 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperfast Selection for Decision Tree Algorithms
Jun 04, 2024We present a novel and systematic method, called Superfast Selection, for selecting the "optimal split" for decision tree and feature selection algorithms over tabular data. The method speeds up split selection on a single feature by lowering the time complexity, from O(MN) (using the standard selection methods) to O(M), where M represents the number of input examples and N the number of unique values. Additionally, the need for pre-encoding, such as one-hot or integer encoding, for feature value heterogeneity is eliminated. To demonstrate the efficiency of Superfast Selection, we empower the CART algorithm by integrating Superfast Selection into it, creating what we call Ultrafast Decision Tree (UDT). This enhancement enables UDT to complete the training process with a time complexity O(KM$^2$) (K is the number of features). Additionally, the Training Only Once Tuning enables UDT to avoid the repetitive training process required to find the optimal hyper-parameter. Experiments show that the UDT can finish a single training on KDD99-10% dataset (494K examples with 41 features) within 1 second and tuning with 214.8 sets of hyper-parameters within 0.25 second on a laptop.
CFGs: Causality Constrained Counterfactual Explanations using goal-directed ASP
May 24, 2024Machine learning models that automate decision-making are increasingly used in consequential areas such as loan approvals, pretrial bail approval, and hiring. Unfortunately, most of these models are black boxes, i.e., they are unable to reveal how they reach these prediction decisions. A need for transparency demands justification for such predictions. An affected individual might also desire explanations to understand why a decision was made. Ethical and legal considerations require informing the individual of changes in the input attribute (s) that could be made to produce a desirable outcome. Our work focuses on the latter problem of generating counterfactual explanations by considering the causal dependencies between features. In this paper, we present the framework CFGs, CounterFactual Generation with s(CASP), which utilizes the goal-directed Answer Set Programming (ASP) system s(CASP) to automatically generate counterfactual explanations from models generated by rule-based machine learning algorithms in particular. We benchmark CFGs with the FOLD-SE model. Reaching the counterfactual state from the initial state is planned and achieved using a series of interventions. To validate our proposal, we show how counterfactual explanations are computed and justified by imagining worlds where some or all factual assumptions are altered/changed. More importantly, we show how CFGs navigates between these worlds, namely, go from our initial state where we obtain an undesired outcome to the imagined goal state where we obtain the desired decision, taking into account the causal relationships among features.
A Neurosymbolic Framework for Bias Correction in CNNs
May 24, 2024



Recent efforts in interpreting Convolutional Neural Networks (CNNs) focus on translating the activation of CNN filters into stratified Answer Set Programming (ASP) rule-sets. The CNN filters are known to capture high-level image concepts, thus the predicates in the rule-set are mapped to the concept that their corresponding filter represents. Hence, the rule-set effectively exemplifies the decision-making process of the CNN in terms of the concepts that it learns for any image classification task. These rule-sets help expose and understand the biases in CNNs, although correcting the biases effectively remains a challenge. We introduce a neurosymbolic framework called NeSyBiCor for bias correction in a trained CNN. Given symbolic concepts that the CNN is biased towards, expressed as ASP constraints, we convert the undesirable and desirable concepts to their corresponding vector representations. Then, the CNN is retrained using our novel semantic similarity loss that pushes the filters away from the representations of concepts that are undesirable while pushing them closer to the concepts that are desirable. The final ASP rule-set obtained after retraining, satisfies the constraints to a high degree, thus showing the revision in the knowledge of the CNN for the image classification task. We demonstrate that our NeSyBiCor framework successfully corrects the biases of CNNs trained with subsets of classes from the Places dataset while sacrificing minimal accuracy and improving interpretability, by greatly decreasing the size of the final bias-corrected rule-set w.r.t. the initial rule-set.
Counterfactual Generation with Answer Set Programming
Feb 06, 2024Machine learning models that automate decision-making are increasingly being used in consequential areas such as loan approvals, pretrial bail approval, hiring, and many more. Unfortunately, most of these models are black-boxes, i.e., they are unable to reveal how they reach these prediction decisions. A need for transparency demands justification for such predictions. An affected individual might also desire explanations to understand why a decision was made. Ethical and legal considerations may further require informing the individual of changes in the input attribute that could be made to produce a desirable outcome. This paper focuses on the latter problem of automatically generating counterfactual explanations. We propose a framework Counterfactual Generation with s(CASP) (CFGS) that utilizes answer set programming (ASP) and the s(CASP) goal-directed ASP system to automatically generate counterfactual explanations from rules generated by rule-based machine learning (RBML) algorithms. In our framework, we show how counterfactual explanations are computed and justified by imagining worlds where some or all factual assumptions are altered/changed. More importantly, we show how we can navigate between these worlds, namely, go from our original world/scenario where we obtain an undesired outcome to the imagined world/scenario where we obtain a desired/favourable outcome.
