 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-Footprint Keyword Spotting on Raw Audio Data with Sinc-Convolutions
Nov 05, 2019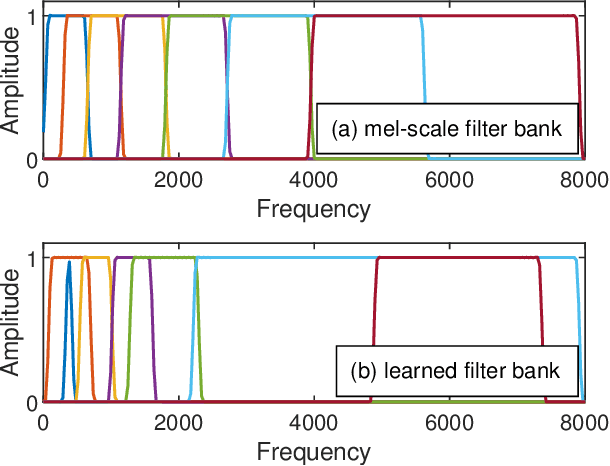
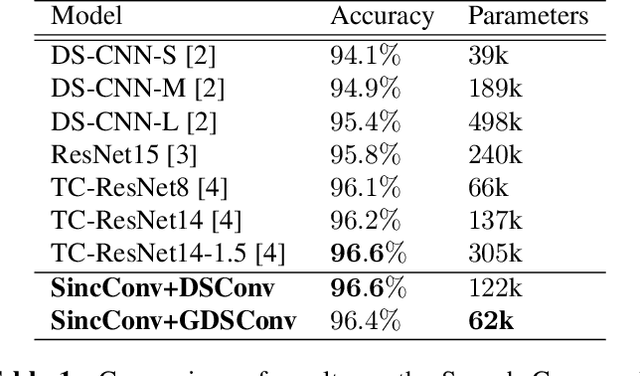
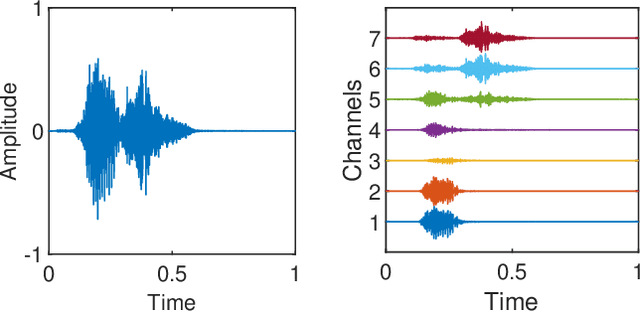

Keyword Spotting (KWS) enables speech-based user interaction on smart devices. Always-on and battery-powered application scenarios for smart devices put constraints on hardware resources and power consumption, while also demanding high accuracy as well as real-time capability. Previous architectures first extracted acoustic features and then applied a neural network to classify keyword probabilities, optimizing towards memory footprint and execution time. Compared to previous publications, we took additional steps to reduce power and memory consumption without reducing classification accuracy. Power-consuming audio preprocessing and data transfer steps are eliminated by directly classifying from raw audio. For this, our end-to-end architecture extracts spectral features using parametrized Sinc-convolutions. Its memory footprint is further reduced by grouping depthwise separable convolutions. Our network achieves the competitive accuracy of 96.4% on Google's Speech Commands test set with only 62k parameters.
