 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLSEP: Learning Label Ranks for Multi-label Classification
Dec 08, 2022



Multi-label ranking maps instances to a ranked set of predicted labels from multiple possible classes. The ranking approach for multi-label learning problems received attention for its success in multi-label classification, with one of the well-known approaches being pairwise label ranking. However, most existing methods assume that only partial information about the preference relation is known, which is inferred from the partition of labels into a positive and negative set, then treat labels with equal importance. In this paper, we focus on the unique challenge of ranking when the order of the true label set is provided. We propose a novel dedicated loss function to optimize models by incorporating penalties for incorrectly ranked pairs, and make use of the ranking information present in the input. Our method achieves the best reported performance measures on both synthetic and real world ranked datasets and shows improvements on overall ranking of labels. Our experimental results demonstrate that our approach is generalizable to a variety of multi-label classification and ranking tasks, while revealing a calibration towards a certain ranking ordering.
Symmetry and Variance: Generative Parametric Modelling of Historical Brick Wall Patterns
Oct 23, 2022



This study integrates artificial intelligence and computational design tools to extract information from architectural heritage. Photogrammetry-based point cloud models of brick walls from the Anatolian Seljuk period are analysed in terms of the interrelated units of construction, simultaneously considering both the inherent symmetries and irregularities. The real-world data is used as input for acquiring the stochastic parameters of spatial relations and a set of parametric shape rules to recreate designs of existing and hypothetical brick walls within the style. The motivation is to be able to generate large data sets for machine learning of the style and to devise procedures for robotic production of such designs with repetitive units.
* 10 pages, 7 Figures. This paper is published at "Symmetry: Art and Science | 12th SIS-Symmetry Congress"
How to Combine Variational Bayesian Networks in Federated Learning
Jun 22, 2022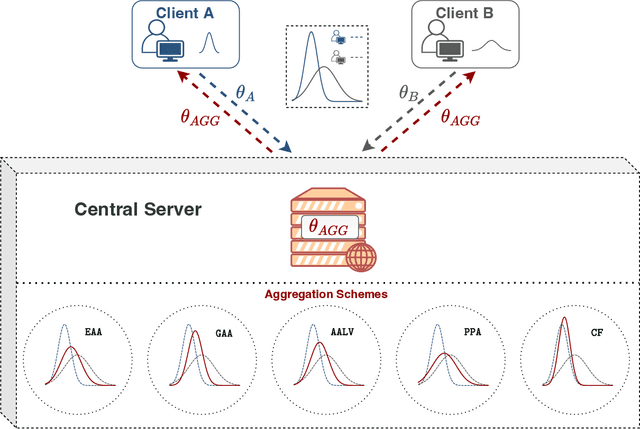
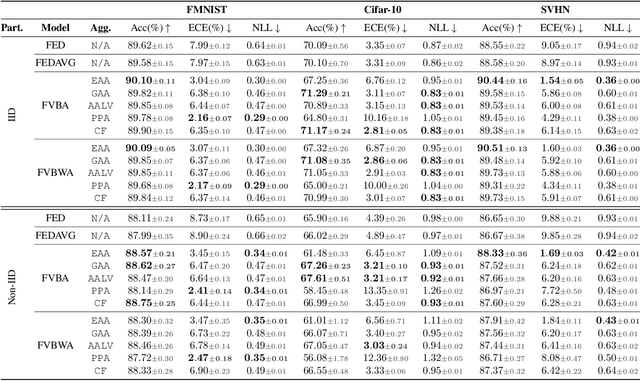

Federated Learning enables multiple data centers to train a central model collaboratively without exposing any confidential data. Even though deterministic models are capable of performing high prediction accuracy, their lack of calibration and capability to quantify uncertainty is problematic for safety-critical applications. Different from deterministic models, probabilistic models such as Bayesian neural networks are relatively well-calibrated and able to quantify uncertainty alongside their competitive prediction accuracy. Both of the approaches appear in the federated learning framework; however, the aggregation scheme of deterministic models cannot be directly applied to probabilistic models since weights correspond to distributions instead of point estimates. In this work, we study the effects of various aggregation schemes for variational Bayesian neural networks. With empirical results on three image classification datasets, we observe that the degree of spread for an aggregated distribution is a significant factor in the learning process. Hence, we present an investigation on the question of how to combine variational Bayesian networks in federated learning, while providing benchmarks for different aggregation settings.
