 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing Data Reconstruction: Multiclass, Weight Decay and General Losses
Jul 04, 2023



Memorization of training data is an active research area, yet our understanding of the inner workings of neural networks is still in its infancy. Recently, Haim et al. (2022) proposed a scheme to reconstruct training samples from multilayer perceptron binary classifiers, effectively demonstrating that a large portion of training samples are encoded in the parameters of such networks. In this work, we extend their findings in several directions, including reconstruction from multiclass and convolutional neural networks. We derive a more general reconstruction scheme which is applicable to a wider range of loss functions such as regression losses. Moreover, we study the various factors that contribute to networks' susceptibility to such reconstruction schemes. Intriguingly, we observe that using weight decay during training increases reconstructability both in terms of quantity and quality. Additionally, we examine the influence of the number of neurons relative to the number of training samples on the reconstructability.
From Tempered to Benign Overfitting in ReLU Neural Networks
May 24, 2023


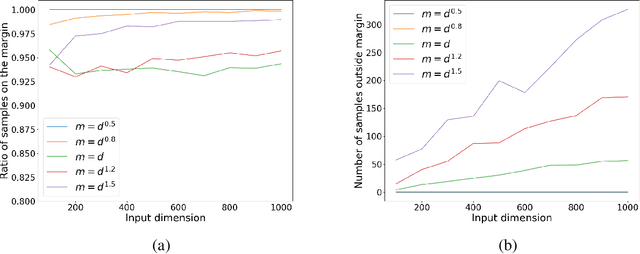
Overparameterized neural networks (NNs) are observed to generalize well even when trained to perfectly fit noisy data. This phenomenon motivated a large body of work on "benign overfitting", where interpolating predictors achieve near-optimal performance. Recently, it was conjectured and empirically observed that the behavior of NNs is often better described as "tempered overfitting", where the performance is non-optimal yet also non-trivial, and degrades as a function of the noise level. However, a theoretical justification of this claim for non-linear NNs has been lacking so far. In this work, we provide several results that aim at bridging these complementing views. We study a simple classification setting with 2-layer ReLU NNs, and prove that under various assumptions, the type of overfitting transitions from tempered in the extreme case of one-dimensional data, to benign in high dimensions. Thus, we show that the input dimension has a crucial role on the type of overfitting in this setting, which we also validate empirically for intermediate dimensions. Overall, our results shed light on the intricate connections between the dimension, sample size, architecture and training algorithm on the one hand, and the type of resulting overfitting on the other hand.
Reconstructing Training Data from Multiclass Neural Networks
May 05, 2023



Reconstructing samples from the training set of trained neural networks is a major privacy concern. Haim et al. (2022) recently showed that it is possible to reconstruct training samples from neural network binary classifiers, based on theoretical results about the implicit bias of gradient methods. In this work, we present several improvements and new insights over this previous work. As our main improvement, we show that training-data reconstruction is possible in the multi-class setting and that the reconstruction quality is even higher than in the case of binary classification. Moreover, we show that using weight-decay during training increases the vulnerability to sample reconstruction. Finally, while in the previous work the training set was of size at most $1000$ from $10$ classes, we show preliminary evidence of the ability to reconstruct from a model trained on $5000$ samples from $100$ classes.
Adversarial Examples Exist in Two-Layer ReLU Networks for Low Dimensional Data Manifolds
Mar 01, 2023



Despite a great deal of research, it is still not well-understood why trained neural networks are highly vulnerable to adversarial examples. In this work we focus on two-layer neural networks trained using data which lie on a low dimensional linear subspace. We show that standard gradient methods lead to non-robust neural networks, namely, networks which have large gradients in directions orthogonal to the data subspace, and are susceptible to small adversarial $L_2$-perturbations in these directions. Moreover, we show that decreasing the initialization scale of the training algorithm, or adding $L_2$ regularization, can make the trained network more robust to adversarial perturbations orthogonal to the data.