Comparative Analysis of CNN-based Spatiotemporal Reasoning in Videos
Sep 11, 2019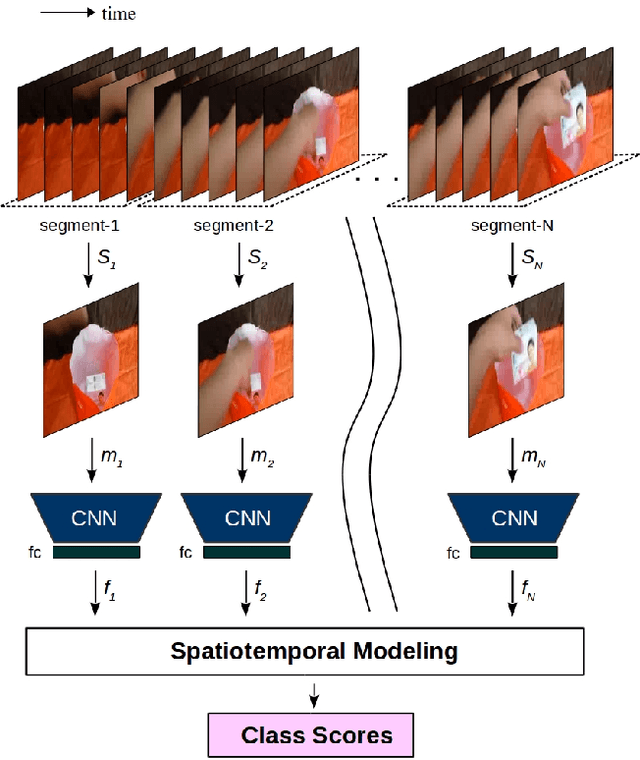
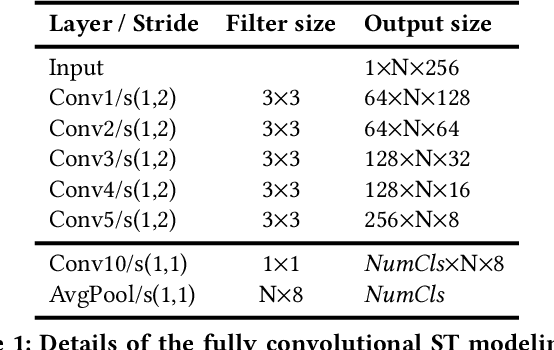
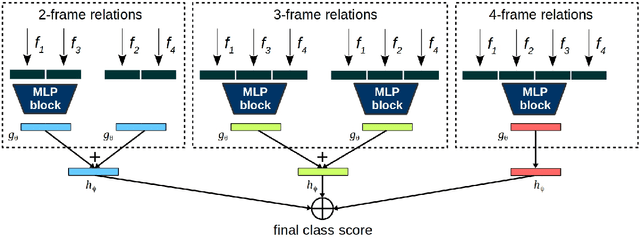
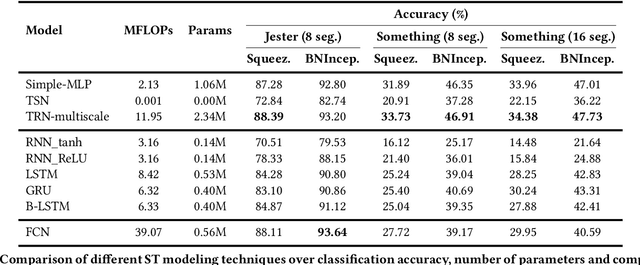
Understanding actions and gestures in video streams requires temporal reasoning of the spatial content from different time instants, i.e., spatiotemporal (ST) modeling. In this paper, we have made a comparative analysis of different ST modeling techniques. Since convolutional neural networks (CNNs) are proved to be an effective tool as a feature extractor for static images, we apply ST modeling techniques on the features of static images from different time instants extracted by CNNs. All techniques are trained end-to-end together with a CNN feature extraction part and evaluated on two publicly available benchmarks: The Jester and the Something-Something dataset. The Jester dataset contains various dynamic and static hand gestures, whereas the Something-Something dataset contains actions of human-object interactions. The common characteristic of these two benchmarks is that the designed architectures need to capture the full temporal content of the actions/gestures in the correct order. Contrary to expectations, experimental results show that recurrent neural network (RNN) based ST modeling techniques yield inferior results compared to other techniques such as fully convolutional architectures. Codes and pretrained models of this work are publicly available.