Continual Learning of Multi-modal Dynamics with External Memory
Mar 02, 2022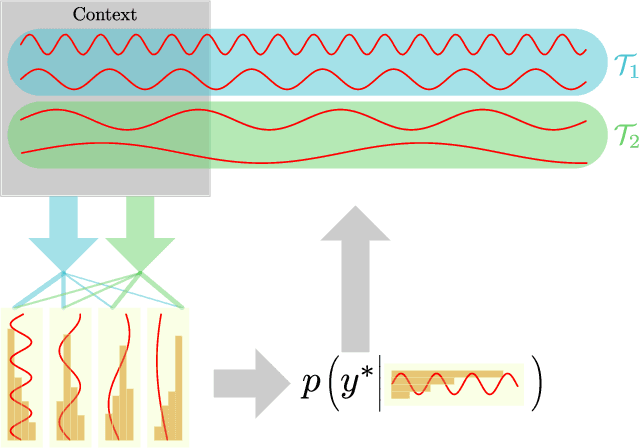
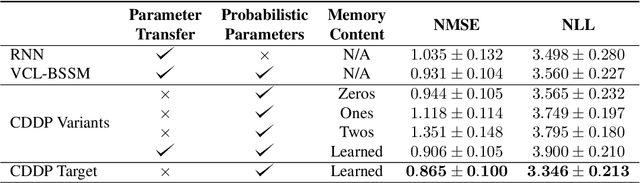
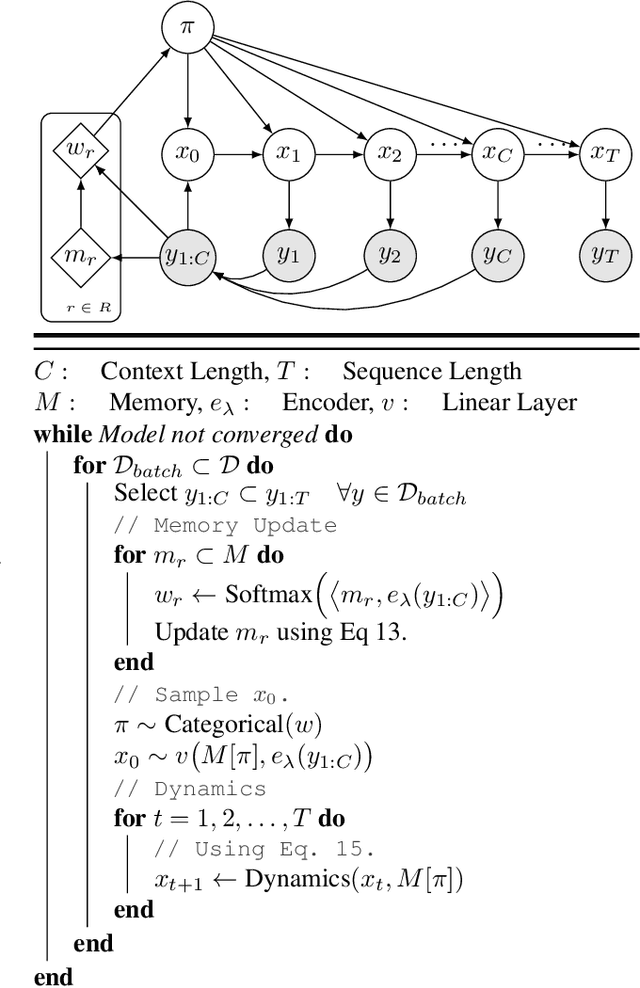
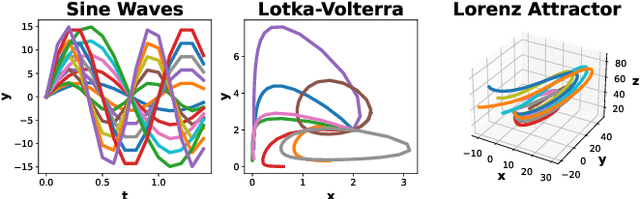
We study the problem of fitting a model to a dynamical environment when new modes of behavior emerge sequentially. The learning model is aware when a new mode appears, but it does not have access to the true modes of individual training sequences. We devise a novel continual learning method that maintains a descriptor of the mode of an encountered sequence in a neural episodic memory. We employ a Dirichlet Process prior on the attention weights of the memory to foster efficient storage of the mode descriptors. Our method performs continual learning by transferring knowledge across tasks by retrieving the descriptors of similar modes of past tasks to the mode of a current sequence and feeding this descriptor into its transition kernel as control input. We observe the continual learning performance of our method to compare favorably to the mainstream parameter transfer approach.
Detecting Visual Design Principles in Art and Architecture through Deep Convolutional Neural Networks
