 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARP 2020: The 1st Shape Recovery from Partial Textured 3D Scans Challenge Results
Oct 26, 2020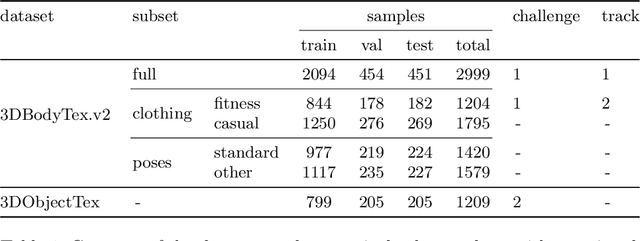


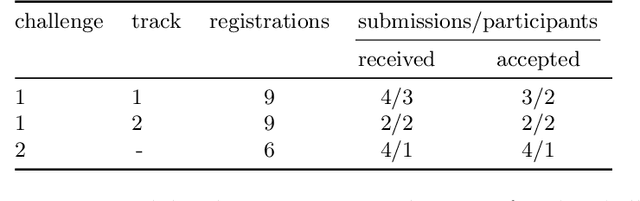
The SHApe Recovery from Partial textured 3D scans challenge, SHARP 2020, is the first edition of a challenge fostering and benchmarking methods for recovering complete textured 3D scans from raw incomplete data. SHARP 2020 is organised as a workshop in conjunction with ECCV 2020. There are two complementary challenges, the first one on 3D human scans, and the second one on generic objects. Challenge 1 is further split into two tracks, focusing, first, on large body and clothing regions, and, second, on fine body details. A novel evaluation metric is proposed to quantify jointly the shape reconstruction, the texture reconstruction and the amount of completed data. Additionally, two unique datasets of 3D scans are proposed, to provide raw ground-truth data for the benchmarks. The datasets are released to the scientific community. Moreover, an accompanying custom library of software routines is also released to the scientific community. It allows for processing 3D scans, generating partial data and performing the evaluation. Results of the competition, analysed in comparison to baselines, show the validity of the proposed evaluation metrics, and highlight the challenging aspects of the task and of the datasets. Details on the SHARP 2020 challenge can be found at https://cvi2.uni.lu/sharp2020/.
Event sequence metric learning
Feb 19, 2020
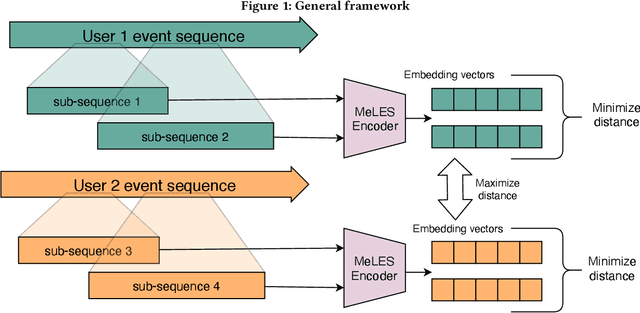

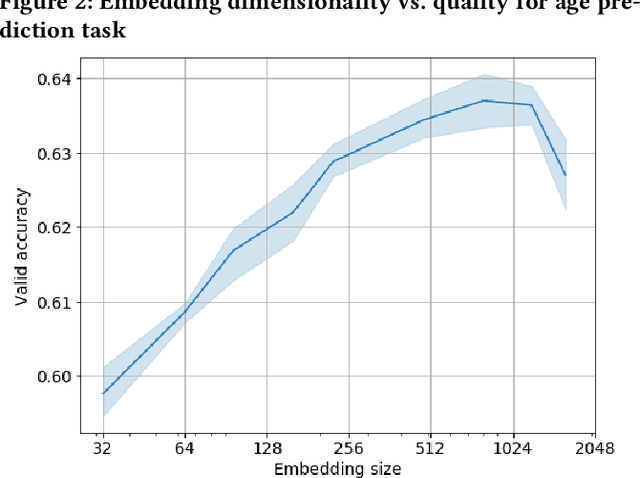
In this paper we consider a challenging problem of learning discriminative vector representations for event sequences generated by real-world users. Vector representations map behavioral client raw data to the low-dimensional fixed-length vectors in the latent space. We propose a novel method of learning those vector embeddings based on metric learning approach. We propose a strategy of raw data subsequences generation to apply a metric learning approach in a fully self-supervised way. We evaluated the method over several public bank transactions datasets and showed that self-supervised embeddings outperform other methods when applied to downstream classification tasks. Moreover, embeddings are compact and provide additional user privacy protection.