Real-Time Driver State Monitoring Using a CNN Based Spatio-Temporal Approach
Jul 18, 2019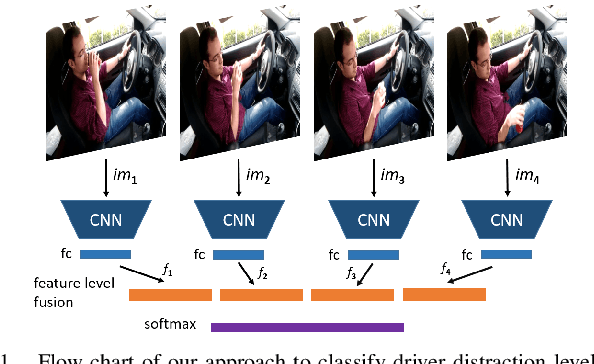


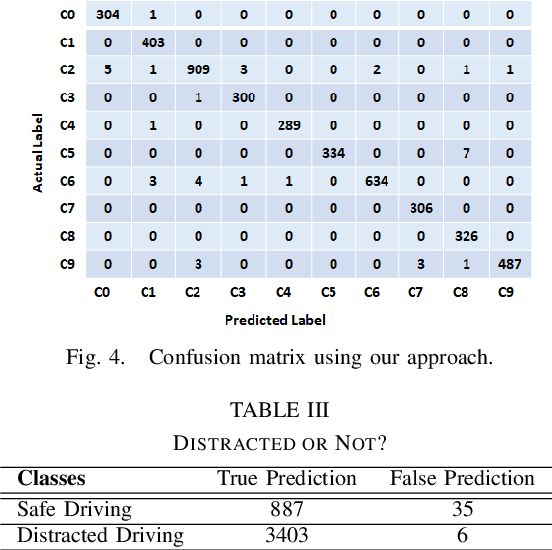
Many road accidents occur due to distracted drivers. Today, driver monitoring is essential even for the latest autonomous vehicles to alert distracted drivers in order to take over control of the vehicle in case of emergency. In this paper, a spatio-temporal approach is applied to classify drivers' distraction level and movement decisions using convolutional neural networks (CNNs). We approach this problem as action recognition to benefit from temporal information in addition to spatial information. Our approach relies on features extracted from sparsely selected frames of an action using a pre-trained BN-Inception network. Experiments show that our approach outperforms the state-of-the art results on the Distracted Driver Dataset (96.31%), with an accuracy of 99.10% for 10-class classification while providing real-time performance. We also analyzed the impact of fusion using RGB and optical flow modalities with a very recent data level fusion strategy. The results on the Distracted Driver and Brain4Cars datasets show that fusion of these modalities further increases the accuracy.
On Flow Profile Image for Video Representation
May 12, 2019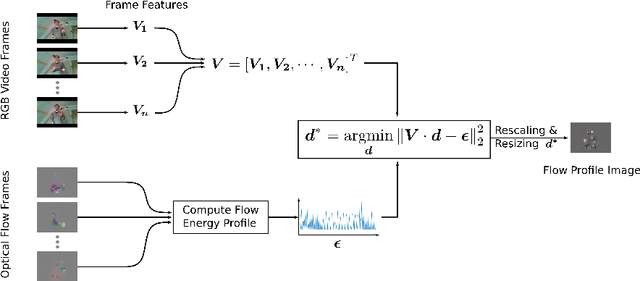
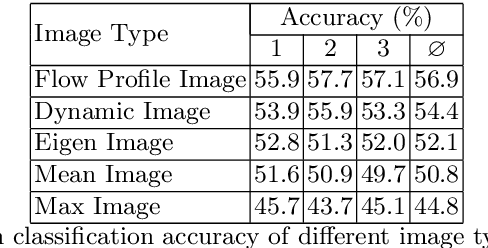

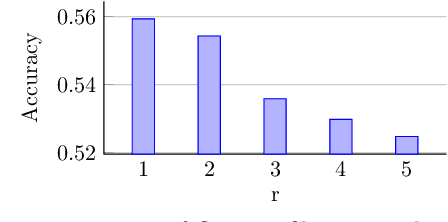
Video representation is a key challenge in many computer vision applications such as video classification, video captioning, and video surveillance. In this paper, we propose a novel approach for video representation that captures meaningful information including motion and appearance from a sequence of video frames and compacts it into a single image. To this end, we compute the optical flow and use it in a least squares optimization to find a new image, the so-called Flow Profile Image (FPI). This image encodes motions as well as foreground appearance information while background information is removed. The quality of this image is validated in activity recognition experiments and the results are compared with other video representation techniques such as dynamic images [1] and eigen images [2]. The experimental results as well as visual quality confirm that FPIs can be successfully used in video processing applications.
