 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Adaptive Human Activity Recognition via LLM Backbones
May 12, 2026Human Activity Recognition (HAR) is a core task in pervasive computing systems, where models must operate under strict computational constraints while remaining robust to heterogeneous and evolving deployment conditions. Recent advances based on Transformer architectures have significantly improved recognition performance, but typically rely on task-specific models trained from scratch, resulting in high training cost, large data requirements, and limited adaptability to domain shifts. In this paper, we propose a paradigm shift that reuses large pretrained language models (LLMs) as generic temporal backbones for sensor-based HAR, instead of designing domain-specific Transformers. To bridge the modality gap between inertial time series and language models, we introduce a structured convolutional projection that maps multivariate accelerometer and gyroscope signals into the latent space of the LLM. The pretrained backbone is kept frozen and adapted using parameter-efficient Low-Rank Adaptation (LoRA), drastically reducing the number of trainable parameters and the overall training cost. Through extensive experiments on standard HAR benchmarks, we show that this approach enables rapid convergence, strong data efficiency, and robust cross-dataset transfer, particularly in low-data and few-shot settings. At the same time, our results highlight the complementary roles of convolutional frontends and LLMs, where local invariances are handled at the signal level while long-range temporal dependencies are captured by the pretrained backbone. Overall, this work demonstrates that LLMs can serve as a practical, frugal, and scalable foundation for adaptive HAR systems, opening new directions for reusing foundation models beyond their original language domain.
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
Mar 17, 2026Predicting drug response in patients from preclinical data remains a major challenge in precision oncology due to the substantial biological gap between in vitro cell lines and patient tumors. Rather than aiming to improve absolute in vitro prediction accuracy, this work examines whether explicitly separating representation learning from task supervision enables more sample-efficient adaptation of drug-response models to patient data under strong biological domain shift. We propose a staged transfer-learning framework in which cellular and drug representations are first learned independently from large collections of unlabeled pharmacogenomic data using autoencoder-based representation learning. These representations are then aligned with drug-response labels on cell-line data and subsequently adapted to patient tumors using few-shot supervision. Through a systematic evaluation spanning in-domain, cross-dataset, and patient-level settings, we show that unsupervised pretraining provides limited benefit when source and target domains overlap substantially, but yields clear gains when adapting to patient tumors with very limited labeled data. In particular, the proposed framework achieves faster performance improvements during few-shot patient-level adaptation while maintaining comparable accuracy to single-phase baselines on standard cell-line benchmarks. Overall, these results demonstrate that learning structured and transferable representations from unlabeled molecular profiles can substantially reduce the amount of clinical supervision required for effective drug-response prediction, offering a practical pathway toward data-efficient preclinical-to-clinical translation.
Parameter-Efficient Fine-Tuning for HAR: Integrating LoRA and QLoRA into Transformer Models
Dec 19, 2025Human Activity Recognition is a foundational task in pervasive computing. While recent advances in self-supervised learning and transformer-based architectures have significantly improved HAR performance, adapting large pretrained models to new domains remains a practical challenge due to limited computational resources on target devices. This papers investigates parameter-efficient fine-tuning techniques, specifically Low-Rank Adaptation (LoRA) and Quantized LoRA, as scalable alternatives to full model fine-tuning for HAR. We propose an adaptation framework built upon a Masked Autoencoder backbone and evaluate its performance under a Leave-One-Dataset-Out validation protocol across five open HAR datasets. Our experiments demonstrate that both LoRA and QLoRA can match the recognition performance of full fine-tuning while significantly reducing the number of trainable parameters, memory usage, and training time. Further analyses reveal that LoRA maintains robust performance even under limited supervision and that the adapter rank provides a controllable trade-off between accuracy and efficiency. QLoRA extends these benefits by reducing the memory footprint of frozen weights through quantization, with minimal impact on classification quality.
Quantifying Uncertainty in Machine Learning-Based Pervasive Systems: Application to Human Activity Recognition
Dec 10, 2025The recent convergence of pervasive computing and machine learning has given rise to numerous services, impacting almost all areas of economic and social activity. However, the use of AI techniques precludes certain standard software development practices, which emphasize rigorous testing to ensure the elimination of all bugs and adherence to well-defined specifications. ML models are trained on numerous high-dimensional examples rather than being manually coded. Consequently, the boundaries of their operating range are uncertain, and they cannot guarantee absolute error-free performance. In this paper, we propose to quantify uncertainty in ML-based systems. To achieve this, we propose to adapt and jointly utilize a set of selected techniques to evaluate the relevance of model predictions at runtime. We apply and evaluate these proposals in the highly heterogeneous and evolving domain of Human Activity Recognition (HAR). The results presented demonstrate the relevance of the approach, and we discuss in detail the assistance provided to domain experts.