Counterfactual Explanation Generation with s(CASP)
Oct 23, 2023Machine learning models that automate decision-making are increasingly being used in consequential areas such as loan approvals, pretrial bail, hiring, and many more. Unfortunately, most of these models are black-boxes, i.e., they are unable to reveal how they reach these prediction decisions. A need for transparency demands justification for such predictions. An affected individual might desire explanations to understand why a decision was made. Ethical and legal considerations may further require informing the individual of changes in the input attribute that could be made to produce a desirable outcome. This paper focuses on the latter problem of automatically generating counterfactual explanations. Our approach utilizes answer set programming and the s(CASP) goal-directed ASP system. Answer Set Programming (ASP) is a well-known knowledge representation and reasoning paradigm. s(CASP) is a goal-directed ASP system that executes answer-set programs top-down without grounding them. The query-driven nature of s(CASP) allows us to provide justifications as proof trees, which makes it possible to analyze the generated counterfactual explanations. We show how counterfactual explanations are computed and justified by imagining multiple possible worlds where some or all factual assumptions are untrue and, more importantly, how we can navigate between these worlds. We also show how our algorithm can be used to find the Craig Interpolant for a class of answer set programs for a failing query.
Using Logic Programming and Kernel-Grouping for Improving Interpretability of Convolutional Neural Networks
Oct 19, 2023Within the realm of deep learning, the interpretability of Convolutional Neural Networks (CNNs), particularly in the context of image classification tasks, remains a formidable challenge. To this end we present a neurosymbolic framework, NeSyFOLD-G that generates a symbolic rule-set using the last layer kernels of the CNN to make its underlying knowledge interpretable. What makes NeSyFOLD-G different from other similar frameworks is that we first find groups of similar kernels in the CNN (kernel-grouping) using the cosine-similarity between the feature maps generated by various kernels. Once such kernel groups are found, we binarize each kernel group's output in the CNN and use it to generate a binarization table which serves as input data to FOLD-SE-M which is a Rule Based Machine Learning (RBML) algorithm. FOLD-SE-M then generates a rule-set that can be used to make predictions. We present a novel kernel grouping algorithm and show that grouping similar kernels leads to a significant reduction in the size of the rule-set generated by FOLD-SE-M, consequently, improving the interpretability. This rule-set symbolically encapsulates the connectionist knowledge of the trained CNN. The rule-set can be viewed as a normal logic program wherein each predicate's truth value depends on a kernel group in the CNN. Each predicate in the rule-set is mapped to a concept using a few semantic segmentation masks of the images used for training, to make it human-understandable. The last layers of the CNN can then be replaced by this rule-set to obtain the NeSy-G model which can then be used for the image classification task. The goal directed ASP system s(CASP) can be used to obtain the justification of any prediction made using the NeSy-G model. We also propose a novel algorithm for labeling each predicate in the rule-set with the semantic concept(s) that its corresponding kernel group represents.
