 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocQT: Improving Document Forgery Localization Robustness via Diverse JPEG Quantization Tables
May 19, 2026Document manipulation localization models achieve strong performance on public benchmarks yet fail to generalize to operational document workflows. We identify a critical and overlooked source of this gap: the mismatch between the narrow distribution of JPEG quantization tables used during training -restricted to standard libjpeg quality factors -and the heterogeneous compression profiles encountered in real-world insurance document pipelines. To isolate this factor, we conduct a controlled factorial study comparing two architectures with contrasting levels of quantization table awareness -FFDN [2] and Mesorch [20] -each trained under either standard quality factor augmentation (Standard-QT ) or operationally calibrated quantization tables sampled from DocQT, a quantization-table bank derived from a MAIF operational image corpus (Real-QT ), and evaluated under three recompression conditions. Training under Real-QT yields substantial localization gains on DocTamper [15] and significantly reduces the pixel-level false positive rate on authentic operational documents, but only for architectures that explicitly ingest the quantization table as input. The released DocQT quantization-table dataset and compression-reproduction material are directly available at https://github.com/Kyliroco/Improving-Document-Forgery-Localization-Robustness-via-Diverse-JPEG-Quantization-Tables. These results demonstrate that standard quality factor augmentation does not adequately proxy operational compression diversity, and that architectural choices explicitly conditioning on the quantization table provide a meaningful robustness advantage for real-world deployment.
Leveraging Historical Data for High-Dimensional Regression Adjustment, a Composite Covariate Approach
Mar 26, 2021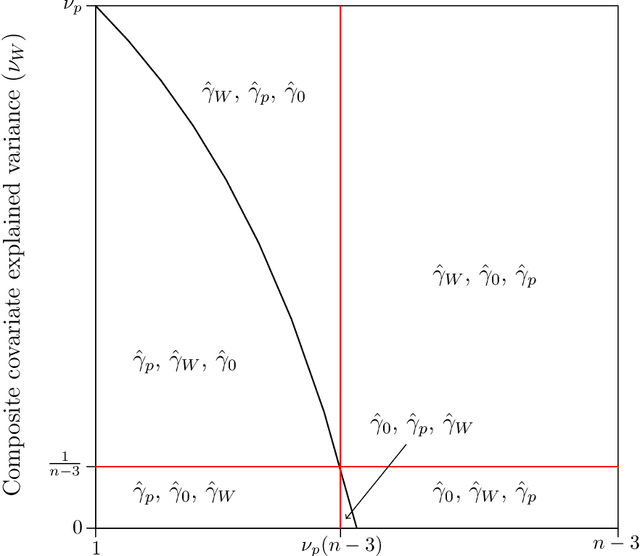
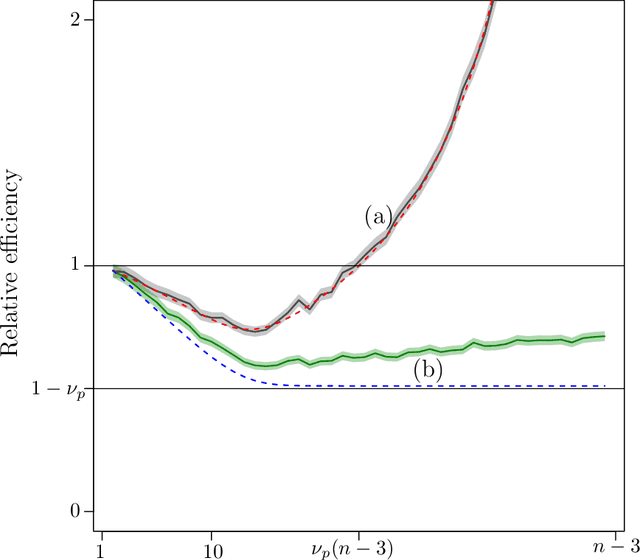
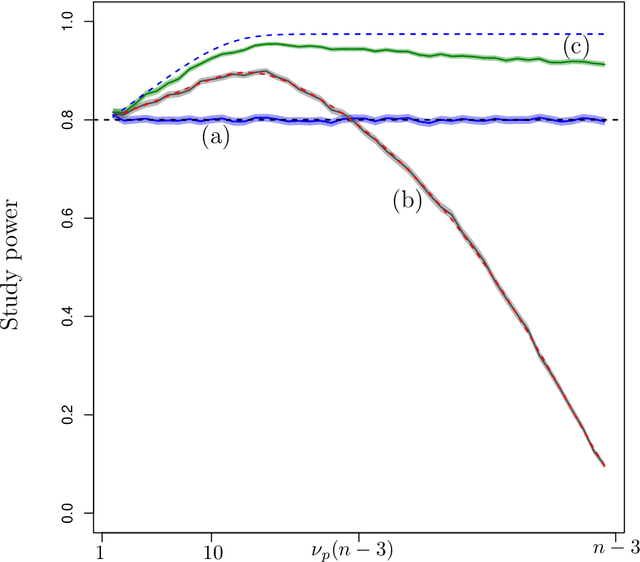
The amount of data collected from patients involved in clinical trials is continuously growing. All patient characteristics are potential covariates that could be used to improve clinical trial analysis and power. However, the restricted number of patients in phases I and II studies limits the possible number of covariates included in the analyses. In this paper, we investigate the cost/benefit ratio of including covariates in the analysis of clinical trials. Within this context, we address the long-running question "What is the optimum number of covariates to include in a clinical trial?" To further improve the cost/benefit ratio of covariates, historical data can be leveraged to pre-specify the covariate weights, which can be viewed as the definition of a new composite covariate. We analyze the use of a composite covariate while estimating the treatment effect in small clinical trials. A composite covariate limits the loss of degrees of freedom and the risk of overfitting.
