 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Question Answering on Heterogeneous Sources
Apr 25, 2022
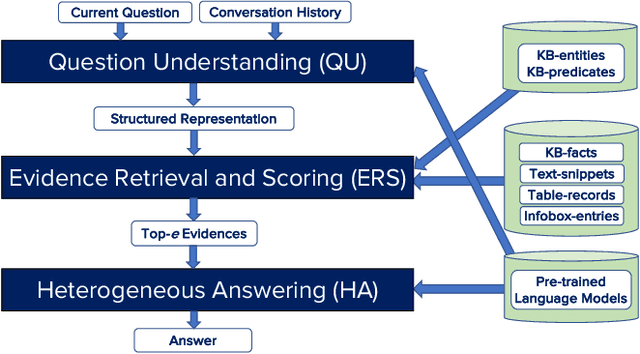
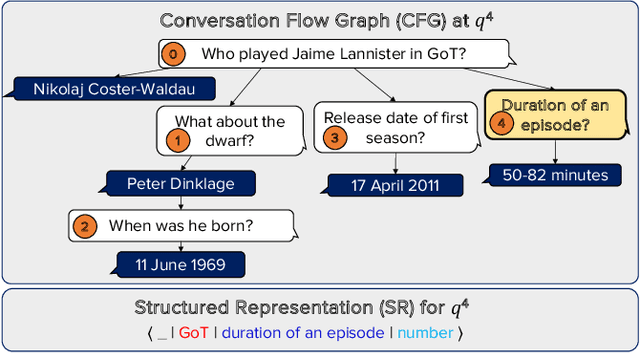

Conversational question answering (ConvQA) tackles sequential information needs where contexts in follow-up questions are left implicit. Current ConvQA systems operate over homogeneous sources of information: either a knowledge base (KB), or a text corpus, or a collection of tables. This paper addresses the novel issue of jointly tapping into all of these together, this way boosting answer coverage and confidence. We present CONVINSE, an end-to-end pipeline for ConvQA over heterogeneous sources, operating in three stages: i) learning an explicit structured representation of an incoming question and its conversational context, ii) harnessing this frame-like representation to uniformly capture relevant evidences from KB, text, and tables, and iii) running a fusion-in-decoder model to generate the answer. We construct and release the first benchmark, ConvMix, for ConvQA over heterogeneous sources, comprising 3000 real-user conversations with 16000 questions, along with entity annotations, completed question utterances, and question paraphrases. Experiments demonstrate the viability and advantages of our method, compared to state-of-the-art baselines.
Answering Count Queries with Explanatory Evidence
Apr 11, 2022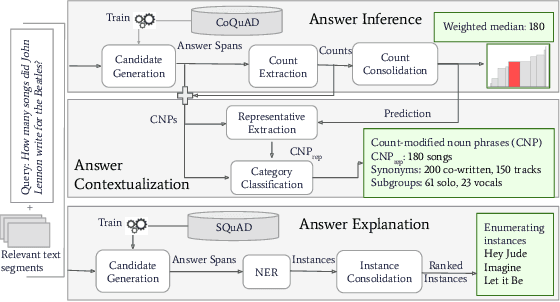
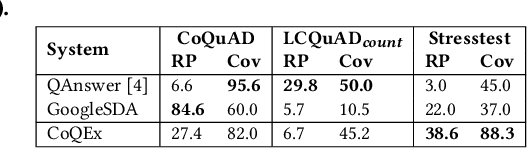
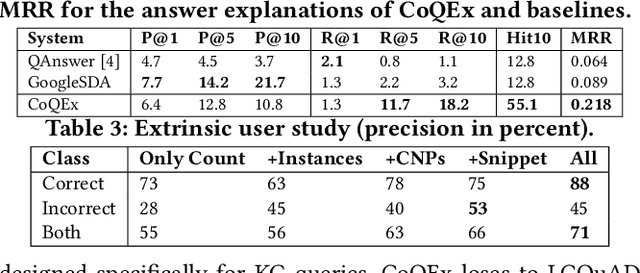
A challenging case in web search and question answering are count queries, such as \textit{"number of songs by John Lennon"}. Prior methods merely answer these with a single, and sometimes puzzling number or return a ranked list of text snippets with different numbers. This paper proposes a methodology for answering count queries with inference, contextualization and explanatory evidence. Unlike previous systems, our method infers final answers from multiple observations, supports semantic qualifiers for the counts, and provides evidence by enumerating representative instances. Experiments with a wide variety of queries show the benefits of our method. To promote further research on this underexplored topic, we release an annotated dataset of 5k queries with 200k relevant text spans.