Automated Interactive Domain-Specific Conversational Agents that Understand Human Dialogs
Mar 17, 2023Achieving human-like communication with machines remains a classic, challenging topic in the field of Knowledge Representation and Reasoning and Natural Language Processing. These Large Language Models (LLMs) rely on pattern-matching rather than a true understanding of the semantic meaning of a sentence. As a result, they may generate incorrect responses. To generate an assuredly correct response, one has to "understand" the semantics of a sentence. To achieve this "understanding", logic-based (commonsense) reasoning methods such as Answer Set Programming (ASP) are arguably needed. In this paper, we describe the AutoConcierge system that leverages LLMs and ASP to develop a conversational agent that can truly "understand" human dialogs in restricted domains. AutoConcierge is focused on a specific domain-advising users about restaurants in their local area based on their preferences. AutoConcierge will interactively understand a user's utterances, identify the missing information in them, and request the user via a natural language sentence to provide it. Once AutoConcierge has determined that all the information has been received, it computes a restaurant recommendation based on the user-preferences it has acquired from the human user. AutoConcierge is based on our STAR framework developed earlier, which uses GPT-3 to convert human dialogs into predicates that capture the deep structure of the dialog's sentence. These predicates are then input into the goal-directed s(CASP) ASP system for performing commonsense reasoning. To the best of our knowledge, AutoConcierge is the first automated conversational agent that can realistically converse like a human and provide help to humans based on truly understanding human utterances.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 09, 2023Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
NeSyFOLD: A System for Generating Logic-based Explanations from Convolutional Neural Networks
Jan 30, 2023We present a novel neurosymbolic system called NeSyFOLD that classifies images while providing a logic-based explanation of the classification. NeSyFOLD's training process is as follows: (i) We first pre-train a CNN on the input image dataset and extract activations of the last layer filters as binary values; (ii) Next, we use the FOLD-SE-M rule-based machine learning algorithm to generate a logic program that can classify an image -- represented as a vector of binary activations corresponding to each filter -- while producing a logical explanation. The rules generated by the FOLD-SE-M algorithm have filter numbers as predicates. We use a novel algorithm that we have devised for automatically mapping the CNN filters to semantic concepts in the images. This mapping is used to replace predicate names (filter numbers) in the rule-set with corresponding semantic concept labels. The resulting rule-set is highly interpretable, and can be intuitively understood by humans. We compare our NeSyFOLD system with the ERIC system that uses a decision-tree like algorithm to obtain the rules. Our system has the following advantages over ERIC: (i) NeSyFOLD generates smaller rule-sets without compromising on the accuracy and fidelity; (ii) NeSyFOLD generates the mapping of filter numbers to semantic labels automatically.
FOLD-SE: Scalable Explainable AI
Aug 16, 2022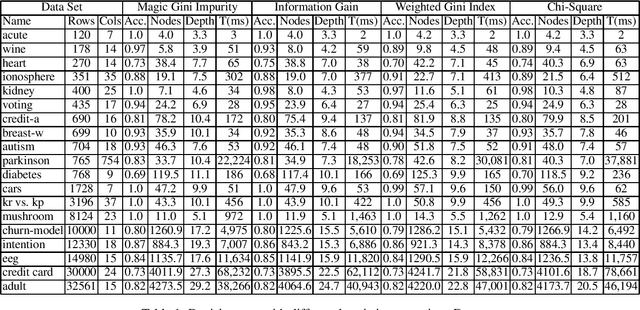
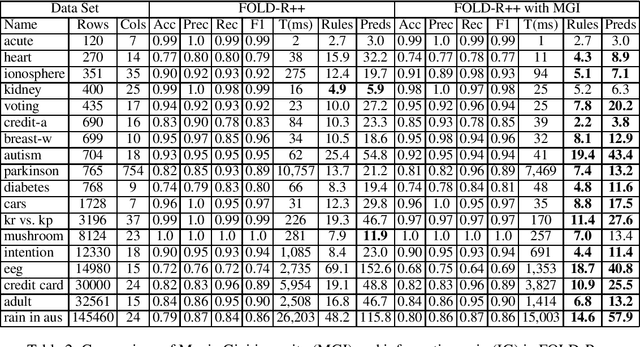
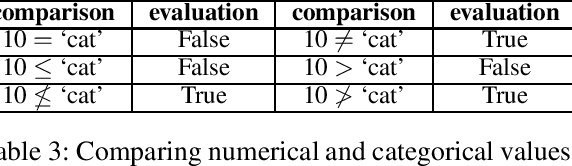

FOLD-R++ is a highly efficient and explainable rule-based machine learning algorithm for binary classification tasks. It generates a stratified normal logic program as an (explainable) trained model. We present an improvement over the FOLD-R++ algorithm, termed FOLD-SE, that provides scalable explainability (SE) while inheriting all the merits of FOLD-R++. Scalable explainability means that regardless of the size of the dataset, the number of learned rules and learned literals stay small and, hence, understandable by human beings, while maintaining good performance in classification. FOLD-SE is competitive in performance with state-of-the-art algorithms such as XGBoost and Multi-Layer Perceptrons (MLP). However, unlike XGBoost and MLP, the FOLD-SE algorithm generates a model with scalable explainability. The FOLD-SE algorithm outperforms FOLD-R++ and RIPPER algorithms in efficiency, performance, and explainability, especially for large datasets. The FOLD-RM algorithm is an extension of FOLD-R++ for multi-class classification tasks. An improved FOLD-RM algorithm built upon FOLD-SE is also presented.