Minimal Variance Sampling in Stochastic Gradient Boosting
Oct 29, 2019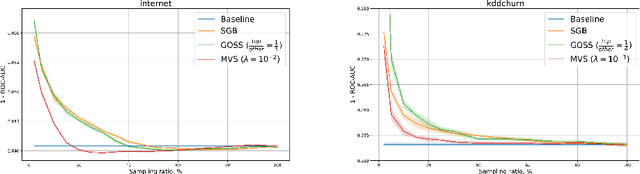


Stochastic Gradient Boosting (SGB) is a widely used approach to regularization of boosting models based on decision trees. It was shown that, in many cases, random sampling at each iteration can lead to better generalization performance of the model and can also decrease the learning time. Different sampling approaches were proposed, where probabilities are not uniform, and it is not currently clear which approach is the most effective. In this paper, we formulate the problem of randomization in SGB in terms of optimization of sampling probabilities to maximize the estimation accuracy of split scoring used to train decision trees. This optimization problem has a closed-form nearly optimal solution, and it leads to a new sampling technique, which we call Minimal Variance Sampling (MVS). The method both decreases the number of examples needed for each iteration of boosting and increases the quality of the model significantly as compared to the state-of-the art sampling methods. The superiority of the algorithm was confirmed by introducing MVS as a new default option for subsampling in CatBoost, a gradient boosting library achieving state-of-the-art quality on various machine learning tasks.
Latent Distribution Assumption for Unbiased and Consistent Consensus Modelling
Jun 20, 2019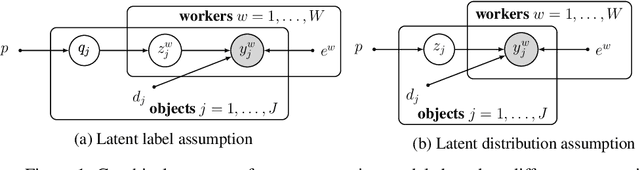
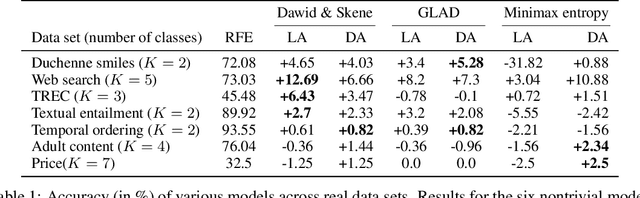
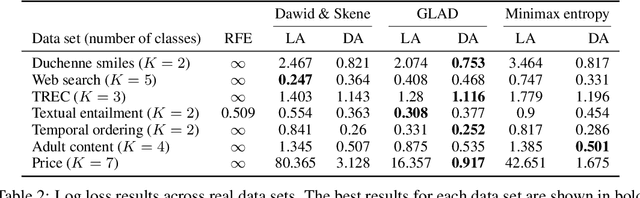
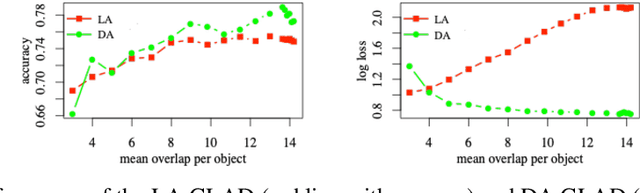
We study the problem of aggregation noisy labels. Usually, it is solved by proposing a stochastic model for the process of generating noisy labels and then estimating the model parameters using the observed noisy labels. A traditional assumption underlying previously introduced generative models is that each object has one latent true label. In contrast, we introduce a novel latent distribution assumption, implying that a unique true label for an object might not exist, but rather each object might have a specific distribution generating a latent subjective label each time the object is observed. Our experiments showed that the novel assumption is more suitable for difficult tasks, when there is an ambiguity in choosing a "true" label for certain objects.