Refined Commonsense Knowledge from Large-Scale Web Contents
Nov 30, 2021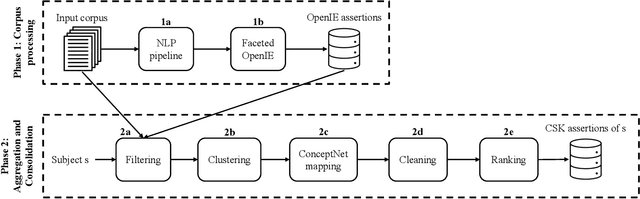
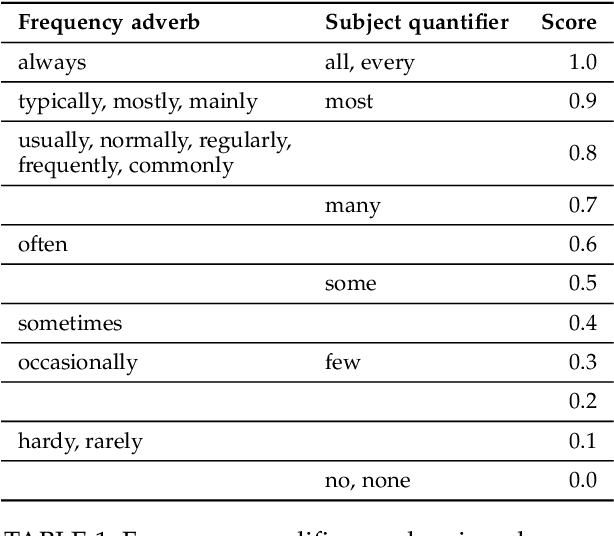
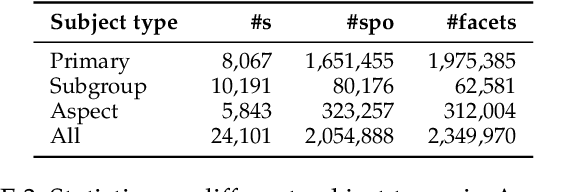
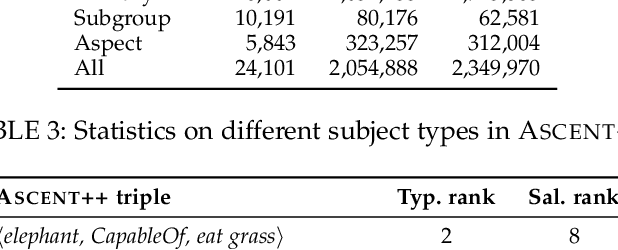
Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications. Prior works like ConceptNet, COMET and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and strings for P and O. This paper presents a method, called ASCENT++, to automatically build a large-scale knowledge base (KB) of CSK assertions, with refined expressiveness and both better precision and recall than prior works. ASCENT++ goes beyond SPO triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter is important to express the temporal and spatial validity of assertions and further qualifiers. ASCENT++ combines open information extraction with judicious cleaning and ranking by typicality and saliency scores. For high coverage, our method taps into the large-scale crawl C4 with broad web contents. The evaluation with human judgements shows the superior quality of the ASCENT++ KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of ASCENT++. A web interface, data and code can be accessed at https://www.mpi-inf.mpg.de/ascentpp.