Evaluation and comparison of federated learning algorithms for Human Activity Recognition on smartphones
Oct 30, 2022



Pervasive computing promotes the integration of smart devices in our living spaces to develop services providing assistance to people. Such smart devices are increasingly relying on cloud-based Machine Learning, which raises questions in terms of security (data privacy), reliance (latency), and communication costs. In this context, Federated Learning (FL) has been introduced as a new machine learning paradigm enhancing the use of local devices. At the server level, FL aggregates models learned locally on distributed clients to obtain a more general model. In this way, no private data is sent over the network, and the communication cost is reduced. Unfortunately, however, the most popular federated learning algorithms have been shown not to be adapted to some highly heterogeneous pervasive computing environments. In this paper, we propose a new FL algorithm, termed FedDist, which can modify models (here, deep neural network) during training by identifying dissimilarities between neurons among the clients. This permits to account for clients' specificity without impairing generalization. FedDist evaluated with three state-of-the-art federated learning algorithms on three large heterogeneous mobile Human Activity Recognition datasets. Results have shown the ability of FedDist to adapt to heterogeneous data and the capability of FL to deal with asynchronous situations.
* arXiv admin note: substantial text overlap with arXiv:2110.10223
Federated Continual Learning through distillation in pervasive computing
Jul 17, 2022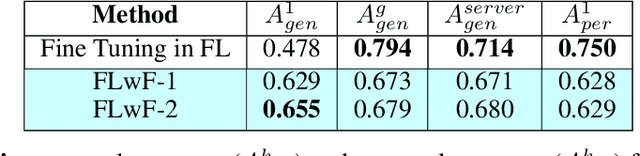
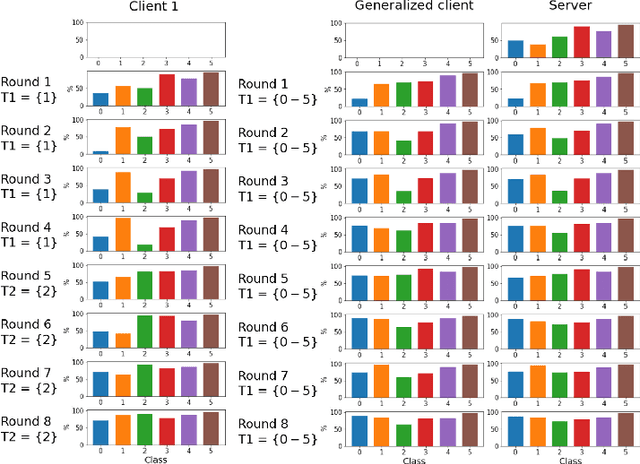
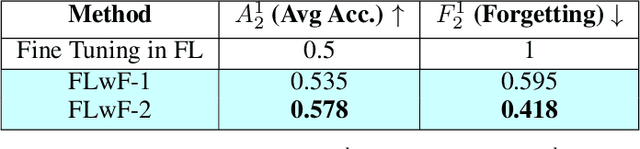
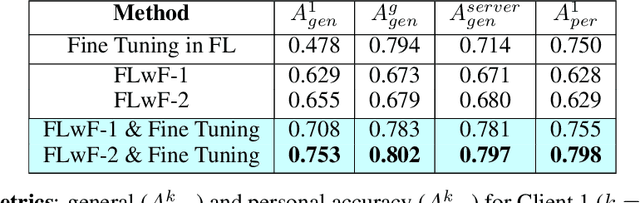
Federated Learning has been introduced as a new machine learning paradigm enhancing the use of local devices. At a server level, FL regularly aggregates models learned locally on distributed clients to obtain a more general model. Current solutions rely on the availability of large amounts of stored data at the client side in order to fine-tune the models sent by the server. Such setting is not realistic in mobile pervasive computing where data storage must be kept low and data characteristic can change dramatically. To account for this variability, a solution is to use the data regularly collected by the client to progressively adapt the received model. But such naive approach exposes clients to the well-known problem of catastrophic forgetting. To address this problem, we have defined a Federated Continual Learning approach which is mainly based on distillation. Our approach allows a better use of resources, eliminating the need to retrain from scratch at the arrival of new data and reducing memory usage by limiting the amount of data to be stored. This proposal has been evaluated in the Human Activity Recognition (HAR) domain and has shown to effectively reduce the catastrophic forgetting effect.