Aggregation of pairwise comparisons with reduction of biases
Jun 09, 2019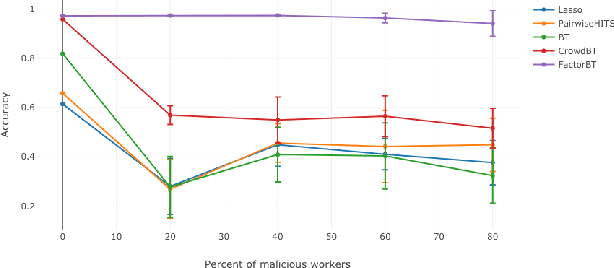

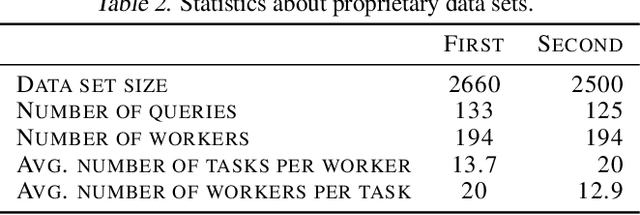
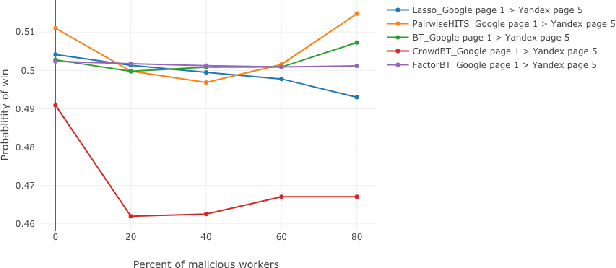
We study the problem of ranking from crowdsourced pairwise comparisons. Answers to pairwise tasks are known to be affected by the position of items on the screen, however, previous models for aggregation of pairwise comparisons do not focus on modeling such kind of biases. We introduce a new aggregation model factorBT for pairwise comparisons, which accounts for certain factors of pairwise tasks that are known to be irrelevant to the result of comparisons but may affect workers' answers due to perceptual reasons. By modeling biases that influence workers, factorBT is able to reduce the effect of biased pairwise comparisons on the resulted ranking. Our empirical studies on real-world data sets showed that factorBT produces more accurate ranking from crowdsourced pairwise comparisons than previously established models.
CatBoost: unbiased boosting with categorical features
Oct 31, 2018

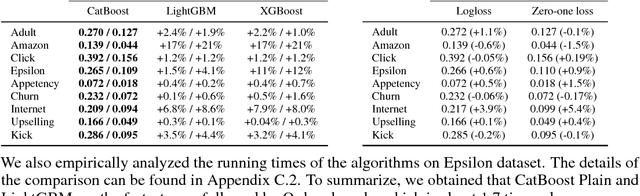
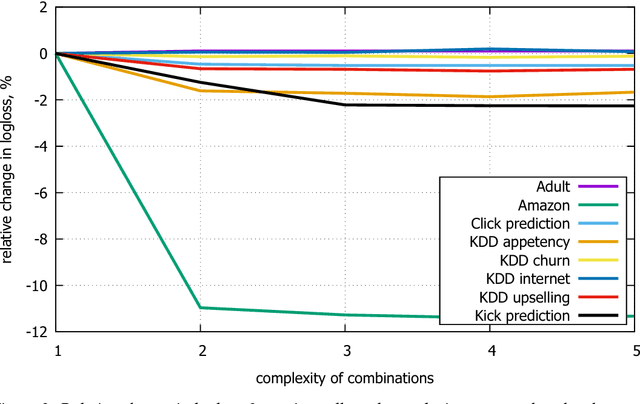
This paper presents the key algorithmic techniques behind CatBoost, a new gradient boosting toolkit. Their combination leads to CatBoost outperforming other publicly available boosting implementations in terms of quality on a variety of datasets. Two critical algorithmic advances introduced in CatBoost are the implementation of ordered boosting, a permutation-driven alternative to the classic algorithm, and an innovative algorithm for processing categorical features. Both techniques were created to fight a prediction shift caused by a special kind of target leakage present in all currently existing implementations of gradient boosting algorithms. In this paper, we provide a detailed analysis of this problem and demonstrate that proposed algorithms solve it effectively, leading to excellent empirical results.