Predicting Document Coverage for Relation Extraction
Nov 26, 2021
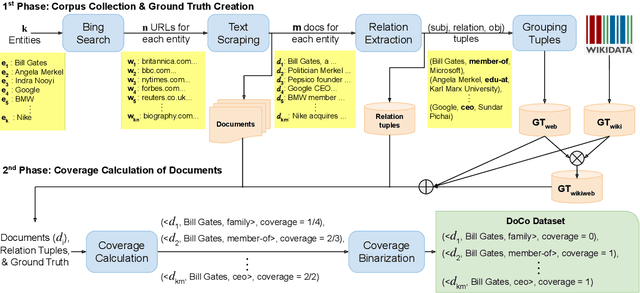
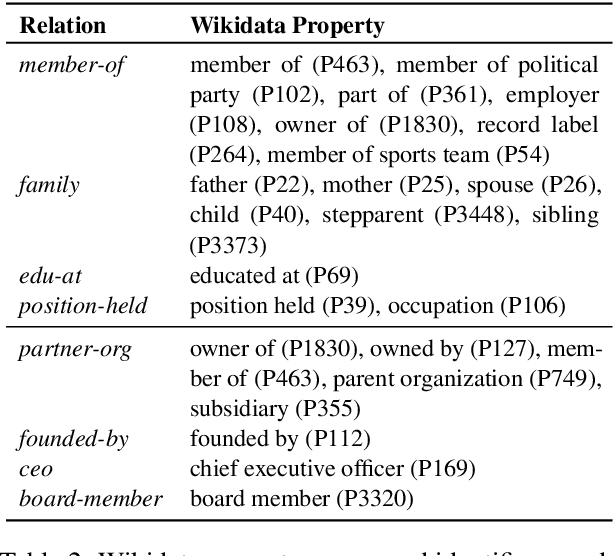
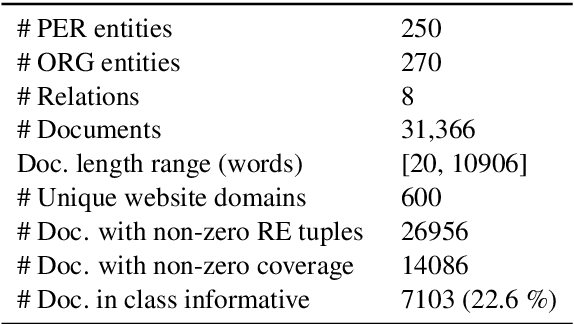
This paper presents a new task of predicting the coverage of a text document for relation extraction (RE): does the document contain many relational tuples for a given entity? Coverage predictions are useful in selecting the best documents for knowledge base construction with large input corpora. To study this problem, we present a dataset of 31,366 diverse documents for 520 entities. We analyze the correlation of document coverage with features like length, entity mention frequency, Alexa rank, language complexity and information retrieval scores. Each of these features has only moderate predictive power. We employ methods combining features with statistical models like TF-IDF and language models like BERT. The model combining features and BERT, HERB, achieves an F1 score of up to 46%. We demonstrate the utility of coverage predictions on two use cases: KB construction and claim refutation.
Language Models As or For Knowledge Bases
Oct 10, 2021
Pre-trained language models (LMs) have recently gained attention for their potential as an alternative to (or proxy for) explicit knowledge bases (KBs). In this position paper, we examine this hypothesis, identify strengths and limitations of both LMs and KBs, and discuss the complementary nature of the two paradigms. In particular, we offer qualitative arguments that latent LMs are not suitable as a substitute for explicit KBs, but could play a major role for augmenting and curating KBs.