Aug 09, 2021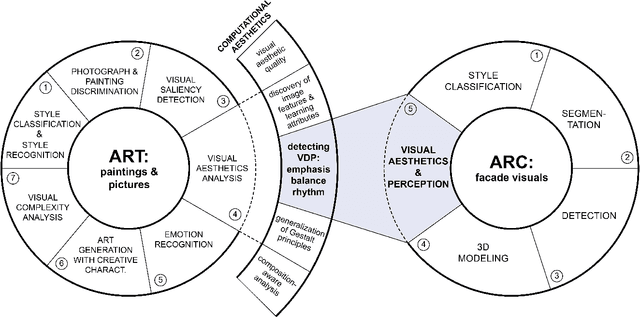


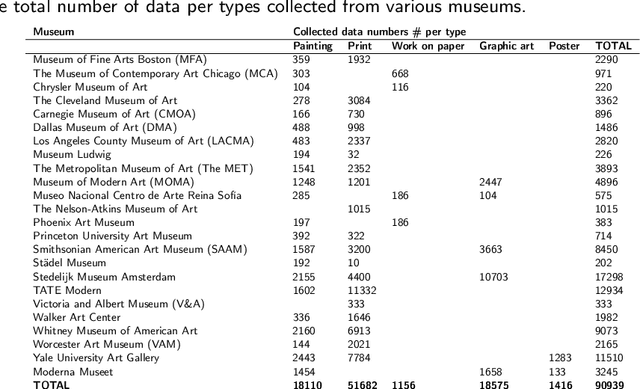
Visual design is associated with the use of some basic design elements and principles. Those are applied by the designers in the various disciplines for aesthetic purposes, relying on an intuitive and subjective process. Thus, numerical analysis of design visuals and disclosure of the aesthetic value embedded in them are considered as hard. However, it has become possible with emerging artificial intelligence technologies. This research aims at a neural network model, which recognizes and classifies the design principles over different domains. The domains include artwork produced since the late 20th century; professional photos; and facade pictures of contemporary buildings. The data collection and curation processes, including the production of computationally-based synthetic dataset, is genuine. The proposed model learns from the knowledge of myriads of original designs, by capturing the underlying shared patterns. It is expected to consolidate design processes by providing an aesthetic evaluation of the visual compositions with objectivity.