Talking with Your Hands: Scaling Hand Gestures and Recognition with CNNs
May 10, 2019
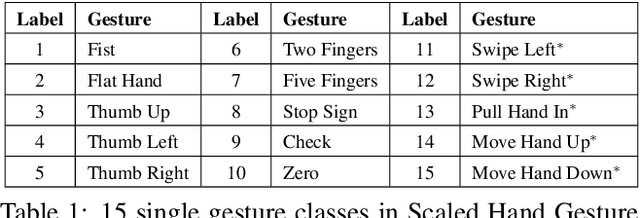


The use of hand gestures provides a natural alternative to cumbersome interface devices for Human-Computer Interaction (HCI) systems. As the technology advances and communication between humans and machines becomes more complex, HCI systems should also be scaled accordingly in order to accommodate the introduced complexities. In this paper, we propose a methodology to scale hand gestures by forming them with predefined gesture-phonemes, and a convolutional neural network (CNN) based framework to recognize hand gestures by learning only their constituents of gesture-phonemes. The total number of possible hand gestures can be increased exponentially by increasing the number of used gesture-phonemes. For this objective, we introduce a new benchmark dataset named Scaled Hand Gestures Dataset (SHGD) with only gesture-phonemes in its training set and 3-tuples gestures in the test set. In our experimental analysis, we achieve to recognize hand gestures containing one and three gesture-phonemes with an accuracy of 98.47% (in 15 classes) and 94.69% (in 810 classes), respectively. Our dataset, code and pretrained models are publicly available.
Resource Efficient 3D Convolutional Neural Networks
Apr 27, 2019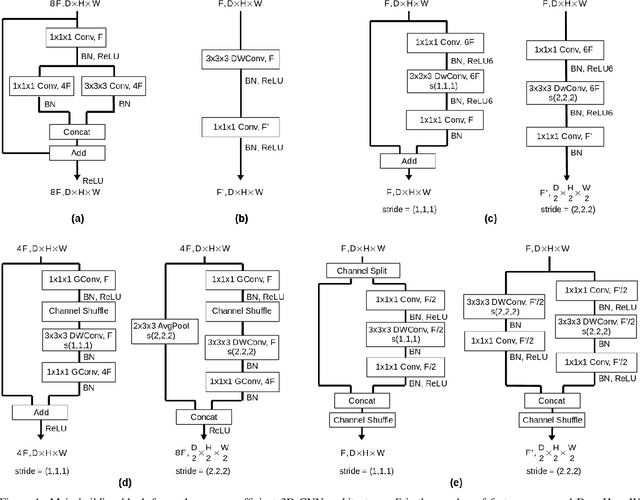
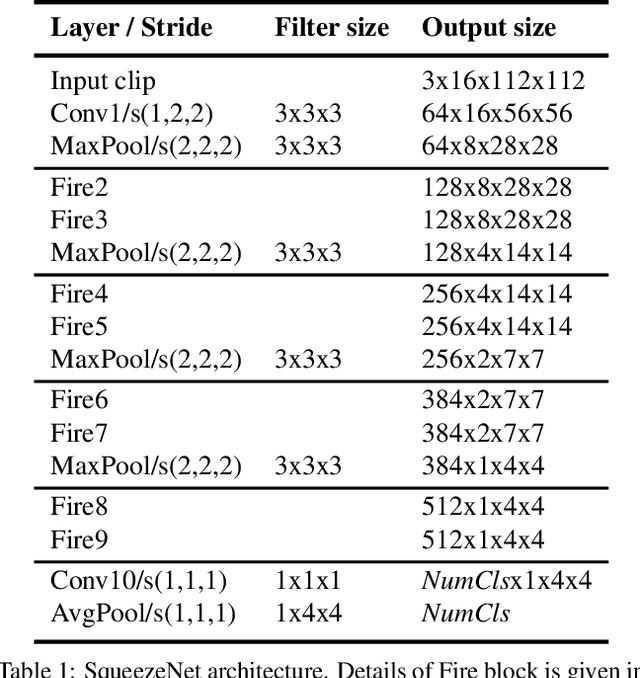
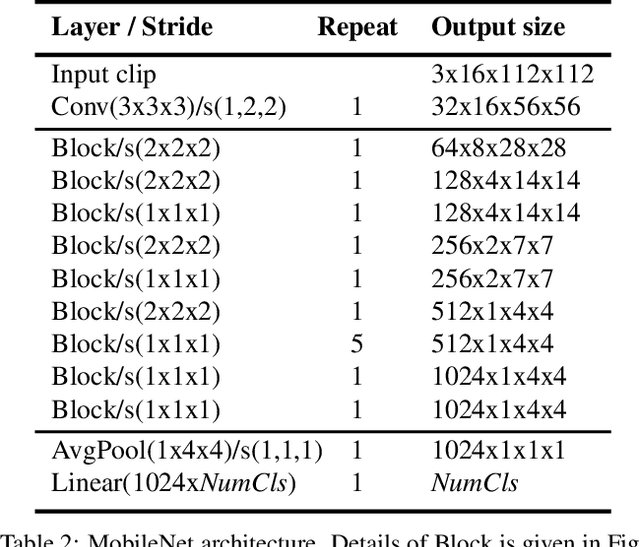
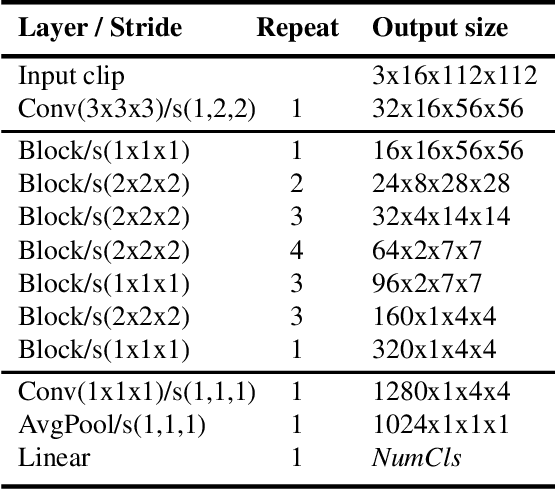