Evaluate On-the-job Learning Dialogue Systems and a Case Study for Natural Language Understanding
Feb 26, 2021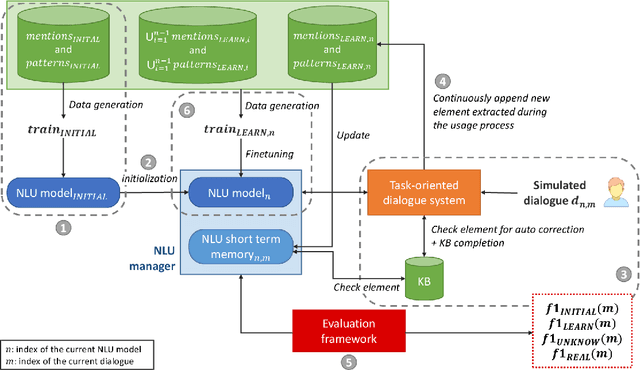

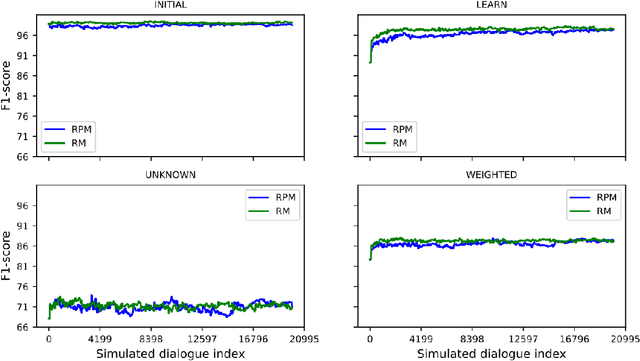
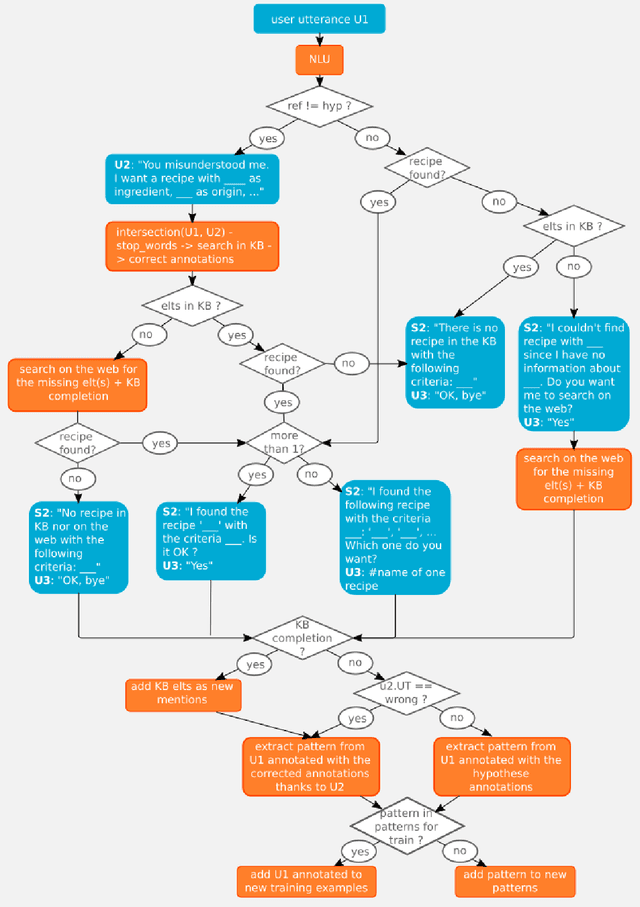
On-the-job learning consists in continuously learning while being used in production, in an open environment, meaning that the system has to deal on its own with situations and elements never seen before. The kind of systems that seem to be especially adapted to on-the-job learning are dialogue systems, since they can take advantage of their interactions with users to collect feedback to adapt and improve their components over time. Some dialogue systems performing on-the-job learning have been built and evaluated but no general methodology has yet been defined. Thus in this paper, we propose a first general methodology for evaluating on-the-job learning dialogue systems. We also describe a task-oriented dialogue system which improves on-the-job its natural language component through its user interactions. We finally evaluate our system with the described methodology.