 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Instruction-Tuning Local LLMs for Identifying Software Vulnerabilities
Dec 23, 2025



Large Language Models (LLMs) show significant promise in automating software vulnerability analysis, a critical task given the impact of security failure of modern software systems. However, current approaches in using LLMs to automate vulnerability analysis mostly rely on using online API-based LLM services, requiring the user to disclose the source code in development. Moreover, they predominantly frame the task as a binary classification(vulnerable or not vulnerable), limiting potential practical utility. This paper addresses these limitations by reformulating the problem as Software Vulnerability Identification (SVI), where LLMs are asked to output the type of weakness in Common Weakness Enumeration (CWE) IDs rather than simply indicating the presence or absence of a vulnerability. We also tackle the reliance on large, API-based LLMs by demonstrating that instruction-tuning smaller, locally deployable LLMs can achieve superior identification performance. In our analysis, instruct-tuning a local LLM showed better overall performance and cost trade-off than online API-based LLMs. Our findings indicate that instruct-tuned local models represent a more effective, secure, and practical approach for leveraging LLMs in real-world vulnerability management workflows.
Unsupervised Detection of Adversarial Examples with Model Explanations
Jul 22, 2021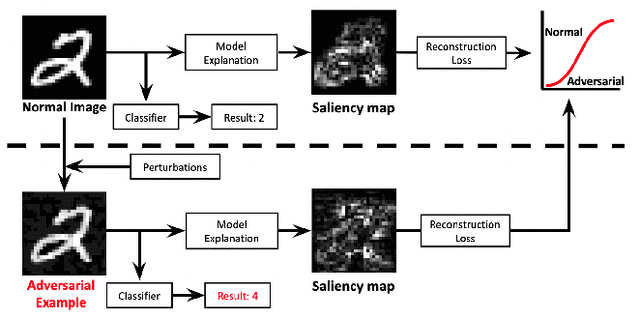


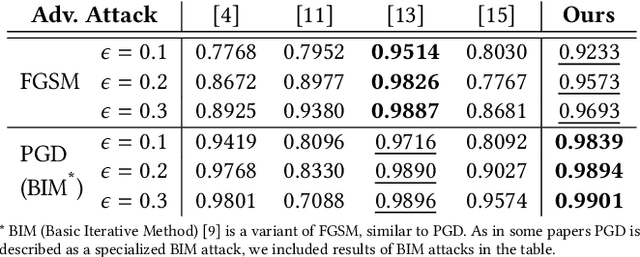
Deep Neural Networks (DNNs) have shown remarkable performance in a diverse range of machine learning applications. However, it is widely known that DNNs are vulnerable to simple adversarial perturbations, which causes the model to incorrectly classify inputs. In this paper, we propose a simple yet effective method to detect adversarial examples, using methods developed to explain the model's behavior. Our key observation is that adding small, humanly imperceptible perturbations can lead to drastic changes in the model explanations, resulting in unusual or irregular forms of explanations. From this insight, we propose an unsupervised detection of adversarial examples using reconstructor networks trained only on model explanations of benign examples. Our evaluations with MNIST handwritten dataset show that our method is capable of detecting adversarial examples generated by the state-of-the-art algorithms with high confidence. To the best of our knowledge, this work is the first in suggesting unsupervised defense method using model explanations.
Use Privacy in Data-Driven Systems: Theory and Experiments with Machine Learnt Programs
Sep 07, 2017
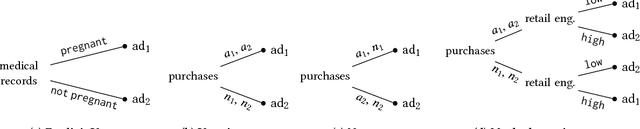
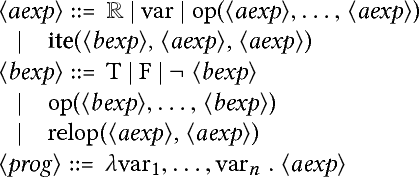

This paper presents an approach to formalizing and enforcing a class of use privacy properties in data-driven systems. In contrast to prior work, we focus on use restrictions on proxies (i.e. strong predictors) of protected information types. Our definition relates proxy use to intermediate computations that occur in a program, and identify two essential properties that characterize this behavior: 1) its result is strongly associated with the protected information type in question, and 2) it is likely to causally affect the final output of the program. For a specific instantiation of this definition, we present a program analysis technique that detects instances of proxy use in a model, and provides a witness that identifies which parts of the corresponding program exhibit the behavior. Recognizing that not all instances of proxy use of a protected information type are inappropriate, we make use of a normative judgment oracle that makes this inappropriateness determination for a given witness. Our repair algorithm uses the witness of an inappropriate proxy use to transform the model into one that provably does not exhibit proxy use, while avoiding changes that unduly affect classification accuracy. Using a corpus of social datasets, our evaluation shows that these algorithms are able to detect proxy use instances that would be difficult to find using existing techniques, and subsequently remove them while maintaining acceptable classification performance.
Proxy Non-Discrimination in Data-Driven Systems
Jul 25, 2017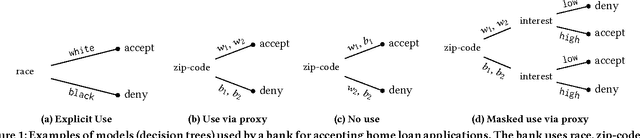

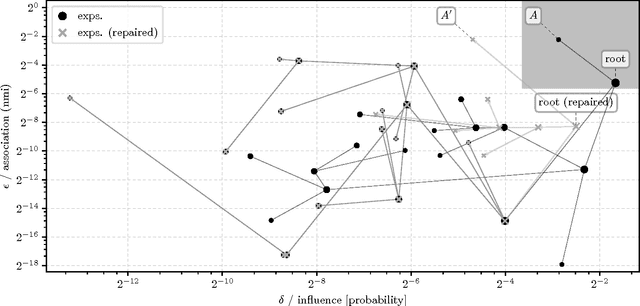
Machine learnt systems inherit biases against protected classes, historically disparaged groups, from training data. Usually, these biases are not explicit, they rely on subtle correlations discovered by training algorithms, and are therefore difficult to detect. We formalize proxy discrimination in data-driven systems, a class of properties indicative of bias, as the presence of protected class correlates that have causal influence on the system's output. We evaluate an implementation on a corpus of social datasets, demonstrating how to validate systems against these properties and to repair violations where they occur.