Reconstructing Training Data from Trained Neural Networks
Jun 15, 2022
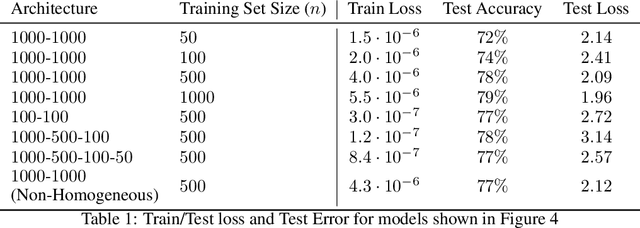
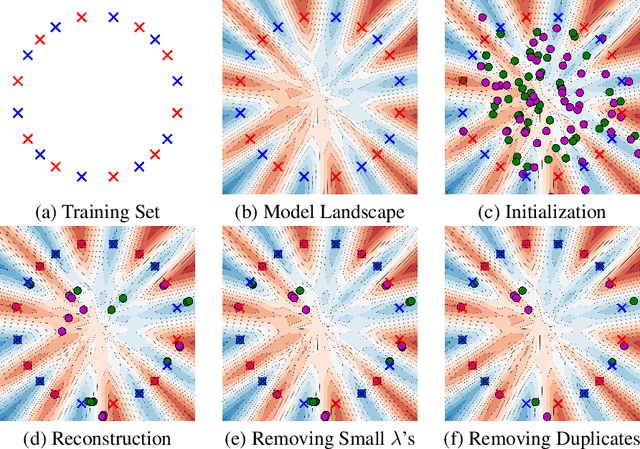
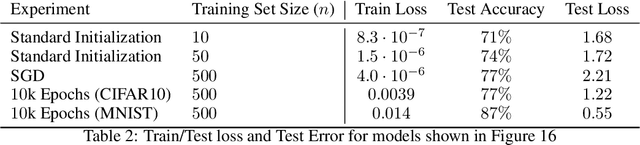
Understanding to what extent neural networks memorize training data is an intriguing question with practical and theoretical implications. In this paper we show that in some cases a significant fraction of the training data can in fact be reconstructed from the parameters of a trained neural network classifier. We propose a novel reconstruction scheme that stems from recent theoretical results about the implicit bias in training neural networks with gradient-based methods. To the best of our knowledge, our results are the first to show that reconstructing a large portion of the actual training samples from a trained neural network classifier is generally possible. This has negative implications on privacy, as it can be used as an attack for revealing sensitive training data. We demonstrate our method for binary MLP classifiers on a few standard computer vision datasets.
Gradient Methods Provably Converge to Non-Robust Networks
Feb 09, 2022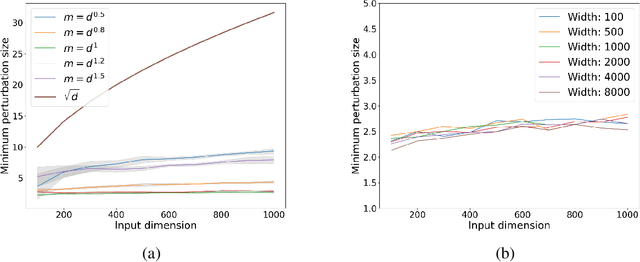
Despite a great deal of research, it is still unclear why neural networks are so susceptible to adversarial examples. In this work, we identify natural settings where depth-$2$ ReLU networks trained with gradient flow are provably non-robust (susceptible to small adversarial $\ell_2$-perturbations), even when robust networks that classify the training dataset correctly exist. Perhaps surprisingly, we show that the well-known implicit bias towards margin maximization induces bias towards non-robust networks, by proving that every network which satisfies the KKT conditions of the max-margin problem is non-robust.
Width is Less Important than Depth in ReLU Neural Networks
Feb 08, 2022We solve an open question from Lu et al. (2017), by showing that any target network with inputs in $\mathbb{R}^d$ can be approximated by a width $O(d)$ network (independent of the target network's architecture), whose number of parameters is essentially larger only by a linear factor. In light of previous depth separation theorems, which imply that a similar result cannot hold when the roles of width and depth are interchanged, it follows that depth plays a more significant role than width in the expressive power of neural networks. We extend our results to constructing networks with bounded weights, and to constructing networks with width at most $d+2$, which is close to the minimal possible width due to previous lower bounds. Both of these constructions cause an extra polynomial factor in the number of parameters over the target network. We also show an exact representation of wide and shallow networks using deep and narrow networks which, in certain cases, does not increase the number of parameters over the target network.
On the Optimal Memorization Power of ReLU Neural Networks
Oct 07, 2021We study the memorization power of feedforward ReLU neural networks. We show that such networks can memorize any $N$ points that satisfy a mild separability assumption using $\tilde{O}\left(\sqrt{N}\right)$ parameters. Known VC-dimension upper bounds imply that memorizing $N$ samples requires $\Omega(\sqrt{N})$ parameters, and hence our construction is optimal up to logarithmic factors. We also give a generalized construction for networks with depth bounded by $1 \leq L \leq \sqrt{N}$, for memorizing $N$ samples using $\tilde{O}(N/L)$ parameters. This bound is also optimal up to logarithmic factors. Our construction uses weights with large bit complexity. We prove that having such a large bit complexity is both necessary and sufficient for memorization with a sub-linear number of parameters.
