 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Representations, Tree Models and Syntactic Functions
Feb 05, 2016
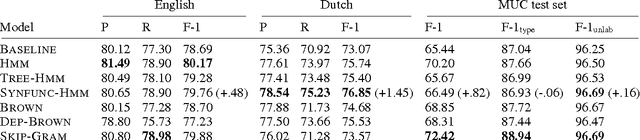
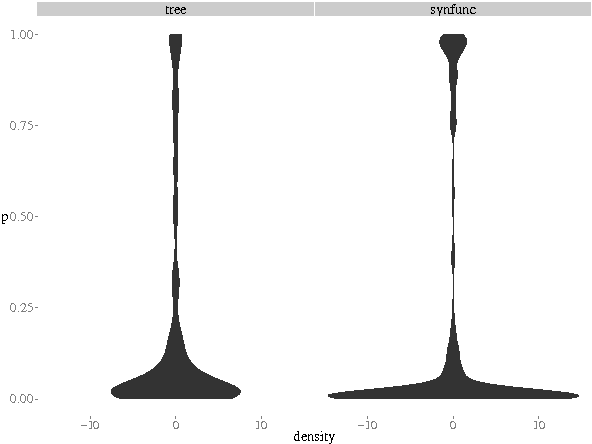
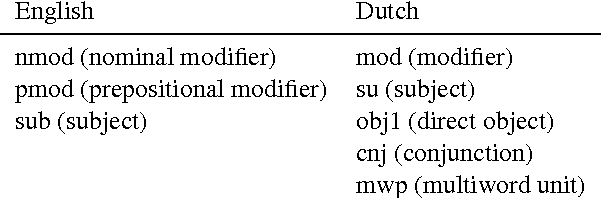
Word representations induced from models with discrete latent variables (e.g.\ HMMs) have been shown to be beneficial in many NLP applications. In this work, we exploit labeled syntactic dependency trees and formalize the induction problem as unsupervised learning of tree-structured hidden Markov models. Syntactic functions are used as additional observed variables in the model, influencing both transition and emission components. Such syntactic information can potentially lead to capturing more fine-grain and functional distinctions between words, which, in turn, may be desirable in many NLP applications. We evaluate the word representations on two tasks -- named entity recognition and semantic frame identification. We observe improvements from exploiting syntactic function information in both cases, and the results rivaling those of state-of-the-art representation learning methods. Additionally, we revisit the relationship between sequential and unlabeled-tree models and find that the advantage of the latter is not self-evident.
Approximation and Exactness in Finite State Optimality Theory
Jun 28, 2000

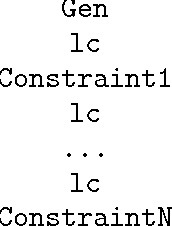

Previous work (Frank and Satta 1998; Karttunen, 1998) has shown that Optimality Theory with gradient constraints generally is not finite state. A new finite-state treatment of gradient constraints is presented which improves upon the approximation of Karttunen (1998). The method turns out to be exact, and very compact, for the syllabification analysis of Prince and Smolensky (1993).