Uncertainty-Based Dynamic Graph Neighborhoods For Medical Segmentation
Aug 06, 2021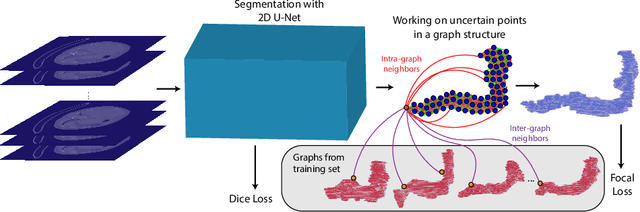
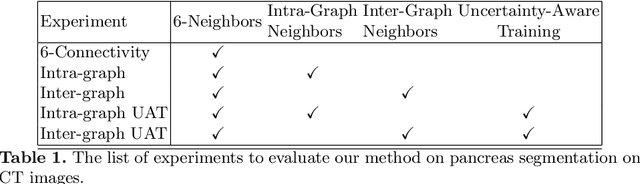
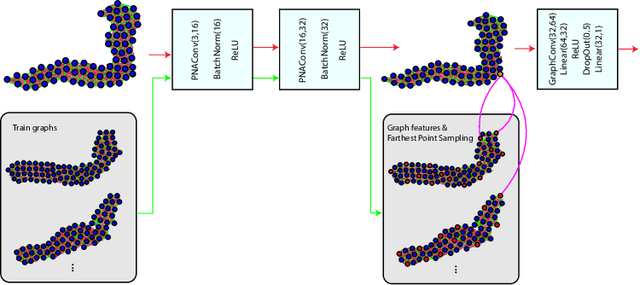

In recent years, deep learning based methods have shown success in essential medical image analysis tasks such as segmentation. Post-processing and refining the results of segmentation is a common practice to decrease the misclassifications originating from the segmentation network. In addition to widely used methods like Conditional Random Fields (CRFs) which focus on the structure of the segmented volume/area, a graph-based recent approach makes use of certain and uncertain points in a graph and refines the segmentation according to a small graph convolutional network (GCN). However, there are two drawbacks of the approach: most of the edges in the graph are assigned randomly and the GCN is trained independently from the segmentation network. To address these issues, we define a new neighbor-selection mechanism according to feature distances and combine the two networks in the training procedure. According to the experimental results on pancreas segmentation from Computed Tomography (CT) images, we demonstrate improvement in the quantitative measures. Also, examining the dynamic neighbors created by our method, edges between semantically similar image parts are observed. The proposed method also shows qualitative enhancements in the segmentation maps, as demonstrated in the visual results.
Evidential Turing Processes
Jun 02, 2021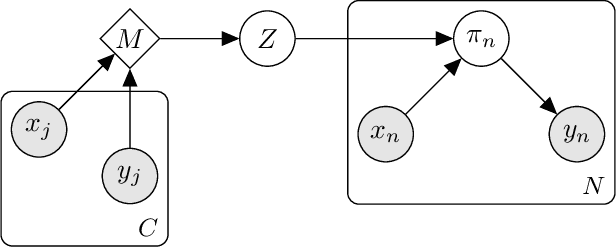

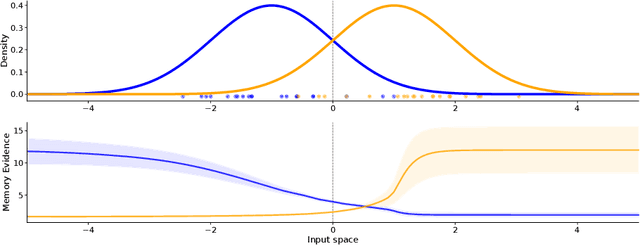
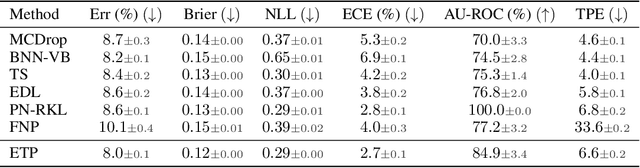
A probabilistic classifier with reliable predictive uncertainties i) fits successfully to the target domain data, ii) provides calibrated class probabilities in difficult regions of the target domain (e.g. class overlap), and iii) accurately identifies queries coming out of the target domain and reject them. We introduce an original combination of evidential deep learning, neural processes, and neural Turing machines capable of providing all three essential properties mentioned above for total uncertainty quantification. We observe our method on three image classification benchmarks and two neural net architectures to consistently give competitive or superior scores with respect to multiple uncertainty quantification metrics against state-of-the-art methods explicitly tailored to one or a few of them. Our unified solution delivers an implementation-friendly and computationally efficient recipe for safety clearance and provides intellectual economy to an investigation of algorithmic roots of epistemic awareness in deep neural nets.