Federated Learning and catastrophic forgetting in pervasive computing: demonstration in HAR domain
Jul 17, 2022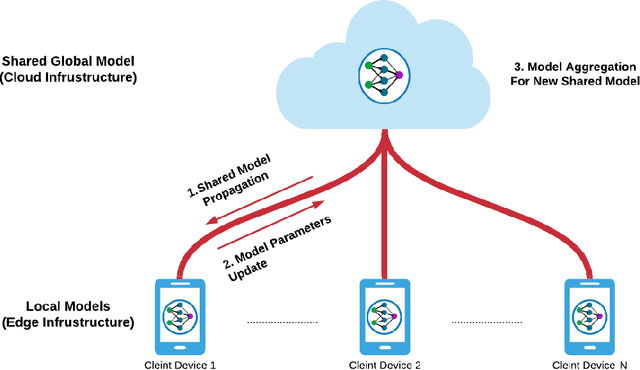
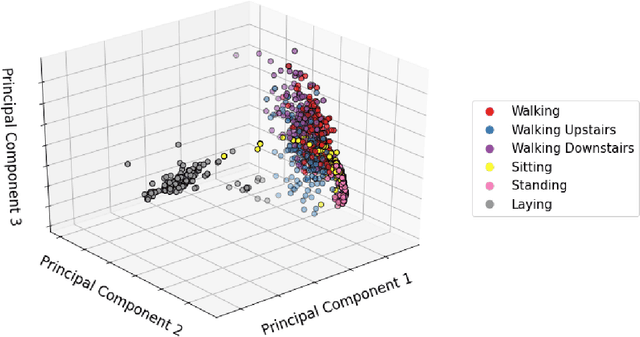
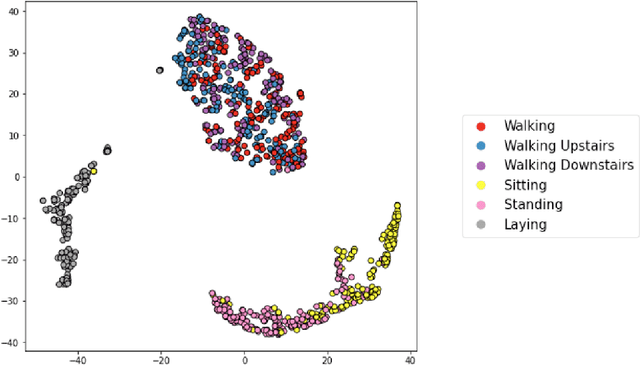
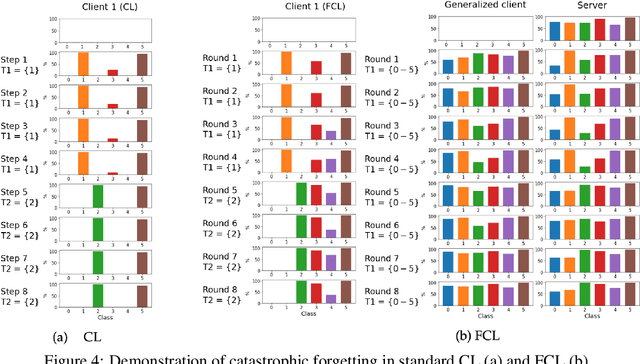
Federated Learning has been introduced as a new machine learning paradigm enhancing the use of local devices. At a server level, FL regularly aggregates models learned locally on distributed clients to obtain a more general model. In this way, no private data is sent over the network, and the communication cost is reduced. However, current solutions rely on the availability of large amounts of stored data at the client side in order to fine-tune the models sent by the server. Such setting is not realistic in mobile pervasive computing where data storage must be kept low and data characteristic (distribution) can change dramatically. To account for this variability, a solution is to use the data regularly collected by the client to progressively adapt the received model. But such naive approach exposes clients to the well-known problem of catastrophic forgetting. The purpose of this paper is to demonstrate this problem in the mobile human activity recognition context on smartphones.