Learning a Single Neuron with Bias Using Gradient Descent
Jun 02, 2021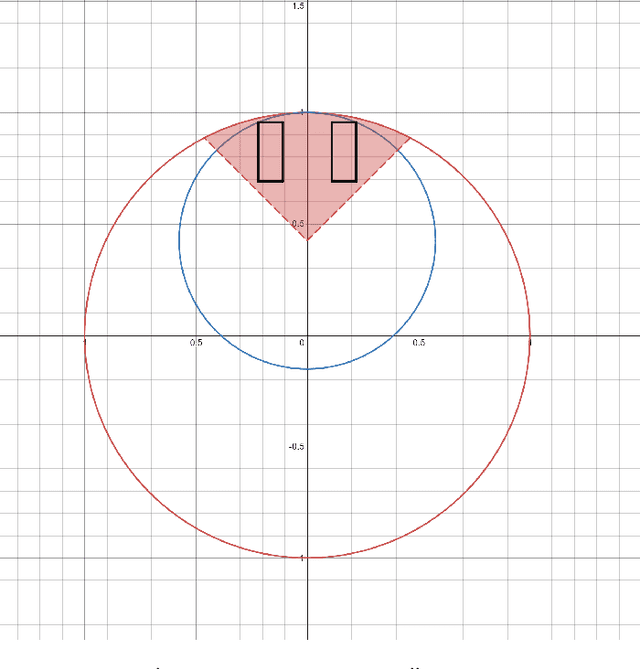
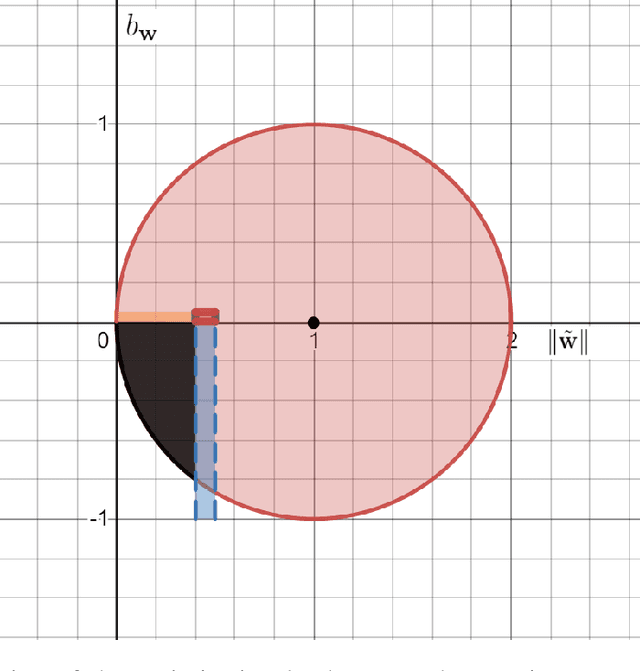
We theoretically study the fundamental problem of learning a single neuron with a bias term ($\mathbf{x} \mapsto \sigma(<\mathbf{w},\mathbf{x}> + b)$) in the realizable setting with the ReLU activation, using gradient descent. Perhaps surprisingly, we show that this is a significantly different and more challenging problem than the bias-less case (which was the focus of previous works on single neurons), both in terms of the optimization geometry as well as the ability of gradient methods to succeed in some scenarios. We provide a detailed study of this problem, characterizing the critical points of the objective, demonstrating failure cases, and providing positive convergence guarantees under different sets of assumptions. To prove our results, we develop some tools which may be of independent interest, and improve previous results on learning single neurons.
The Connection Between Approximation, Depth Separation and Learnability in Neural Networks
Jan 31, 2021Several recent works have shown separation results between deep neural networks, and hypothesis classes with inferior approximation capacity such as shallow networks or kernel classes. On the other hand, the fact that deep networks can efficiently express a target function does not mean this target function can be learned efficiently by deep neural networks. In this work we study the intricate connection between learnability and approximation capacity. We show that learnability with deep networks of a target function depends on the ability of simpler classes to approximate the target. Specifically, we show that a necessary condition for a function to be learnable by gradient descent on deep neural networks is to be able to approximate the function, at least in a weak sense, with shallow neural networks. We also show that a class of functions can be learned by an efficient statistical query algorithm if and only if it can be approximated in a weak sense by some kernel class. We give several examples of functions which demonstrate depth separation, and conclude that they cannot be efficiently learned, even by a hypothesis class that can efficiently approximate them.