Complex Temporal Question Answering on Knowledge Graphs
Sep 18, 2021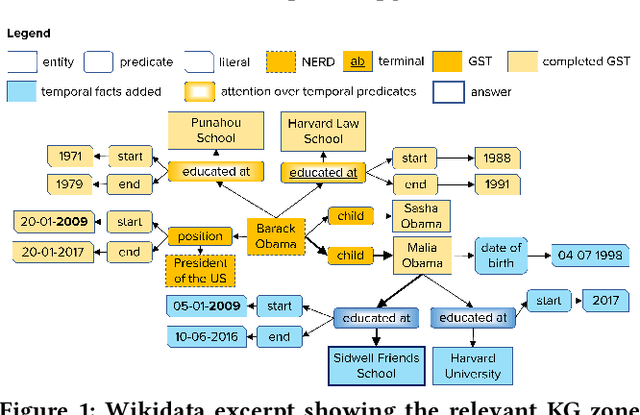

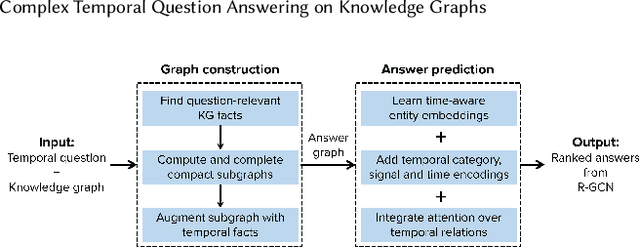
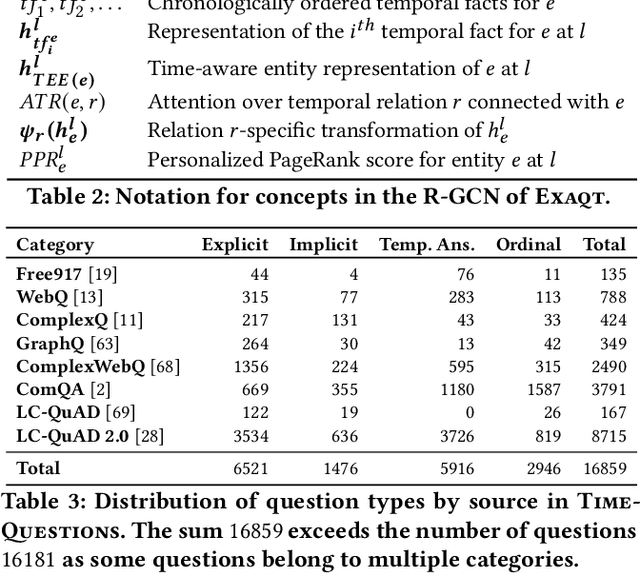
Question answering over knowledge graphs (KG-QA) is a vital topic in IR. Questions with temporal intent are a special class of practical importance, but have not received much attention in research. This work presents EXAQT, the first end-to-end system for answering complex temporal questions that have multiple entities and predicates, and associated temporal conditions. EXAQT answers natural language questions over KGs in two stages, one geared towards high recall, the other towards precision at top ranks. The first step computes question-relevant compact subgraphs within the KG, and judiciously enhances them with pertinent temporal facts, using Group Steiner Trees and fine-tuned BERT models. The second step constructs relational graph convolutional networks (R-GCNs) from the first step's output, and enhances the R-GCNs with time-aware entity embeddings and attention over temporal relations. We evaluate EXAQT on TimeQuestions, a large dataset of 16k temporal questions we compiled from a variety of general purpose KG-QA benchmarks. Results show that EXAQT outperforms three state-of-the-art systems for answering complex questions over KGs, thereby justifying specialized treatment of temporal QA.
You Get What You Chat: Using Conversations to Personalize Search-based Recommendations
Sep 10, 2021
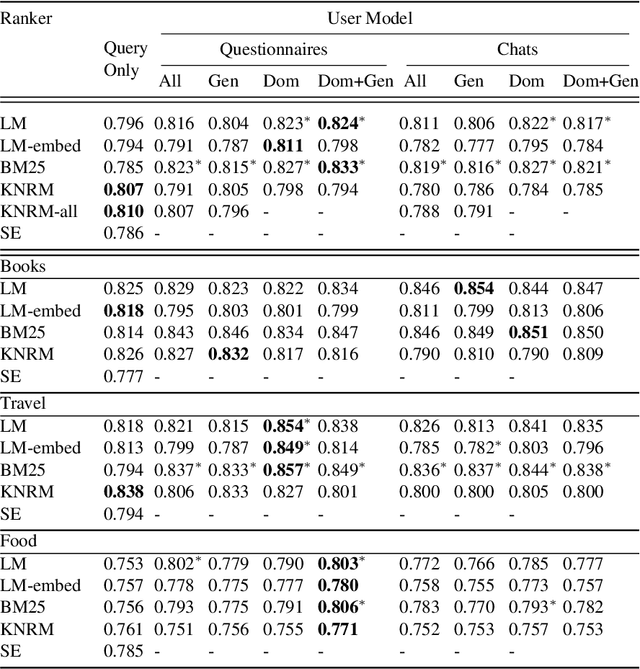
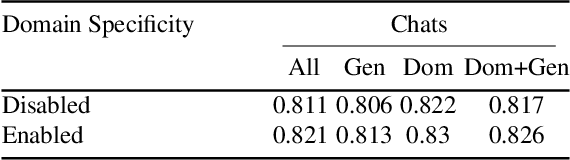
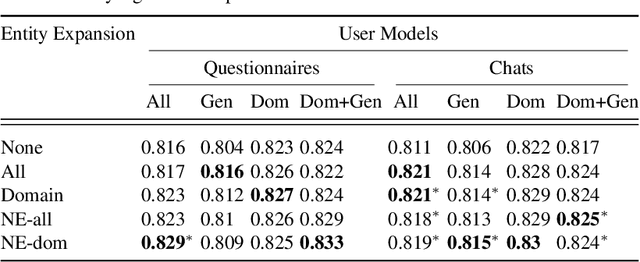
