 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamBot: Music Theory Aware Chord Based Generation of Polyphonic Music with LSTMs
Nov 21, 2017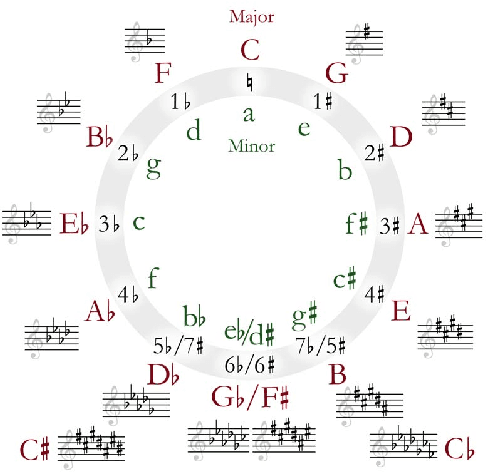
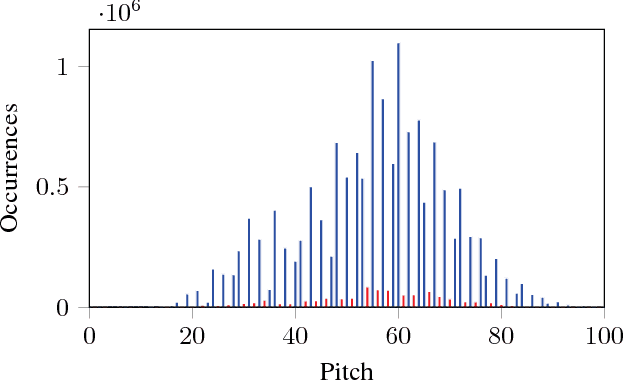
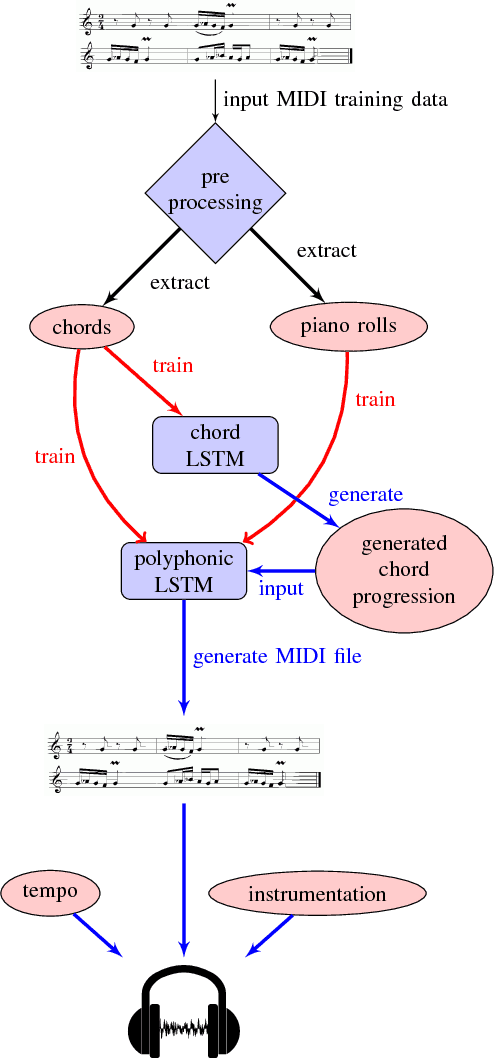
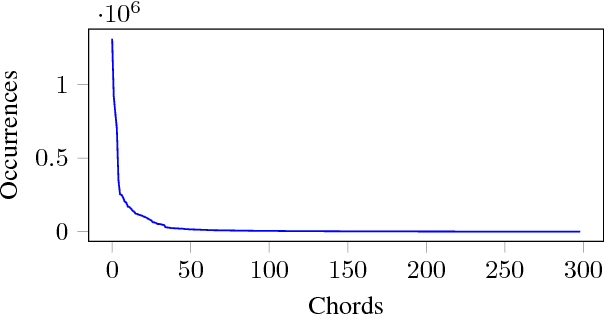
We propose a novel approach for the generation of polyphonic music based on LSTMs. We generate music in two steps. First, a chord LSTM predicts a chord progression based on a chord embedding. A second LSTM then generates polyphonic music from the predicted chord progression. The generated music sounds pleasing and harmonic, with only few dissonant notes. It has clear long-term structure that is similar to what a musician would play during a jam session. We show that our approach is sensible from a music theory perspective by evaluating the learned chord embeddings. Surprisingly, our simple model managed to extract the circle of fifths, an important tool in music theory, from the dataset.