Recently, convolutional neural networks with 3D kernels (3D CNNs) have been very popular in computer vision community as a result of their superior ability of extracting spatio-temporal features within video frames compared to 2D CNNs. Although, there has been great advances recently to build resource efficient 2D CNN architectures considering memory and power budget, there is hardly any similar resource efficient architectures for 3D CNNs. In this paper, we have converted various well-known resource efficient 2D CNNs to 3D CNNs and evaluated their performance on three major benchmarks in terms of classification accuracy for different complexity levels. We have experimented on (1) Kinetics-600 dataset to inspect their capacity to learn, (2) Jester dataset to inspect their ability to capture hand motion patterns, and (3) UCF-101 to inspect the applicability of transfer learning. We have evaluated the run-time performance of each model on a single GPU and an embedded GPU. The results of this study show that these models can be utilized for different types of real-world applications since they provide real-time performance with considerable accuracies and memory usage. Our analysis on different complexity levels shows that the resource efficient 3D CNNs should not be designed too shallow or narrow in order to save complexity. The codes and pretrained models used in this work are publicly available.
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Feb 05, 2019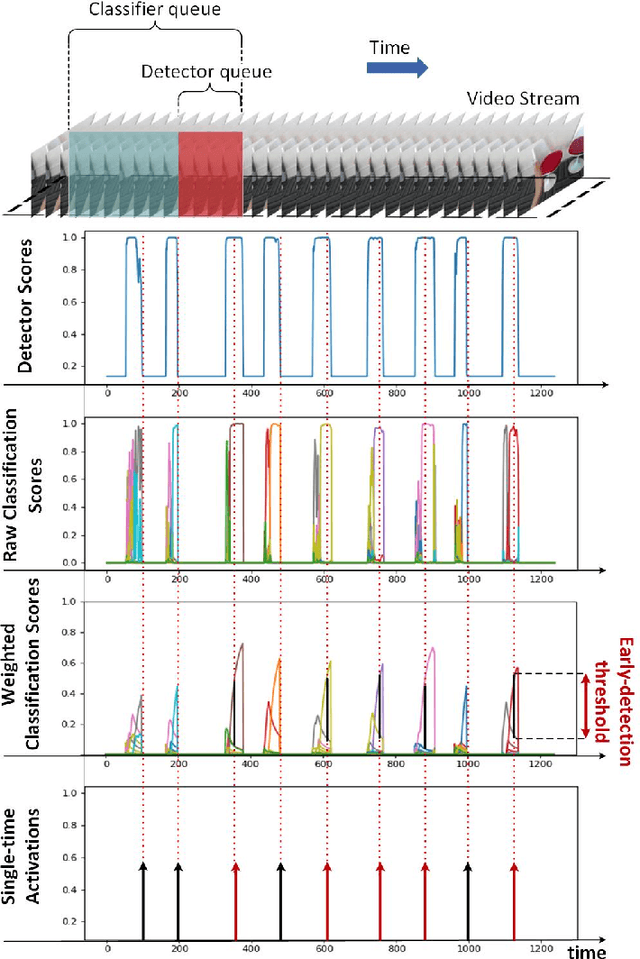
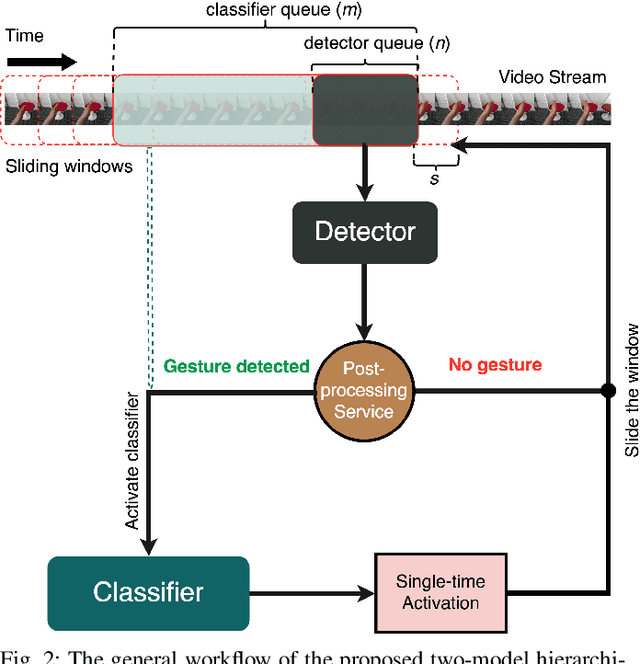
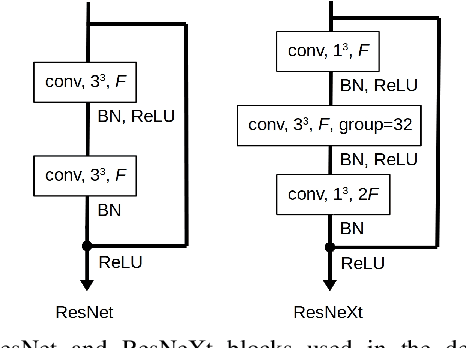
Real-time recognition of dynamic hand gestures from video streams is a challenging task since (i) there is no indication when a gesture starts and ends in the video, (ii) performed gestures should only be recognized once, and (iii) the entire architecture should be designed considering the memory and power budget. In this work, we address these challenges by proposing a hierarchical structure enabling offline-working convolutional neural network (CNN) architectures to operate online efficiently by using sliding window approach. The proposed architecture consists of two models: (1) A detector which is a lightweight CNN architecture to detect gestures and (2) a classifier which is a deep CNN to classify the detected gestures. In order to evaluate the single-time activations of the detected gestures, we propose to use Levenshtein distance as an evaluation metric since it can measure misclassifications, multiple detections, and missing detections at the same time. We evaluate our architecture on two publicly available datasets - EgoGesture and NVIDIA Dynamic Hand Gesture Datasets - which require temporal detection and classification of the performed hand gestures. ResNeXt-101 model, which is used as a classifier, achieves the state-of-the-art offline classification accuracy of 94.04% and 83.82% for depth modality on EgoGesture and NVIDIA benchmarks, respectively. In real-time detection and classification, we obtain considerable early detections while achieving performances close to offline operation. The codes and pretrained models used in this work are publicly available.
