 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaraman at SemEval-2026 Task 8: Three-Stage Multi-Turn Retrieval with Query Rewriting, Hybrid Search, and Cross-Encoder Reranking
May 12, 2026We describe our system for SemEval-2026 Task 8 (MTRAGEval), participating in Task A (Retrieval) across four English-language domains. Our approach employs a three-stage pipeline: (1) query rewriting via a LoRA-fine-tuned Qwen 2.5 7B model that transforms context-dependent follow-up questions into standalone queries, (2) hybrid BM25 and dense retrieval combined through Reciprocal Rank Fusion, and (3) cross-encoder reranking with BGE-reranker-v2-m3. On the official test set, the system achieves nDCG@5 of 0.531, ranking 8th out of 38 participating systems and 10.7% above the organizer baseline. Development comparisons reveal that domain-specific temperature tuning for query generation, where technical domains benefit from deterministic decoding and general domains from controlled randomness, provides consistent gains, while more complex strategies such as domain-aware prompting and multi-query expansion degrade performance.
Assessing LLMs Suitability for Knowledge Graph Completion
May 27, 2024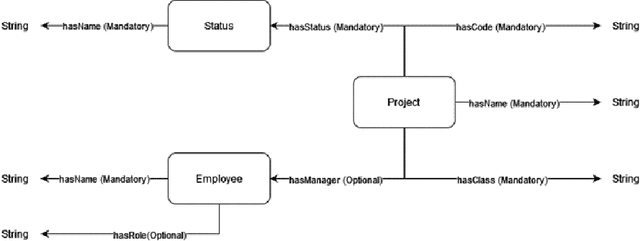



Recent work shown the capability of Large Language Models (LLMs) to solve tasks related to Knowledge Graphs, such as Knowledge Graph Completion, even in Zero- or Few-Shot paradigms. However, they are known to hallucinate answers, or output results in a non-deterministic manner, thus leading to wrongly reasoned responses, even if they satisfy the user's demands. To highlight opportunities and challenges in knowledge graphs-related tasks, we experiment with two distinguished LLMs, namely Mixtral-8x7B-Instruct-v0.1, and gpt-3.5-turbo-0125, on Knowledge Graph Completion for static knowledge graphs, using prompts constructed following the TELeR taxonomy, in Zero- and One-Shot contexts, on a Task-Oriented Dialogue system use case. When evaluated using both strict and flexible metrics measurement manners, our results show that LLMs could be fit for such a task if prompts encapsulate sufficient information and relevant examples.