Teaching a Machine to Read Maps with Deep Reinforcement Learning
Nov 20, 2017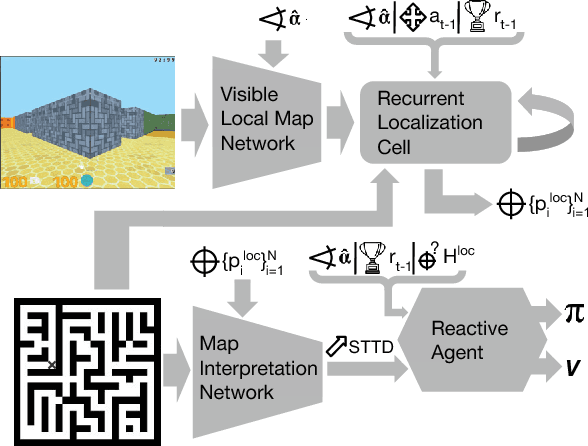
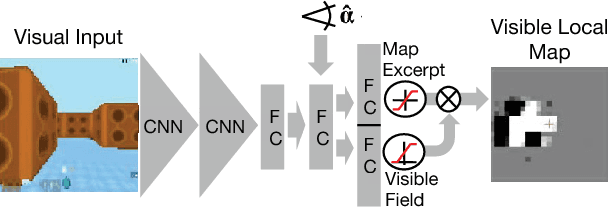
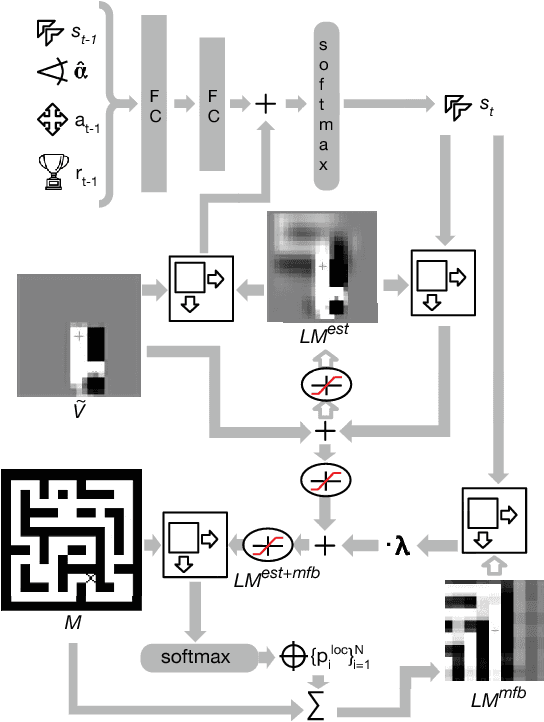
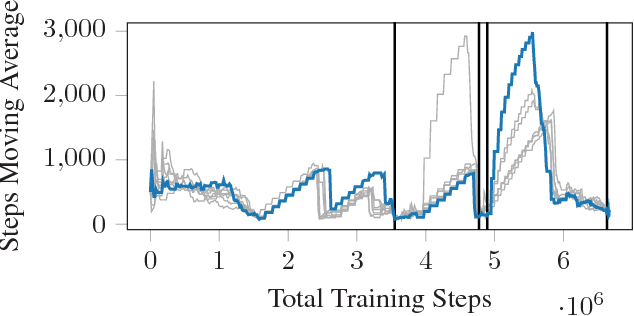
The ability to use a 2D map to navigate a complex 3D environment is quite remarkable, and even difficult for many humans. Localization and navigation is also an important problem in domains such as robotics, and has recently become a focus of the deep reinforcement learning community. In this paper we teach a reinforcement learning agent to read a map in order to find the shortest way out of a random maze it has never seen before. Our system combines several state-of-the-art methods such as A3C and incorporates novel elements such as a recurrent localization cell. Our agent learns to localize itself based on 3D first person images and an approximate orientation angle. The agent generalizes well to bigger mazes, showing that it learned useful localization and navigation capabilities.