visible-thermal infrared stereo disparity estimation of human silhouette
Apr 22, 2023This paper presents a novel approach for visible-thermal infrared stereoscopy, focusing on the estimation of disparities of human silhouettes. Visible-thermal infrared stereo poses several challenges, including occlusions and differently textured matching regions in both spectra. Finding matches between two spectra with varying colors, textures, and shapes adds further complexity to the task. To address the aforementioned challenges, this paper proposes a novel approach where a high-resolution convolutional neural network is used to better capture relationships between the two spectra. To do so, a modified HRNet backbone is used for feature extraction. This HRNet backbone is capable of capturing fine details and textures as it extracts features at multiple scales, thereby enabling the utilization of both local and global information. For matching visible and thermal infrared regions, our method extracts features on each patch using two modified HRNet streams. Features from the two streams are then combined for predicting the disparities by concatenation and correlation. Results on public datasets demonstrate the effectiveness of the proposed approach by improving the results by approximately 18 percentage points on the $\leq$ 1 pixel error, highlighting its potential for improving accuracy in this task. The code of VisiTherS is available on GitHub at the following link https://github.com/philippeDG/VisiTherS.
GUILGET: GUI Layout GEneration with Transformer
Apr 18, 2023Sketching out Graphical User Interface (GUI) layout is part of the pipeline of designing a GUI and a crucial task for the success of a software application. Arranging all components inside a GUI layout manually is a time-consuming task. In order to assist designers, we developed a method named GUILGET to automatically generate GUI layouts from positional constraints represented as GUI arrangement graphs (GUI-AGs). The goal is to support the initial step of GUI design by producing realistic and diverse GUI layouts. The existing image layout generation techniques often cannot incorporate GUI design constraints. Thus, GUILGET needs to adapt existing techniques to generate GUI layouts that obey to constraints specific to GUI designs. GUILGET is based on transformers in order to capture the semantic in relationships between elements from GUI-AG. Moreover, the model learns constraints through the minimization of losses responsible for placing each component inside its parent layout, for not letting components overlap if they are inside the same parent, and for component alignment. Our experiments, which are conducted on the CLAY dataset, reveal that our model has the best understanding of relationships from GUI-AG and has the best performances in most of evaluation metrics. Therefore, our work contributes to improved GUI layout generation by proposing a novel method that effectively accounts for the constraints on GUI elements and paves the road for a more efficient GUI design pipeline.
TopTrack: Tracking Objects By Their Top
Apr 12, 2023In recent years, the joint detection-and-tracking paradigm has been a very popular way of tackling the multi-object tracking (MOT) task. Many of the methods following this paradigm use the object center keypoint for detection. However, we argue that the center point is not optimal since it is often not visible in crowded scenarios, which results in many missed detections when the objects are partially occluded. We propose TopTrack, a joint detection-and-tracking method that uses the top of the object as a keypoint for detection instead of the center because it is more often visible. Furthermore, TopTrack processes consecutive frames in separate streams in order to facilitate training. We performed experiments to show that using the object top as a keypoint for detection can reduce the amount of missed detections, which in turn leads to more complete trajectories and less lost trajectories. TopTrack manages to achieve competitive results with other state-of-the-art trackers on two MOT benchmarks.
Video Prediction by Efficient Transformers
Dec 12, 2022Video prediction is a challenging computer vision task that has a wide range of applications. In this work, we present a new family of Transformer-based models for video prediction. Firstly, an efficient local spatial-temporal separation attention mechanism is proposed to reduce the complexity of standard Transformers. Then, a full autoregressive model, a partial autoregressive model and a non-autoregressive model are developed based on the new efficient Transformer. The partial autoregressive model has a similar performance with the full autoregressive model but a faster inference speed. The non-autoregressive model not only achieves a faster inference speed but also mitigates the quality degradation problem of the autoregressive counterparts, but it requires additional parameters and loss function for learning. Given the same attention mechanism, we conducted a comprehensive study to compare the proposed three video prediction variants. Experiments show that the proposed video prediction models are competitive with more complex state-of-the-art convolutional-LSTM based models. The source code is available at https://github.com/XiYe20/VPTR.