Deep Learning Advances on Different 3D Data Representations: A Survey
Aug 04, 2018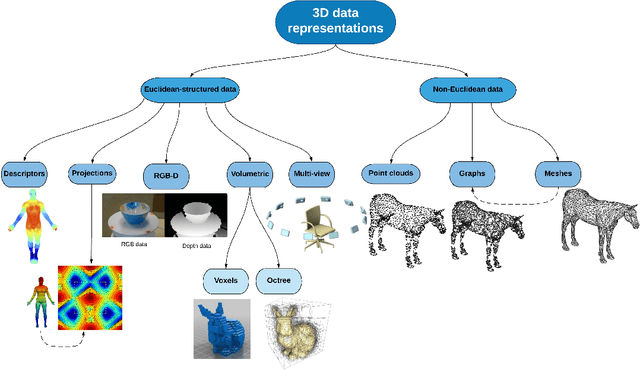
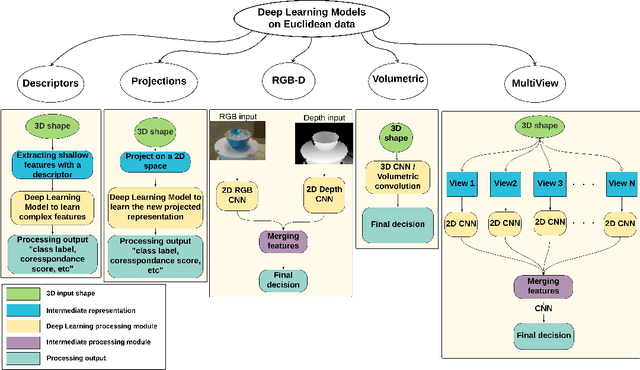
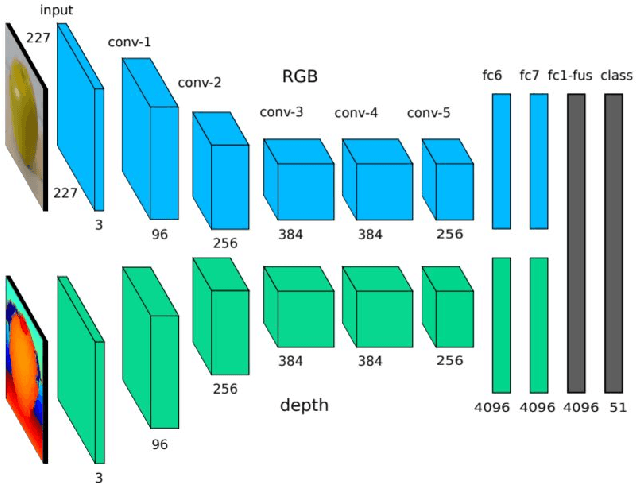
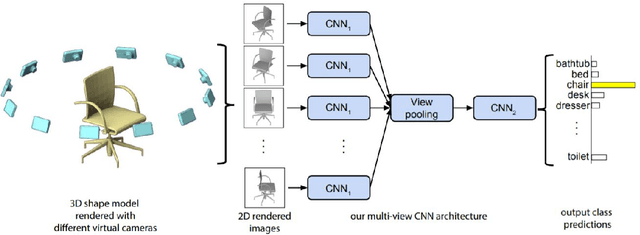
3D data is a valuable asset in the field of computer vision as it provides rich information about the full geometry of sensed objects and scenes. With the recent availability of large 3D datasets and the increase in computational power, it is today possible to consider applying deep learning to learn specific tasks on 3D data such as segmentation, recognition and correspondence. Depending on the considered 3D data representation, different challenges may be foreseen in using existent deep learning architectures. In this paper, we provide a comprehensive overview of various 3D data representations highlighting the difference between Euclidean and non-Euclidean ones. We also discuss how deep learning methods are applied on each representation, analyzing the challenges to overcome.
Riemannian Optimization for Skip-Gram Negative Sampling
Apr 26, 2017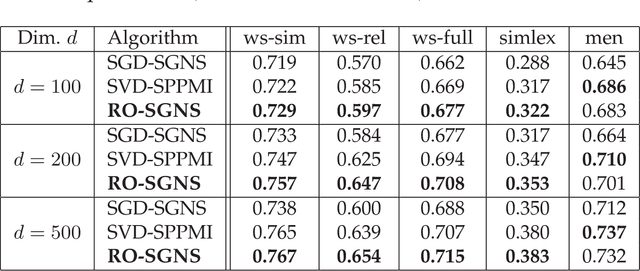
Skip-Gram Negative Sampling (SGNS) word embedding model, well known by its implementation in "word2vec" software, is usually optimized by stochastic gradient descent. However, the optimization of SGNS objective can be viewed as a problem of searching for a good matrix with the low-rank constraint. The most standard way to solve this type of problems is to apply Riemannian optimization framework to optimize the SGNS objective over the manifold of required low-rank matrices. In this paper, we propose an algorithm that optimizes SGNS objective using Riemannian optimization and demonstrates its superiority over popular competitors, such as the original method to train SGNS and SVD over SPPMI matrix.
