 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Policy Learning with Observational Data in Multi-Action Scenarios: Estimation, Risk Preference, and Potential Failures
Mar 29, 2024This paper deals with optimal policy learning (OPL) with observational data, i.e. data-driven optimal decision-making, in multi-action (or multi-arm) settings, where a finite set of decision options is available. It is organized in three parts, where I discuss respectively: estimation, risk preference, and potential failures. The first part provides a brief review of the key approaches to estimating the reward (or value) function and optimal policy within this context of analysis. Here, I delineate the identification assumptions and statistical properties related to offline optimal policy learning estimators. In the second part, I delve into the analysis of decision risk. This analysis reveals that the optimal choice can be influenced by the decision maker's attitude towards risks, specifically in terms of the trade-off between reward conditional mean and conditional variance. Here, I present an application of the proposed model to real data, illustrating that the average regret of a policy with multi-valued treatment is contingent on the decision-maker's attitude towards risk. The third part of the paper discusses the limitations of optimal data-driven decision-making by highlighting conditions under which decision-making can falter. This aspect is linked to the failure of the two fundamental assumptions essential for identifying the optimal choice: (i) overlapping, and (ii) unconfoundedness. Some conclusions end the paper.
Machine Learning using Stata/Python
Mar 03, 2021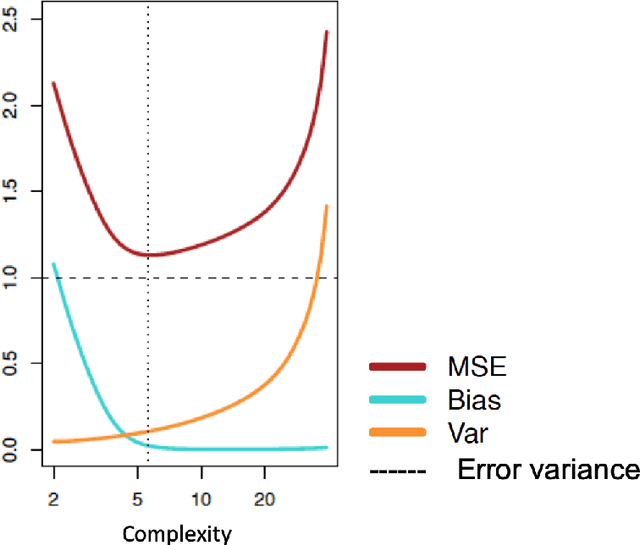

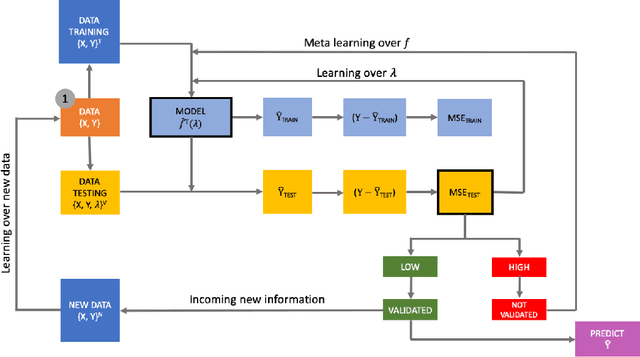
We present two related Stata modules, r_ml_stata and c_ml_stata, for fitting popular Machine Learning (ML) methods both in regression and classification settings. Using the recent Stata/Python integration platform (sfi) of Stata 16, these commands provide hyper-parameters' optimal tuning via K-fold cross-validation using greed search. More specifically, they make use of the Python Scikit-learn API to carry out both cross-validation and outcome/label prediction.