Robust Grammatical Analysis for Spoken Dialogue Systems
Jun 25, 1999
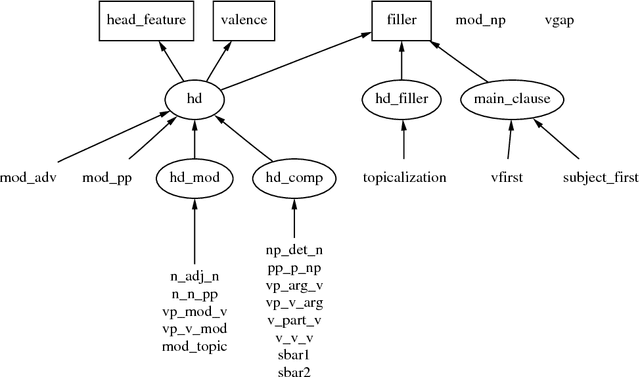
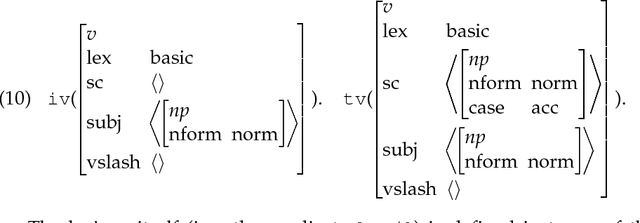
We argue that grammatical analysis is a viable alternative to concept spotting for processing spoken input in a practical spoken dialogue system. We discuss the structure of the grammar, and a model for robust parsing which combines linguistic sources of information and statistical sources of information. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
Evaluation of the NLP Components of the OVIS2 Spoken Dialogue System
Jun 14, 1999
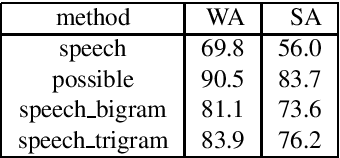
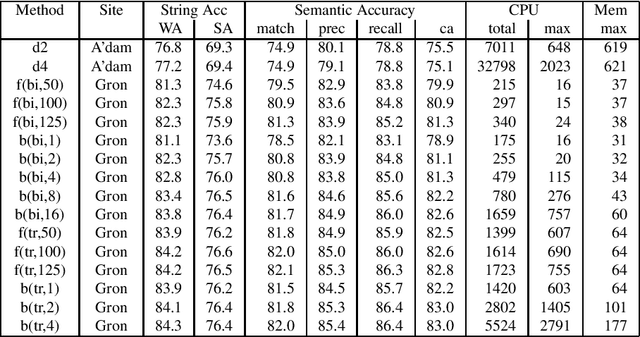
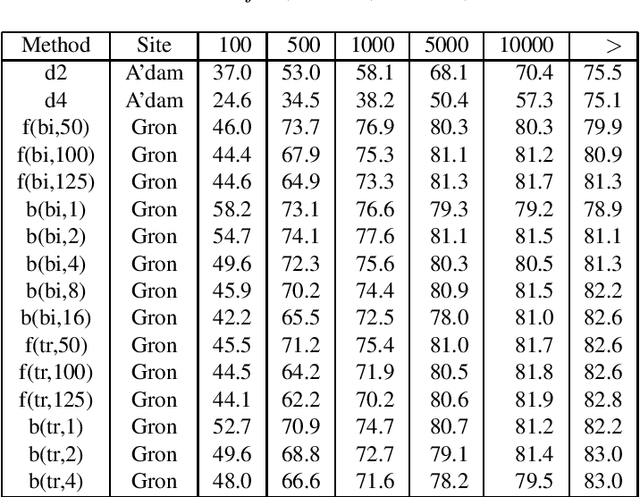
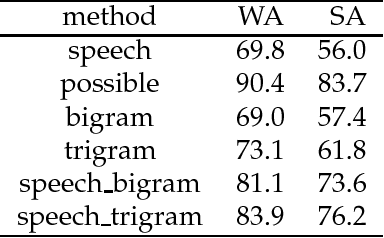
The NWO Priority Programme Language and Speech Technology is a 5-year research programme aiming at the development of spoken language information systems. In the Programme, two alternative natural language processing (NLP) modules are developed in parallel: a grammar-based (conventional, rule-based) module and a data-oriented (memory-based, stochastic, DOP) module. In order to compare the NLP modules, a formal evaluation has been carried out three years after the start of the Programme. This paper describes the evaluation procedure and the evaluation results. The grammar-based component performs much better than the data-oriented one in this comparison.
Transducers from Rewrite Rules with Backreferences
Apr 15, 1999
Context sensitive rewrite rules have been widely used in several areas of natural language processing, including syntax, morphology, phonology and speech processing. Kaplan and Kay, Karttunen, and Mohri & Sproat have given various algorithms to compile such rewrite rules into finite-state transducers. The present paper extends this work by allowing a limited form of backreferencing in such rules. The explicit use of backreferencing leads to more elegant and general solutions.
Treatment of Epsilon-Moves in Subset Construction
Apr 28, 1998The paper discusses the problem of determinising finite-state automata containing large numbers of epsilon-moves. Experiments with finite-state approximations of natural language grammars often give rise to very large automata with a very large number of epsilon-moves. The paper identifies three subset construction algorithms which treat epsilon-moves. A number of experiments has been performed which indicate that the algorithms differ considerably in practice. Furthermore, the experiments suggest that the average number of epsilon-moves per state can be used to predict which algorithm is likely to perform best for a given input automaton.