A Federated Learning Aggregation Algorithm for Pervasive Computing: Evaluation and Comparison
Oct 19, 2021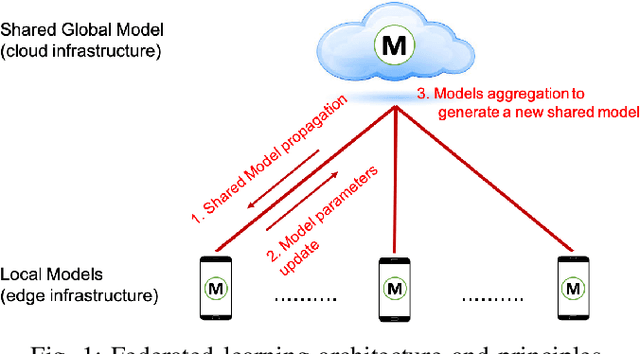
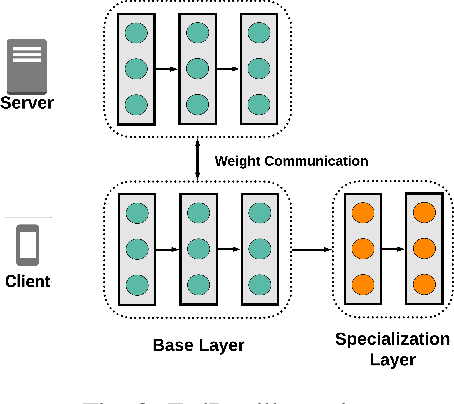
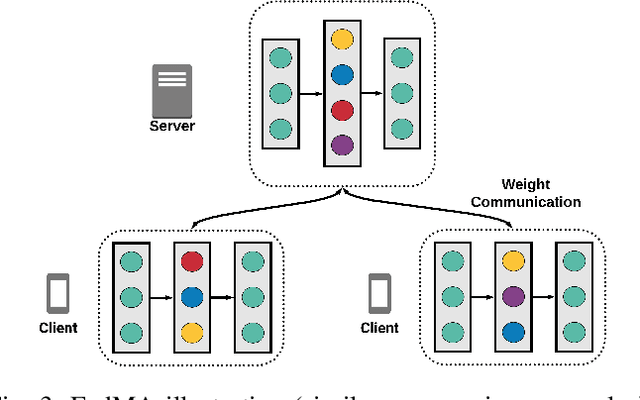
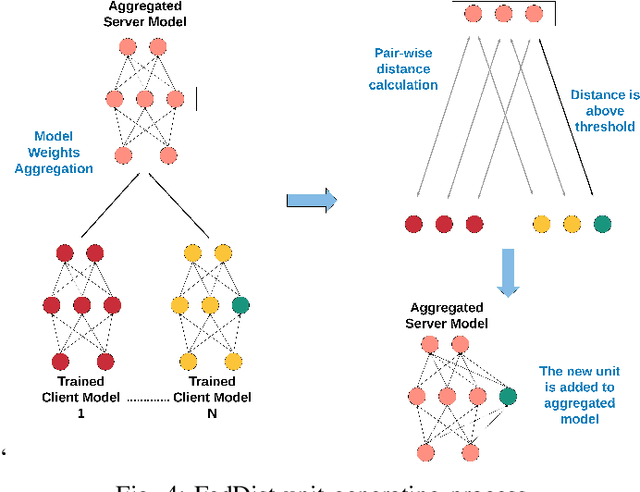
Pervasive computing promotes the installation of connected devices in our living spaces in order to provide services. Two major developments have gained significant momentum recently: an advanced use of edge resources and the integration of machine learning techniques for engineering applications. This evolution raises major challenges, in particular related to the appropriate distribution of computing elements along an edge-to-cloud continuum. About this, Federated Learning has been recently proposed for distributed model training in the edge. The principle of this approach is to aggregate models learned on distributed clients in order to obtain a new, more general model. The resulting model is then redistributed to clients for further training. To date, the most popular federated learning algorithm uses coordinate-wise averaging of the model parameters for aggregation. However, it has been shown that this method is not adapted in heterogeneous environments where data is not identically and independently distributed (non-iid). This corresponds directly to some pervasive computing scenarios where heterogeneity of devices and users challenges machine learning with the double objective of generalization and personalization. In this paper, we propose a novel aggregation algorithm, termed FedDist, which is able to modify its model architecture (here, deep neural network) by identifying dissimilarities between specific neurons amongst the clients. This permits to account for clients' specificity without impairing generalization. Furthermore, we define a complete method to evaluate federated learning in a realistic way taking generalization and personalization into account. Using this method, FedDist is extensively tested and compared with three state-of-the-art federated learning algorithms on the pervasive domain of Human Activity Recognition with smartphones.