Single Image Depth Estimation: An Overview
Apr 13, 2021
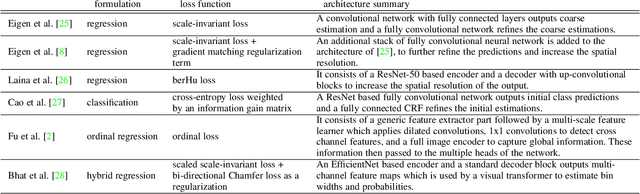

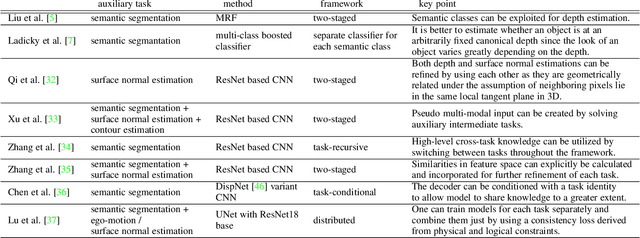
We review solutions to the problem of depth estimation, arguably the most important subtask in scene understanding. We focus on the single image depth estimation problem. Due to its properties, the single image depth estimation problem is currently best tackled with machine learning methods, most successfully with convolutional neural networks. We provide an overview of the field by examining key works. We examine non-deep learning approaches that mostly predate deep learning and utilize hand-crafted features and assumptions, and more recent works that mostly use deep learning techniques. The single image depth estimation problem is tackled first in a supervised fashion with absolute or relative depth information acquired from human or sensor-labeled data, or in an unsupervised way using unlabelled stereo images or video datasets. We also study multitask approaches that combine the depth estimation problem with related tasks such as semantic segmentation and surface normal estimation. Finally, we discuss investigations into the mechanisms, principles, and failure cases of contemporary solutions.
ODFNet: Using orientation distribution functions to characterize 3D point clouds
Dec 08, 2020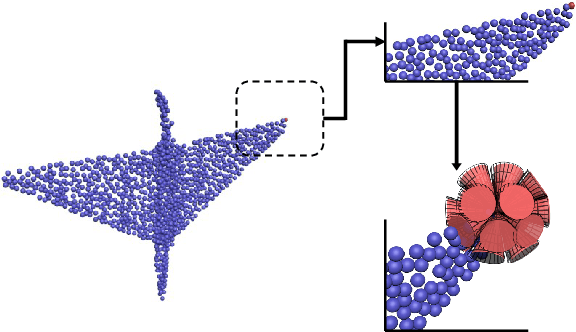
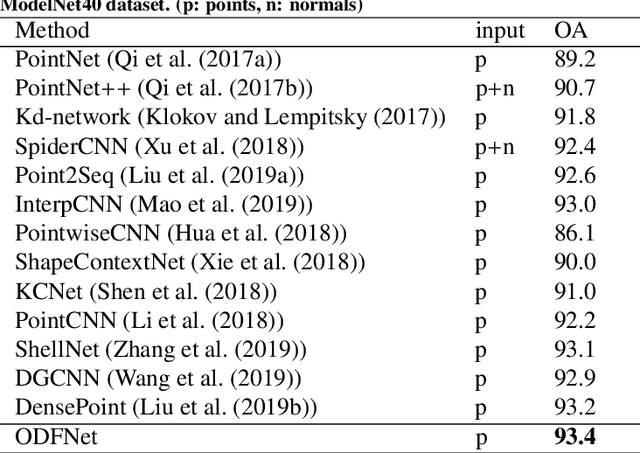

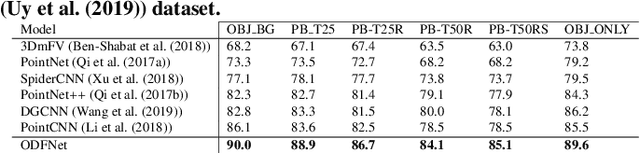
Learning new representations of 3D point clouds is an active research area in 3D vision, as the order-invariant point cloud structure still presents challenges to the design of neural network architectures. Recent works explored learning either global or local features or both for point clouds, however none of the earlier methods focused on capturing contextual shape information by analysing local orientation distribution of points. In this paper, we leverage on point orientation distributions around a point in order to obtain an expressive local neighborhood representation for point clouds. We achieve this by dividing the spherical neighborhood of a given point into predefined cone volumes, and statistics inside each volume are