 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Maximum-Margin Clustering
Feb 06, 2015
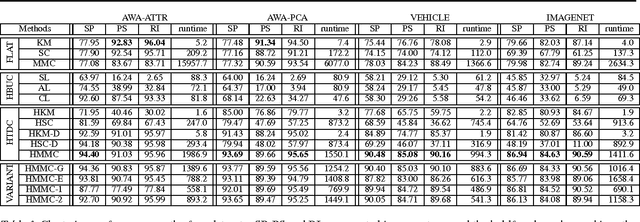
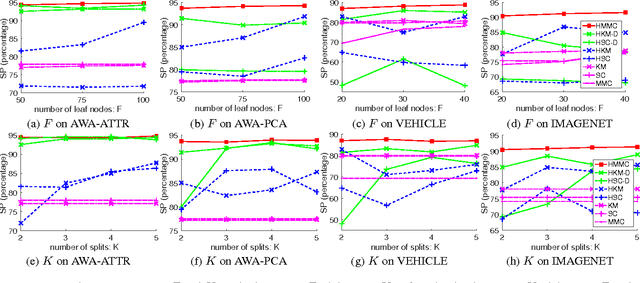
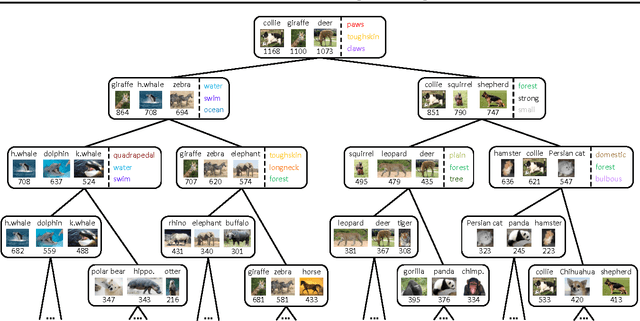
We present a hierarchical maximum-margin clustering method for unsupervised data analysis. Our method extends beyond flat maximum-margin clustering, and performs clustering recursively in a top-down manner. We propose an effective greedy splitting criteria for selecting which cluster to split next, and employ regularizers that enforce feature sharing/competition for capturing data semantics. Experimental results obtained on four standard datasets show that our method outperforms flat and hierarchical clustering baselines, while forming clean and semantically meaningful cluster hierarchies.
Multiple Instance Learning by Discriminative Training of Markov Networks
Sep 26, 2013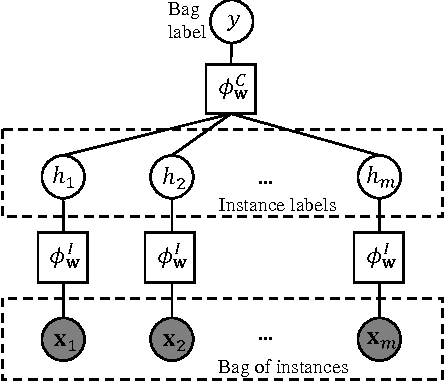
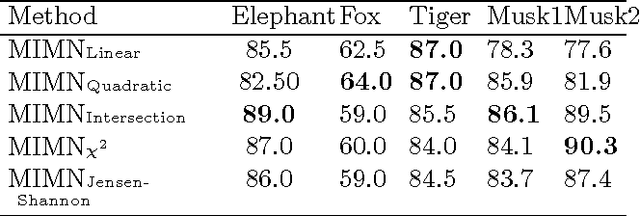
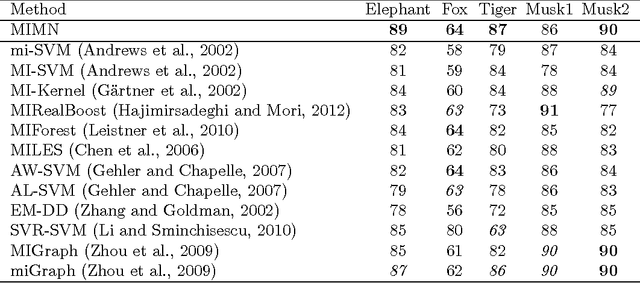
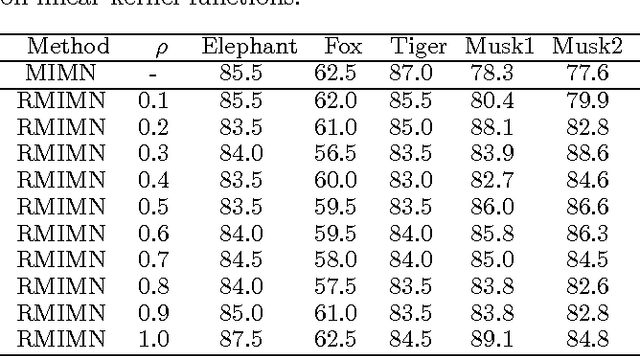
We introduce a graphical framework for multiple instance learning (MIL) based on Markov networks. This framework can be used to model the traditional MIL definition as well as more general MIL definitions. Different levels of ambiguity -- the portion of positive instances in a bag -- can be explored in weakly supervised data. To train these models, we propose a discriminative max-margin learning algorithm leveraging efficient inference for cardinality-based cliques. The efficacy of the proposed framework is evaluated on a variety of data sets. Experimental results verify that encoding or learning the degree of ambiguity can improve classification performance.