Prior work on personalized recommendations has focused on exploiting explicit signals from user-specific queries, clicks, likes, and ratings. This paper investigates tapping into a different source of implicit signals of interests and tastes: online chats between users. The paper develops an expressive model and effective methods for personalizing search-based entity recommendations. User models derived from chats augment different methods for re-ranking entity answers for medium-grained queries. The paper presents specific techniques to enhance the user models by capturing domain-specific vocabularies and by entity-based expansion. Experiments are based on a collection of online chats from a controlled user study covering three domains: books, travel, food. We evaluate different configurations and compare chat-based user models against concise user profiles from questionnaires. Overall, these two variants perform on par in terms of NCDG@20, but each has advantages in certain domains.
Personalized Entity Search by Sparse and Scrutable User Profiles
Sep 10, 2021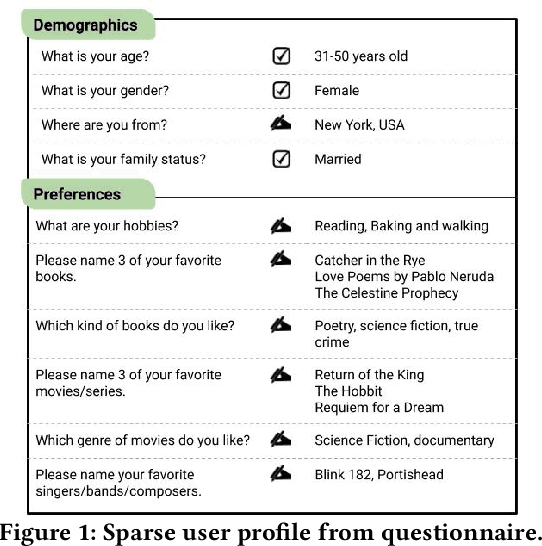
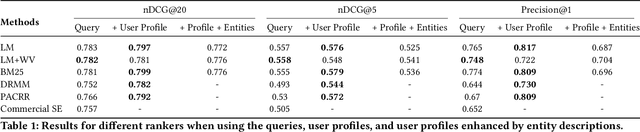
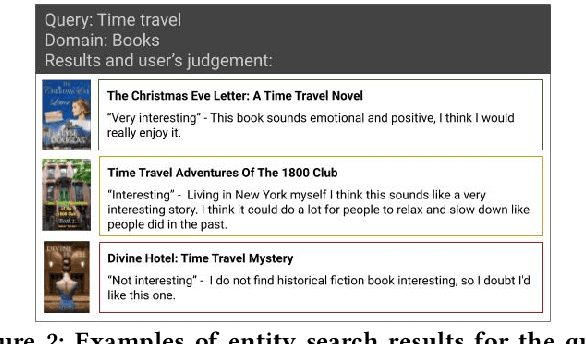
Prior work on personalizing web search results has focused on considering query-and-click logs to capture users individual interests. For product search, extensive user histories about purchases and ratings have been exploited. However, for general entity search, such as for books on specific topics or travel destinations with certain features, personalization is largely underexplored. In this paper, we address personalization of book search, as an exemplary case of entity search, by exploiting sparse user profiles obtained through online questionnaires. We devise and compare a variety of re-ranking methods based on language models or neural learning. Our experiments show that even very sparse information about individuals can enhance the effectiveness of the search results.