used as point features. In this way, a local patch can be represented by not only the selected point's nearest neighbors, but also considering a point density distribution defined along multiple orientations around the point. We are then able to construct an orientation distribution function (ODF) neural network that involves an ODFBlock which relies on mlp (multi-layer perceptron) layers. The new ODFNet model achieves state-of the-art accuracy for object classification on ModelNet40 and ScanObjectNN datasets, and segmentation on ShapeNet S3DIS datasets.
Exploring DeshuffleGANs in Self-Supervised Generative Adversarial Networks
Nov 03, 2020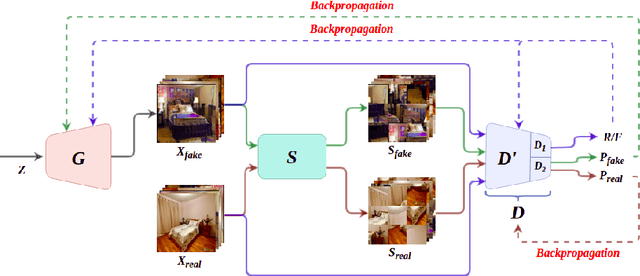

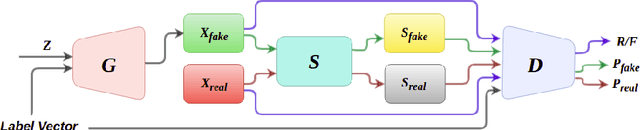

Generative Adversarial Networks (GANs) have become the most used network models towards solving the problem of image generation. In recent years, self-supervised GANs are proposed to aid stabilized GAN training without the catastrophic forgetting problem and to improve the image generation quality without the need for the class labels of the data. However, the generalizability of the self-supervision tasks on different GAN architectures is not studied before. To that end, we extensively analyze the contribution of the deshuffling task of DeshuffleGANs in the generalizability context. We assign the deshuffling task to two different GAN discriminators and study the effects of the deshuffling on both architectures. We also evaluate the performance of DeshuffleGANs on various datasets that are mostly used in GAN benchmarks: LSUN-Bedroom, LSUN-Church, and CelebA-HQ. We show that the DeshuffleGAN obtains the best FID results for LSUN datasets compared to the other self-supervised GANs. Furthermore, we compare the deshuffling with the rotation prediction that is firstly deployed to the GAN training and demonstrate that its contribution exceeds the rotation prediction. Lastly, we show the contribution of the self-supervision tasks to the GAN training on loss landscape and present that the effects of the self-supervision tasks may not be cooperative to the adversarial training in some settings. Our code can be found at https://github.com/gulcinbaykal/DeshuffleGAN.