Convolutional Neural Networks with Layer Reuse
Feb 01, 2019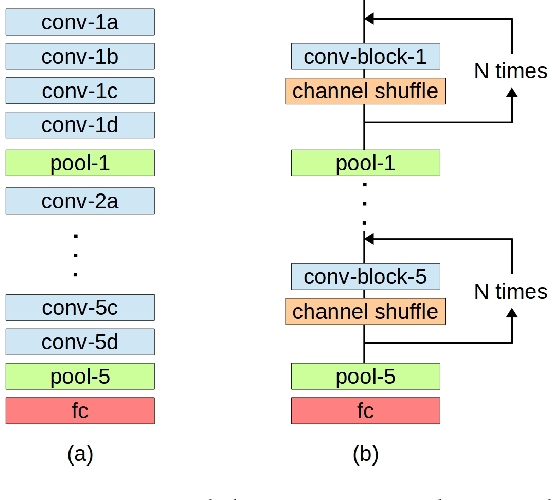
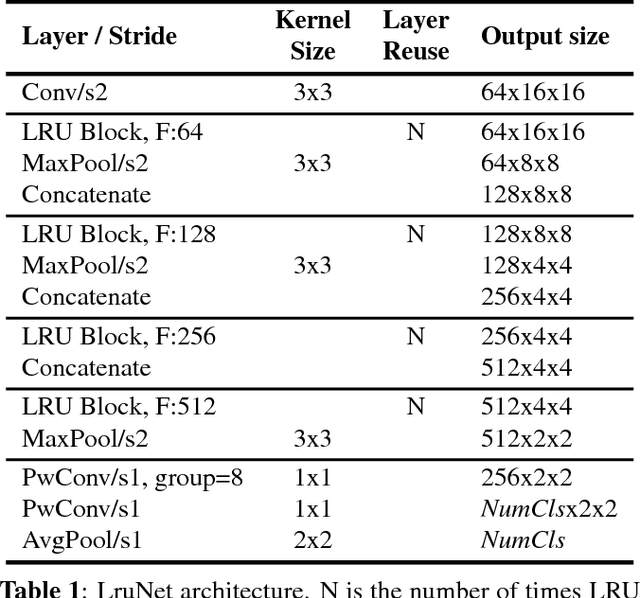

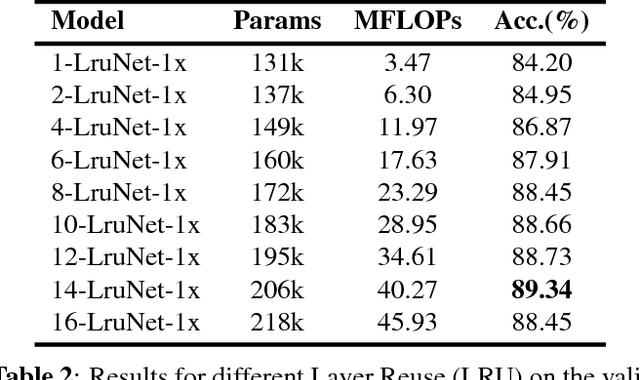
A convolutional layer in a Convolutional Neural Network (CNN) consists of many filters which apply convolution operation to the input, capture some special patterns and pass the result to the next layer. If the same patterns also occur at the deeper layers of the network, why wouldn't the same convolutional filters be used also in those layers? In this paper, we propose a CNN architecture, Layer Reuse Network (LruNet), where the convolutional layers are used repeatedly without the need of introducing new layers to get a better performance. This approach introduces several advantages: (i) Considerable amount of parameters are saved since we are reusing the layers instead of introducing new layers, (ii) the Memory Access Cost (MAC) can be reduced since reused layer parameters can be fetched only once, (iii) the number of nonlinearities increases with layer reuse, and (iv) reused layers get gradient updates from multiple parts of the network. The proposed approach is evaluated on CIFAR-10, CIFAR-100 and Fashion-MNIST datasets for image classification task, and layer reuse improves the performance by 5.14%, 5.85% and 2.29%, respectively. The source code and pretrained models are publicly available.
Multiple People Tracking Using Hierarchical Deep Tracklet Re-identification
Nov 17, 2018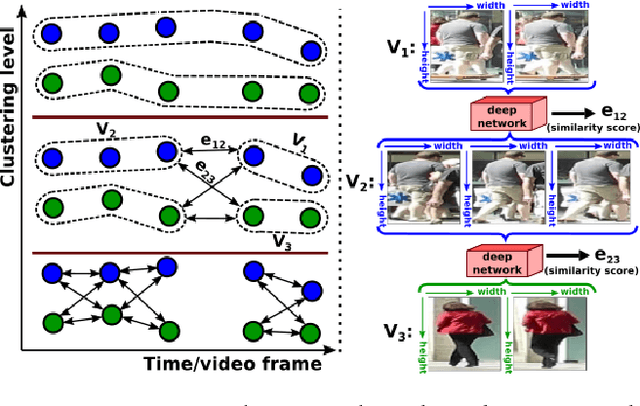
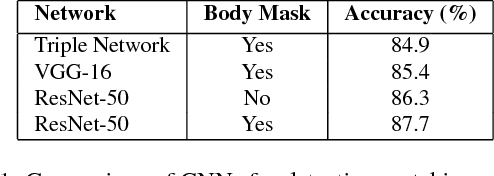
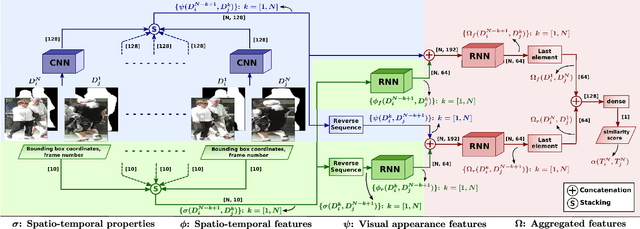
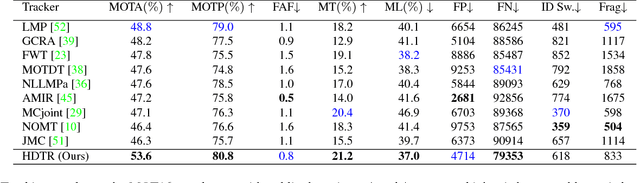
