 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to ASK: Uncertainty-Gated Language Assistance for Reinforcement Learning
Apr 02, 2026Reinforcement learning (RL) agents often struggle with out-of-distribution (OOD) scenarios, leading to high uncertainty and random behavior. While language models (LMs) contain valuable world knowledge, larger ones incur high computational costs, hindering real-time use, and exhibit limitations in autonomous planning. We introduce Adaptive Safety through Knowledge (ASK), which combines smaller LMs with trained RL policies to enhance OOD generalization without retraining. ASK employs Monte Carlo Dropout to assess uncertainty and queries the LM for action suggestions only when uncertainty exceeds a set threshold. This selective use preserves the efficiency of existing policies while leveraging the language model's reasoning in uncertain situations. In experiments on the FrozenLake environment, ASK shows no improvement in-domain, but demonstrates robust navigation in transfer tasks, achieving a reward of 0.95. Our findings indicate that effective neuro-symbolic integration requires careful orchestration rather than simple combination, highlighting the need for sufficient model scale and effective hybridization mechanisms for successful OOD generalization.
Enhancing Authorship Attribution with Synthetic Paintings
Mar 04, 2026Attributing authorship to paintings is a historically complex task, and one of its main challenges is the limited availability of real artworks for training computational models. This study investigates whether synthetic images, generated through DreamBooth fine-tuning of Stable Diffusion, can improve the performance of classification models in this context. We propose a hybrid approach that combines real and synthetic data to enhance model accuracy and generalization across similar artistic styles. Experimental results show that adding synthetic images leads to higher ROC-AUC and accuracy compared to using only real paintings. By integrating generative and discriminative methods, this work contributes to the development of computer vision techniques for artwork authentication in data-scarce scenarios.
Navigating Time's Possibilities: Plausible Counterfactual Explanations for Multivariate Time-Series Forecast through Genetic Algorithms
Mar 01, 2026Counterfactual learning has become promising for understanding and modeling causality in complex and dynamic systems. This paper presents a novel method for counterfactual learning in the context of multivariate time series analysis and forecast. The primary objective is to uncover hidden causal relationships and identify potential interventions to achieve desired outcomes. The proposed methodology integrates genetic algorithms and rigorous causality tests to infer and validate counterfactual dependencies within temporal sequences. More specifically, we employ Granger causality to enhance the reliability of identified causal relationships, rigorously assessing their statistical significance. Then, genetic algorithms, in conjunction with quantile regression, are used to exploit these intricate causal relationships to project future scenarios. The synergy between genetic algorithms and causality tests ensures a thorough exploration of the temporal dynamics present in the data, revealing hidden dependencies and enabling the projection of outcomes under hypothetical interventions. We evaluate the performance of our algorithm on real-world data, showcasing its ability to handle complex causal relationships, revealing meaningful counterfactual insights, and allowing for the prediction of outcomes under hypothetical interventions.
* Published on IEEE TrustCom 2024
"A 6 or a 9?": Ensemble Learning Through the Multiplicity of Performant Models and Explanations
Sep 11, 2025Creating models from past observations and ensuring their effectiveness on new data is the essence of machine learning. However, selecting models that generalize well remains a challenging task. Related to this topic, the Rashomon Effect refers to cases where multiple models perform similarly well for a given learning problem. This often occurs in real-world scenarios, like the manufacturing process or medical diagnosis, where diverse patterns in data lead to multiple high-performing solutions. We propose the Rashomon Ensemble, a method that strategically selects models from these diverse high-performing solutions to improve generalization. By grouping models based on both their performance and explanations, we construct ensembles that maximize diversity while maintaining predictive accuracy. This selection ensures that each model covers a distinct region of the solution space, making the ensemble more robust to distribution shifts and variations in unseen data. We validate our approach on both open and proprietary collaborative real-world datasets, demonstrating up to 0.20+ AUROC improvements in scenarios where the Rashomon ratio is large. Additionally, we demonstrate tangible benefits for businesses in various real-world applications, highlighting the robustness, practicality, and effectiveness of our approach.
Automatic Tag Recommendation for Painting Artworks Using Diachronic Descriptions
Apr 21, 2020
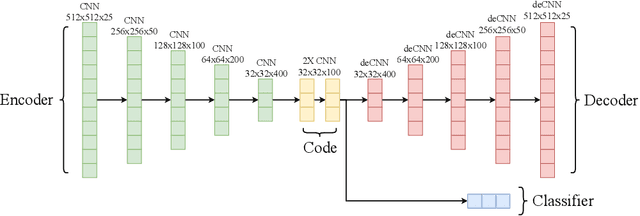

In this paper, we deal with the problem of automatic tag recommendation for painting artworks. Diachronic descriptions containing deviations on the vocabulary used to describe each painting usually occur when the work is done by many experts over time. The objective of this work is to provide a framework that produces a more accurate and homogeneous set of tags for each painting in a large collection. To validate our method we build a model based on a weakly-supervised neural network for over $5{,}300$ paintings with hand-labeled descriptions made by experts for the paintings of the Brazilian painter Candido Portinari. This work takes place with the Portinari Project which started in 1979 intending to recover and catalog the paintings of the Brazilian painter. The Portinari paintings at that time were in private collections and museums spread around the world and thus inaccessible to the public. The descriptions of each painting were made by a large number of collaborators over 40 years as the paintings were recovered and these diachronic descriptions caused deviations on the vocabulary used to describe each painting. Our proposed framework consists of (i) a neural network that receives as input the image of each painting and uses frequent itemsets as possible tags, and (ii) a clustering step in which we group related tags based on the output of the pre-trained classifiers.