Grammatical analysis in the OVIS spoken-dialogue system
May 01, 1997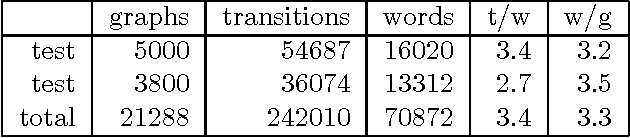
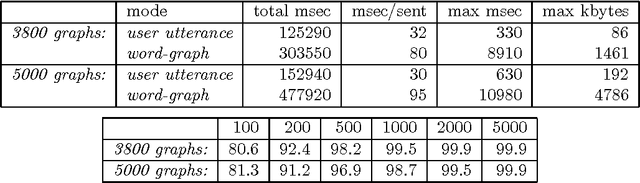
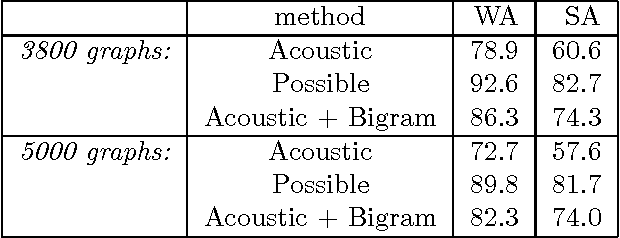
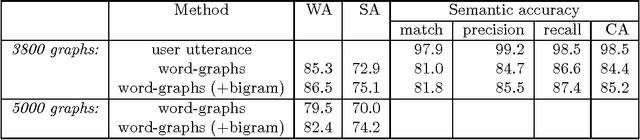
We argue that grammatical processing is a viable alternative to concept spotting for processing spoken input in a practical dialogue system. We discuss the structure of the grammar, the properties of the parser, and a method for achieving robustness. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
* 8 pages, uses aclap.sty
An Efficient Implementation of the Head-Corner Parser
Jan 17, 1997
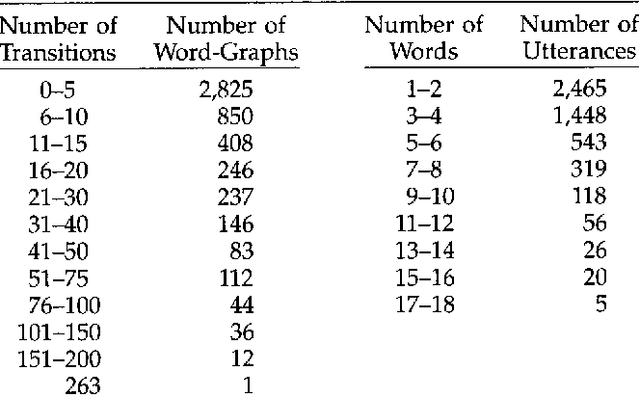

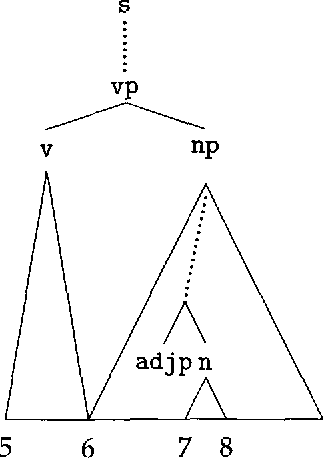
This paper describes an efficient and robust implementation of a bi-directional, head-driven parser for constraint-based grammars. This parser is developed for the OVIS system: a Dutch spoken dialogue system in which information about public transport can be obtained by telephone. After a review of the motivation for head-driven parsing strategies, and head-corner parsing in particular, a non-deterministic version of the head-corner parser is presented. A memoization technique is applied to obtain a fast parser. A goal-weakening technique is introduced which greatly improves average case efficiency, both in terms of speed and space requirements. I argue in favor of such a memoization strategy with goal-weakening in comparison with ordinary chart-parsers because such a strategy can be applied selectively and therefore enormously reduces the space requirements of the parser, while no practical loss in time-efficiency is observed. On the contrary, experiments are described in which head-corner and left-corner parsers implemented with selective memoization and goal weakening outperform `standard' chart parsers. The experiments include the grammar of the OVIS system and the Alvey NL Tools grammar. Head-corner parsing is a mix of bottom-up and top-down processing. Certain approaches towards robust parsing require purely bottom-up processing. Therefore, it seems that head-corner parsing is unsuitable for such robust parsing techniques. However, it is shown how underspecification (which arises very naturally in a logic programming environment) can be used in the head-corner parser to allow such robust parsing techniques. A particular robust parsing model is described which is implemented in OVIS.