A distillation-based approach integrating continual learning and federated learning for pervasive services
Sep 09, 2021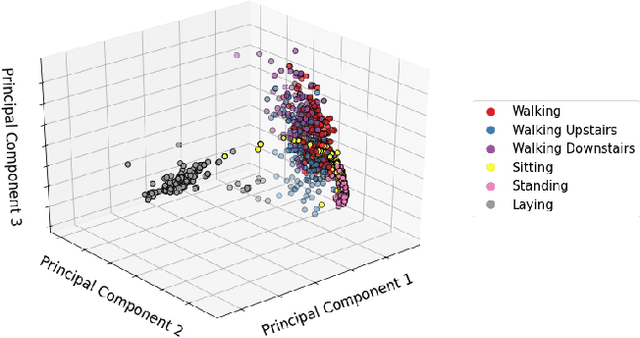
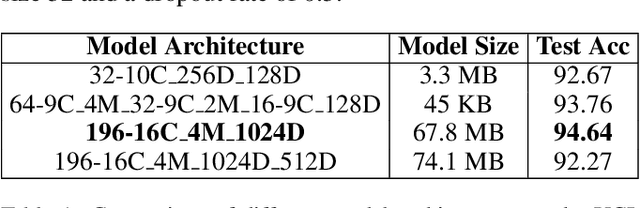
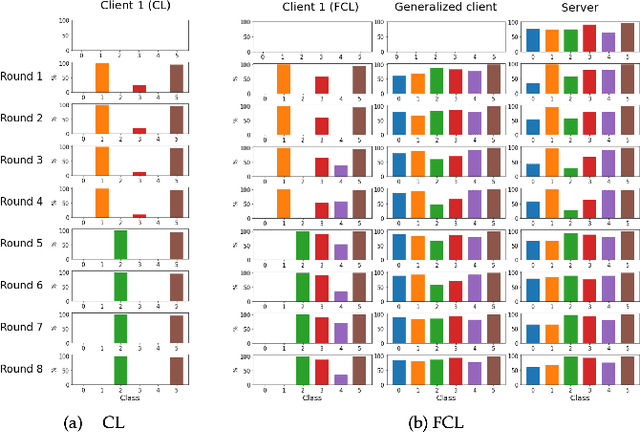
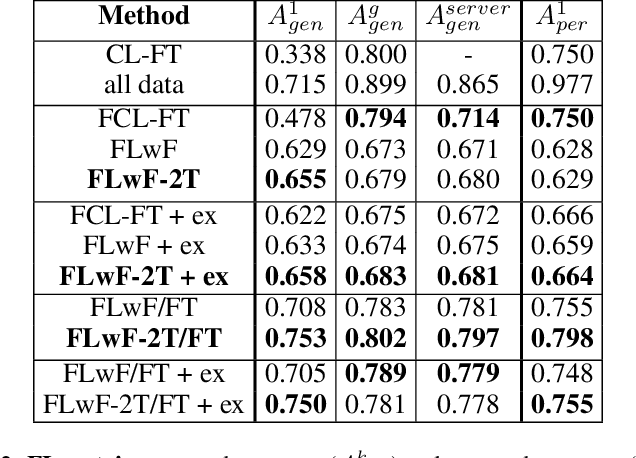
Federated Learning, a new machine learning paradigm enhancing the use of edge devices, is receiving a lot of attention in the pervasive community to support the development of smart services. Nevertheless, this approach still needs to be adapted to the specificity of the pervasive domain. In particular, issues related to continual learning need to be addressed. In this paper, we present a distillation-based approach dealing with catastrophic forgetting in federated learning scenario. Specifically, Human Activity Recognition tasks are used as a demonstration domain.