 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIST: L0 Sparse Linear Regression with Momentum
Mar 19, 2015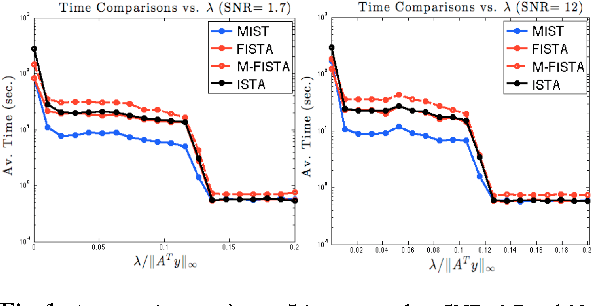
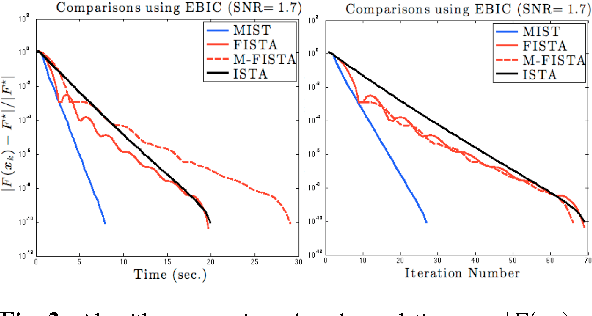
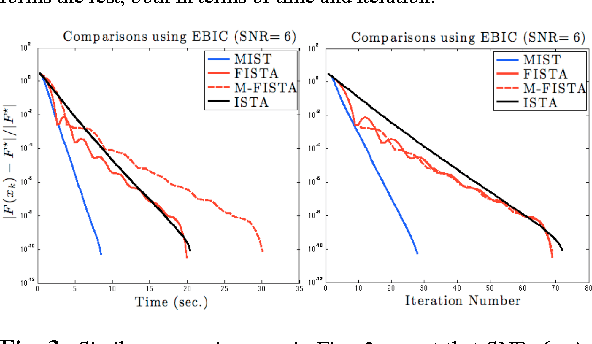
Significant attention has been given to minimizing a penalized least squares criterion for estimating sparse solutions to large linear systems of equations. The penalty is responsible for inducing sparsity and the natural choice is the so-called $l_0$ norm. In this paper we develop a Momentumized Iterative Shrinkage Thresholding (MIST) algorithm for minimizing the resulting non-convex criterion and prove its convergence to a local minimizer. Simulations on large data sets show superior performance of the proposed method to other methods.
L0 Sparse Inverse Covariance Estimation
Mar 19, 2015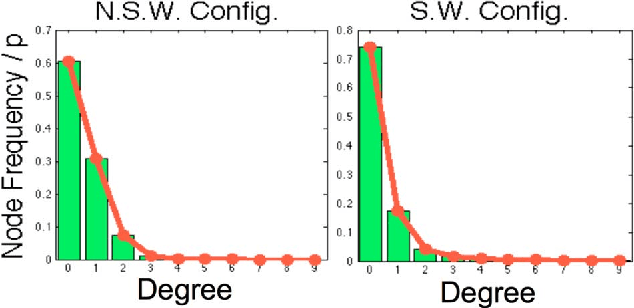
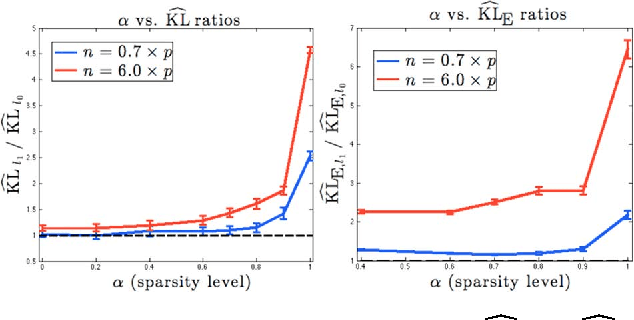
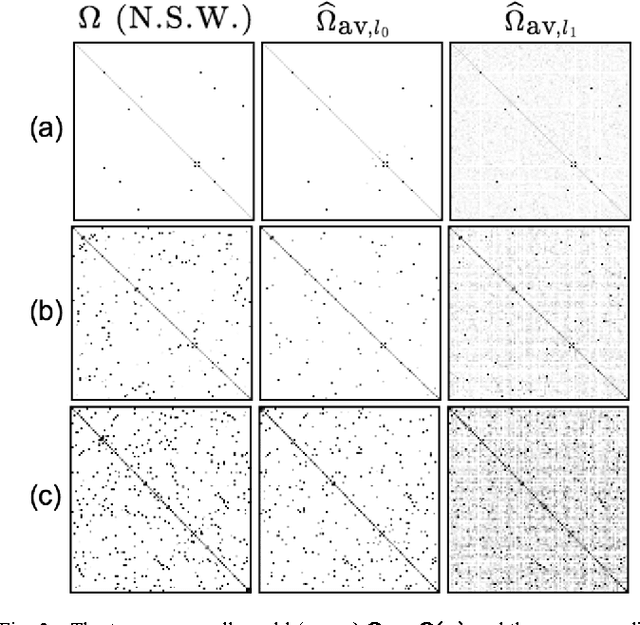
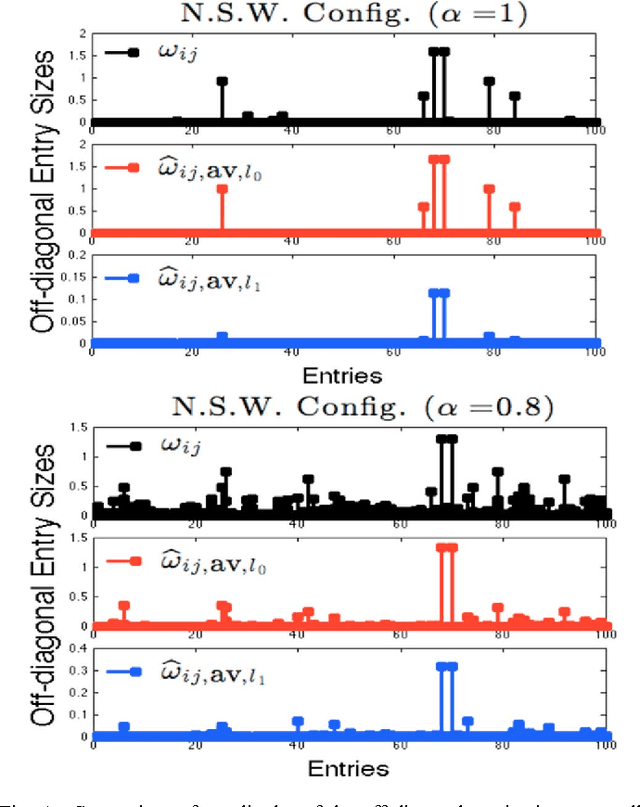
Recently, there has been focus on penalized log-likelihood covariance estimation for sparse inverse covariance (precision) matrices. The penalty is responsible for inducing sparsity, and a very common choice is the convex $l_1$ norm. However, the best estimator performance is not always achieved with this penalty. The most natural sparsity promoting "norm" is the non-convex $l_0$ penalty but its lack of convexity has deterred its use in sparse maximum likelihood estimation. In this paper we consider non-convex $l_0$ penalized log-likelihood inverse covariance estimation and present a novel cyclic descent algorithm for its optimization. Convergence to a local minimizer is proved, which is highly non-trivial, and we demonstrate via simulations the reduced bias and superior quality of the $l_0$ penalty as compared to the $l_1$ penalty.