The intersection of Finite State Automata and Definite Clause Grammars
Apr 28, 1995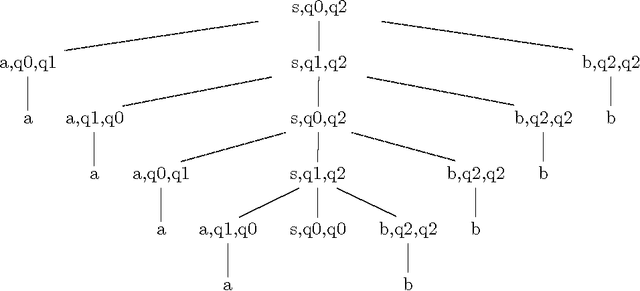

Bernard Lang defines parsing as the calculation of the intersection of a FSA (the input) and a CFG. Viewing the input for parsing as a FSA rather than as a string combines well with some approaches in speech understanding systems, in which parsing takes a word lattice as input (rather than a word string). Furthermore, certain techniques for robust parsing can be modelled as finite state transducers. In this paper we investigate how we can generalize this approach for unification grammars. In particular we will concentrate on how we might the calculation of the intersection of a FSA and a DCG. It is shown that existing parsing algorithms can be easily extended for FSA inputs. However, we also show that the termination properties change drastically: we show that it is undecidable whether the intersection of a FSA and a DCG is empty (even if the DCG is off-line parsable). Furthermore we discuss approaches to cope with the problem.
* 7 pages. Requires pictexwd package. To appear in ACL 95
Adjuncts and the Processing of Lexical Rules
May 01, 1994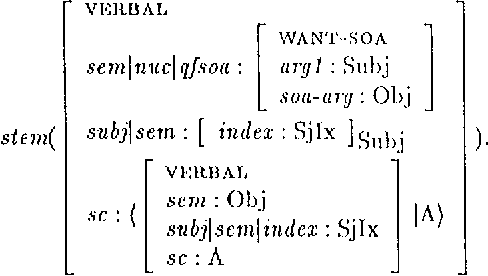
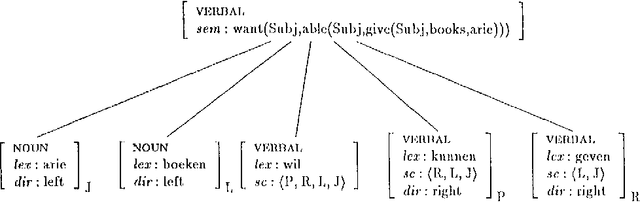
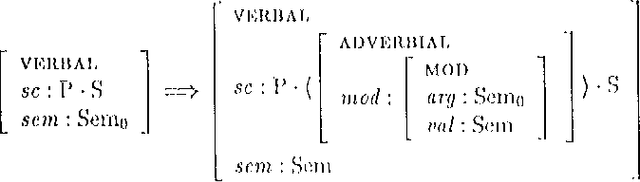

The standard HPSG analysis of Germanic verb clusters can not explain the observed narrow-scope readings of adjuncts in such verb clusters. We present an extension of the HPSG analysis that accounts for the systematic ambiguity of the scope of adjuncts in verb cluster constructions, by treating adjuncts as members of the subcat list. The extension uses powerful recursive lexical rules, implemented as complex constraints. We show how `delayed evaluation' techniques from constraint-logic programming can be used to process such lexical rules.
* 8 pages (a4wide), to be published in Coling-94