Continuous conditional video synthesis by neural processes
Oct 11, 2022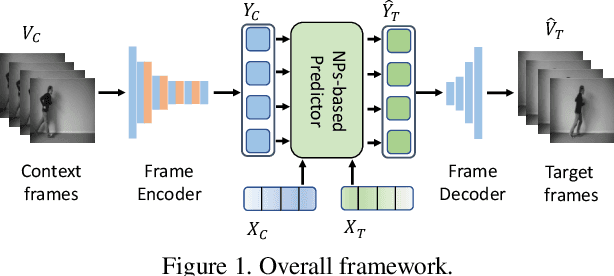
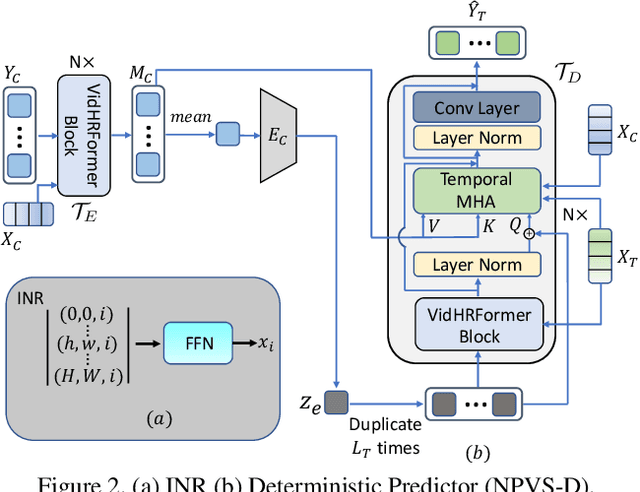

We propose a unified model for multiple conditional video synthesis tasks, including video prediction and video frame interpolation. We show that conditional video synthesis can be formulated as a neural process, which maps input spatio-temporal coordinates to target pixel values given context spatio-temporal coordinates and pixels values. Specifically, we feed an implicit neural representations of coordinates into a Transformer-based non-autoregressive conditional video synthesis model. Our task-specific models outperform previous work for video interpolation on multiple datasets and reach a competitive performance with the state-of-the-art models for video prediction. Importantly, the model is able to interpolate or predict with an arbitrary high frame rate, i.e., continuous synthesis. Our source code is available at \url{https://github.com/NPVS/NPVS}.
Improving tracking with a tracklet associator
Apr 22, 2022
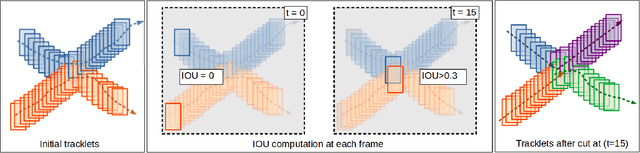
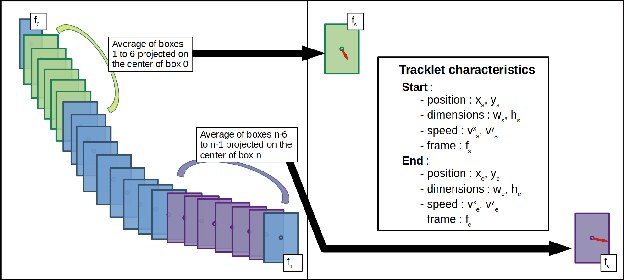
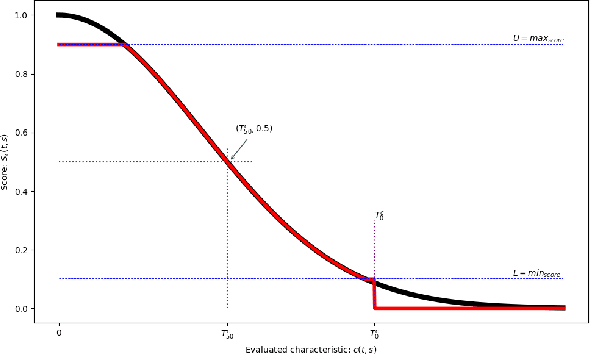
Multiple object tracking (MOT) is a task in computer vision that aims to detect the position of various objects in videos and to associate them to a unique identity. We propose an approach based on Constraint Programming (CP) whose goal is to be grafted to any existing tracker in order to improve its object association results. We developed a modular algorithm divided into three independent phases. The first phase consists in recovering the tracklets provided by a base tracker and to cut them at the places where uncertain associations are spotted, for example, when tracklets overlap, which may cause identity switches. In the second phase, we associate the previously constructed tracklets using a Belief Propagation Constraint Programming algorithm, where we propose various constraints that assign scores to each of the tracklets based on multiple characteristics, such as their dynamics or the distance between them in time and space. Finally, the third phase is a rudimentary interpolation model to fill in the remaining holes in the trajectories we built. Experiments show that our model leads to improvements in the results for all three of the state-of-the-art trackers on which we tested it (3 to 4 points gained on HOTA and IDF1).