User Model-Based Intent-Aware Metrics for Multilingual Search Evaluation
Dec 13, 2016
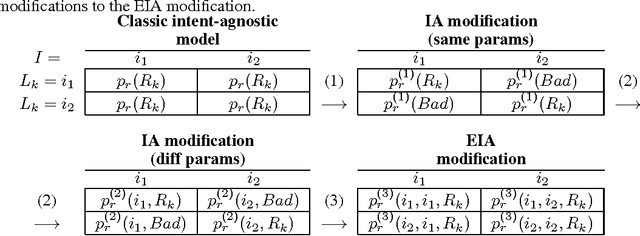
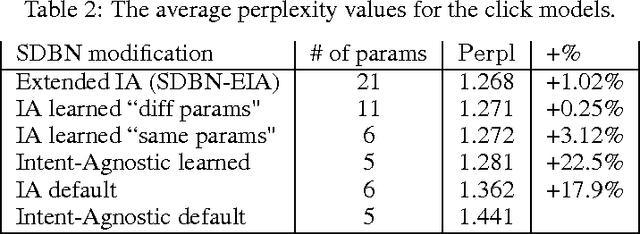
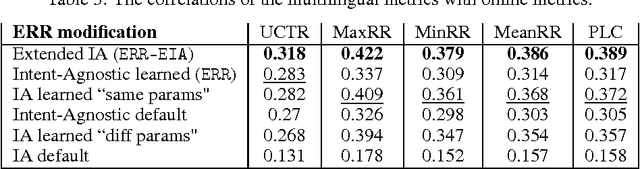
Despite the growing importance of multilingual aspect of web search, no appropriate offline metrics to evaluate its quality are proposed so far. At the same time, personal language preferences can be regarded as intents of a query. This approach translates the multilingual search problem into a particular task of search diversification. Furthermore, the standard intent-aware approach could be adopted to build a diversified metric for multilingual search on the basis of a classical IR metric such as ERR. The intent-aware approach estimates user satisfaction under a user behavior model. We show however that the underlying user behavior models is not realistic in the multilingual case, and the produced intent-aware metric do not appropriately estimate the user satisfaction. We develop a novel approach to build intent-aware user behavior models, which overcome these limitations and convert to quality metrics that better correlate with standard online metrics of user satisfaction.
* 7 pages, 1 figure, 3 tables
Prediction of Video Popularity in the Absence of Reliable Data from Video Hosting Services: Utility of Traces Left by Users on the Web
Nov 28, 2016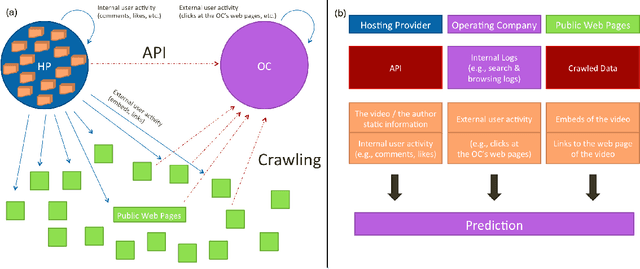
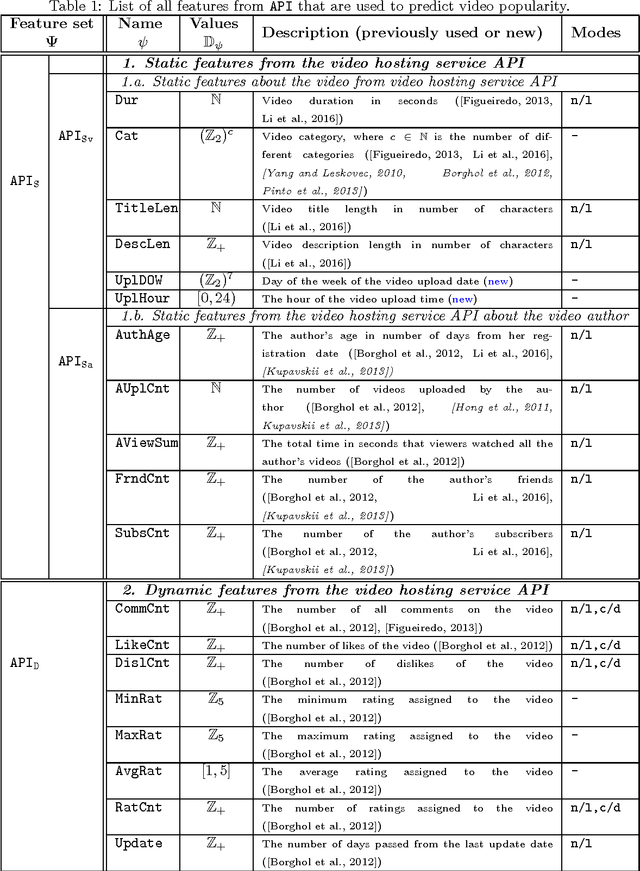
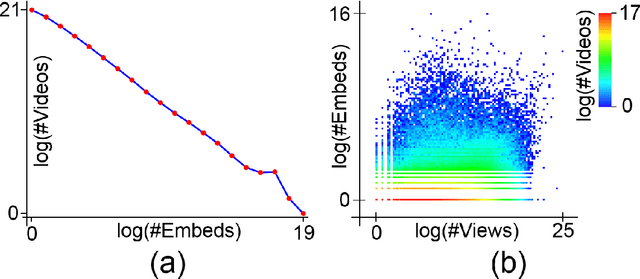
