 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Tasks with Industry Groups for Augmenting Commonsense Knowledge
May 12, 2025Commonsense knowledge bases (KB) are a source of specialized knowledge that is widely used to improve machine learning applications. However, even for a large KB such as ConceptNet, capturing explicit knowledge from each industry domain is challenging. For example, only a few samples of general {\em tasks} performed by various industries are available in ConceptNet. Here, a task is a well-defined knowledge-based volitional action to achieve a particular goal. In this paper, we aim to fill this gap and present a weakly-supervised framework to augment commonsense KB with tasks carried out by various industry groups (IG). We attempt to {\em match} each task with one or more suitable IGs by training a neural model to learn task-IG affinity and apply clustering to select the top-k tasks per IG. We extract a total of 2339 triples of the form $\langle IG, is~capable~of, task \rangle$ from two publicly available news datasets for 24 IGs with the precision of 0.86. This validates the reliability of the extracted task-IG pairs that can be directly added to existing KBs.
Semi-Supervised Recurrent Neural Network for Adverse Drug Reaction Mention Extraction
Sep 06, 2017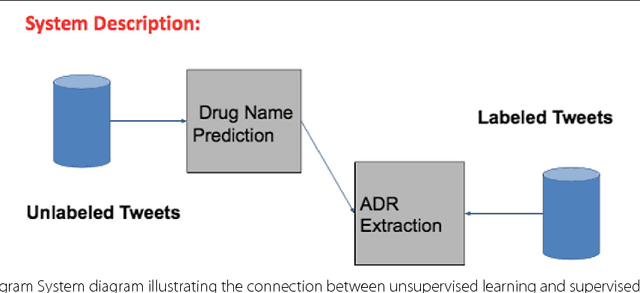


Social media is an useful platform to share health-related information due to its vast reach. This makes it a good candidate for public-health monitoring tasks, specifically for pharmacovigilance. We study the problem of extraction of Adverse-Drug-Reaction (ADR) mentions from social media, particularly from twitter. Medical information extraction from social media is challenging, mainly due to short and highly information nature of text, as compared to more technical and formal medical reports. Current methods in ADR mention extraction relies on supervised learning methods, which suffers from labeled data scarcity problem. The State-of-the-art method uses deep neural networks, specifically a class of Recurrent Neural Network (RNN) which are Long-Short-Term-Memory networks (LSTMs) \cite{hochreiter1997long}. Deep neural networks, due to their large number of free parameters relies heavily on large annotated corpora for learning the end task. But in real-world, it is hard to get large labeled data, mainly due to heavy cost associated with manual annotation. Towards this end, we propose a novel semi-supervised learning based RNN model, which can leverage unlabeled data also present in abundance on social media. Through experiments we demonstrate the effectiveness of our method, achieving state-of-the-art performance in ADR mention extraction.