Detecting and Mitigating Test-time Failure Risks via Model-agnostic Uncertainty Learning
Sep 09, 2021
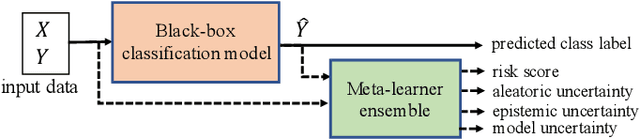

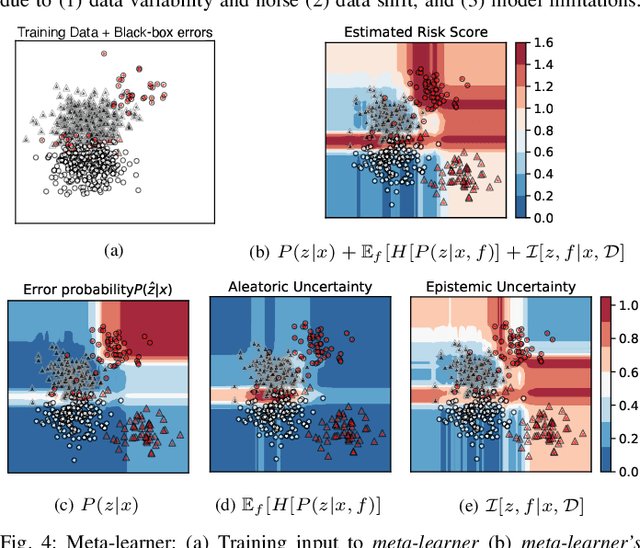
Reliably predicting potential failure risks of machine learning (ML) systems when deployed with production data is a crucial aspect of trustworthy AI. This paper introduces Risk Advisor, a novel post-hoc meta-learner for estimating failure risks and predictive uncertainties of any already-trained black-box classification model. In addition to providing a risk score, the Risk Advisor decomposes the uncertainty estimates into aleatoric and epistemic uncertainty components, thus giving informative insights into the sources of uncertainty inducing the failures. Consequently, Risk Advisor can distinguish between failures caused by data variability, data shifts and model limitations and advise on mitigation actions (e.g., collecting more data to counter data shift). Extensive experiments on various families of black-box classification models and on real-world and synthetic datasets covering common ML failure scenarios show that the Risk Advisor reliably predicts deployment-time failure risks in all the scenarios, and outperforms strong baselines.
Efficient Contextualization using Top-k Operators for Question Answering over Knowledge Graphs
Aug 21, 2021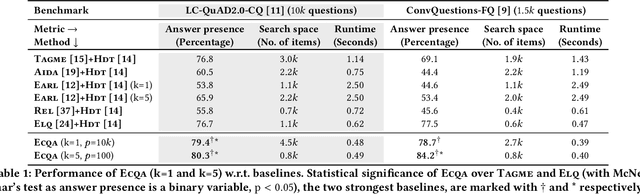
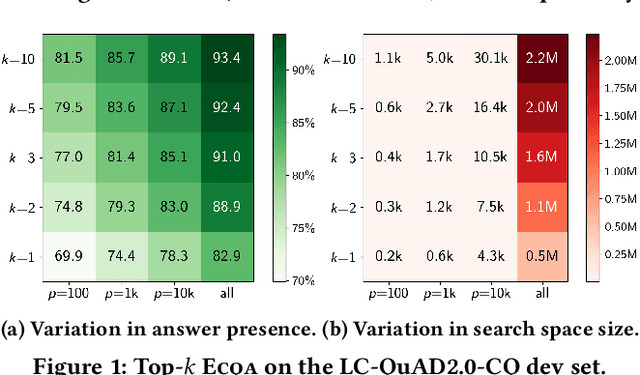
Answering complex questions over knowledge bases (KB-QA) faces huge input data with billions of facts, involving millions of entities and thousands of predicates. For efficiency, QA systems first reduce the answer search space by identifying a set of facts that is likely to contain all answers and relevant cues. The most common technique is to apply named entity disambiguation (NED) systems to the question, and retrieve KB facts for the disambiguated entities. This work presents ECQA, an efficient method that prunes irrelevant parts of the search space using KB-aware signals. ECQA is based on top-k query processing over score-ordered lists of KB items that combine signals about lexical matching, relevance to the question, coherence among candidate items, and connectivity in the KB graph. Experiments with two recent QA benchmarks demonstrate the superiority of ECQA over state-of-the-art baselines with respect to answer presence, size of the search space, and runtimes.