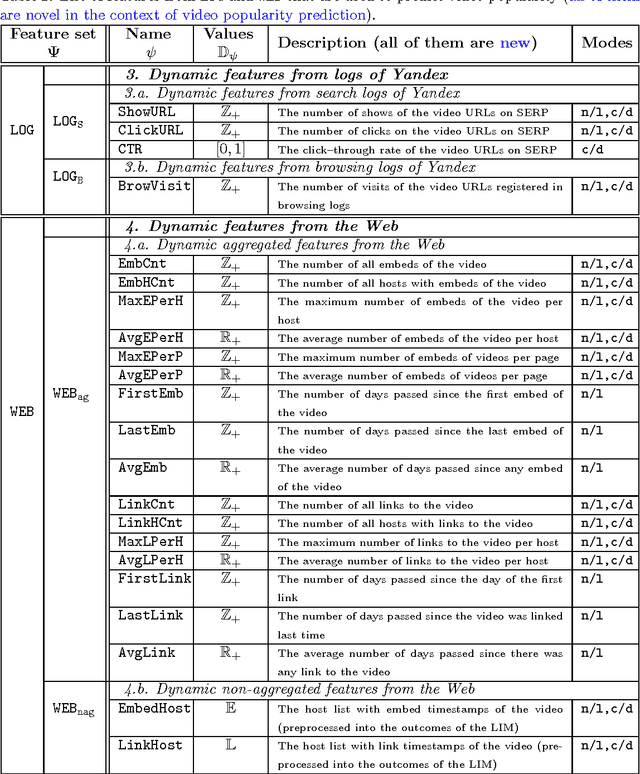
With the growth of user-generated content, we observe the constant rise of the number of companies, such as search engines, content aggregators, etc., that operate with tremendous amounts of web content not being the services hosting it. Thus, aiming to locate the most important content and promote it to the users, they face the need of estimating the current and predicting the future content popularity. In this paper, we approach the problem of video popularity prediction not from the side of a video hosting service, as done in all previous studies, but from the side of an operating company, which provides a popular video search service that aggregates content from different video hosting websites. We investigate video popularity prediction based on features from three primary sources available for a typical operating company: first, the content hosting provider may deliver its data via its API, second, the operating company makes use of its own search and browsing logs, third, the company crawls information about embeds of a video and links to a video page from publicly available resources on the Web. We show that video popularity prediction based on the embed and link data coupled with the internal search and browsing data significantly improves video popularity prediction based only on the data provided by the video hosting and can even adequately replace the API data in the cases when it is partly or completely unavailable.