The task of multiple people tracking in monocular videos is challenging because of the numerous difficulties involved: occlusions, varying environments, crowded scenes, camera parameters and motion. In the tracking-by-detection paradigm, most approaches adopt person re-identification techniques based on computing the pairwise similarity between detections. However, these techniques are less effective in handling long-term occlusions. By contrast, tracklet (a sequence of detections) re-identification can improve association accuracy since tracklets offer a richer set of visual appearance and spatio-temporal cues. In this paper, we propose a tracking framework that employs a hierarchical clustering mechanism for merging tracklets. To this end, tracklet re-identification is performed by utilizing a novel multi-stage deep network that can jointly reason about the visual appearance and spatio-temporal properties of a pair of tracklets, thereby providing a robust measure of affinity. Experimental results on the challenging MOT16 and MOT17 benchmarks show that our method significantly outperforms state-of-the-arts.
Motion Fused Frames: Data Level Fusion Strategy for Hand Gesture Recognition
Apr 26, 2018

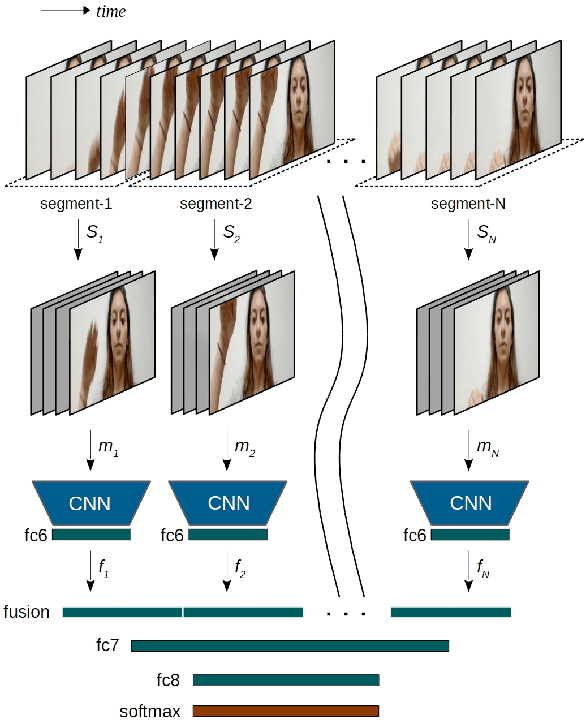
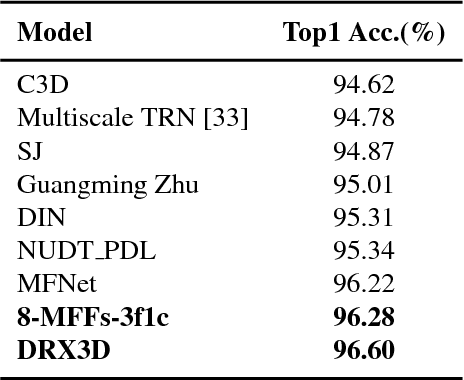
Acquiring spatio-temporal states of an action is the most crucial step for action classification. In this paper, we propose a data level fusion strategy, Motion Fused Frames (MFFs), designed to fuse motion information into static images as better representatives of spatio-temporal states of an action. MFFs can be used as input to any deep learning architecture with very little modification on the network. We evaluate MFFs on hand gesture recognition tasks using three video datasets - Jester, ChaLearn LAP IsoGD and NVIDIA Dynamic Hand Gesture Datasets - which require capturing long-term temporal relations of hand movements. Our approach obtains very competitive performance on Jester and ChaLearn benchmarks with the classification accuracies of 96.28% and 57.4%, respectively, while achieving state-of-the-art performance with 84.7% accuracy on NVIDIA benchmark.