 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Robust Contribution Evaluation in Federated Learning
Feb 25, 2026Cross-silo federated learning allows multiple organizations to collaboratively train machine learning models without sharing raw data, but client updates can still leak sensitive information through inference attacks. Secure aggregation protects privacy by hiding individual updates, yet it complicates contribution evaluation, which is critical for fair rewards and detecting low-quality or malicious participants. Existing marginal-contribution methods, such as the Shapley value, are incompatible with secure aggregation, and practical alternatives, such as Leave-One-Out, are crude and rely on self-evaluation. We introduce two marginal-difference contribution scores compatible with secure aggregation. Fair-Private satisfies standard fairness axioms, while Everybody-Else eliminates self-evaluation and provides resistance to manipulation, addressing a largely overlooked vulnerability. We provide theoretical guarantees for fairness, privacy, robustness, and computational efficiency, and evaluate our methods on multiple medical image datasets and CIFAR10 in cross-silo settings. Our scores consistently outperform existing baselines, better approximate Shapley-induced client rankings, and improve downstream model performance as well as misbehavior detection. These results demonstrate that fairness, privacy, robustness, and practical utility can be achieved jointly in federated contribution evaluation, offering a principled solution for real-world cross-silo deployments.
Automatic Driver Identification from In-Vehicle Network Logs
Oct 25, 2019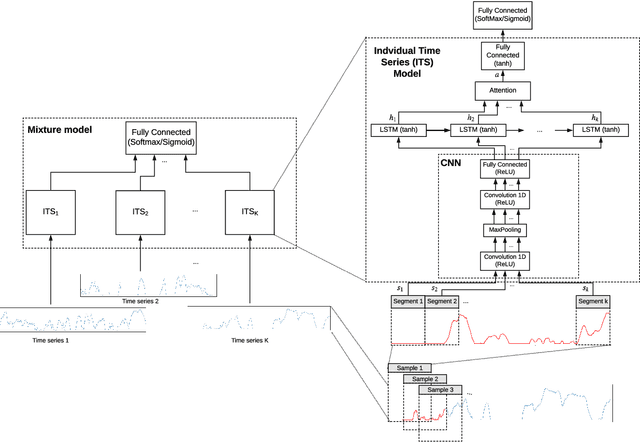
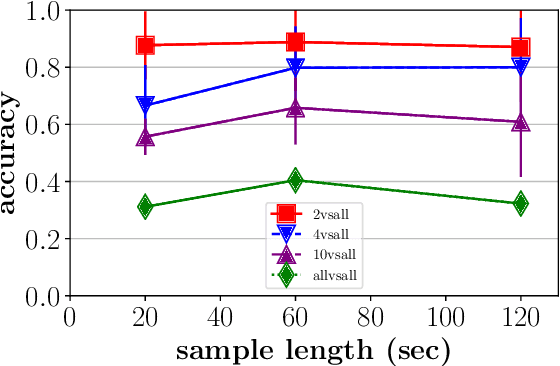
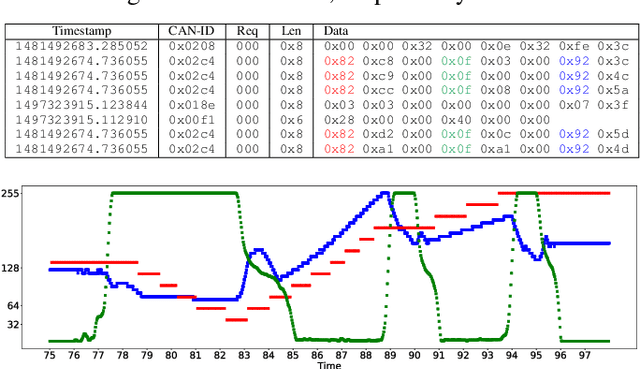
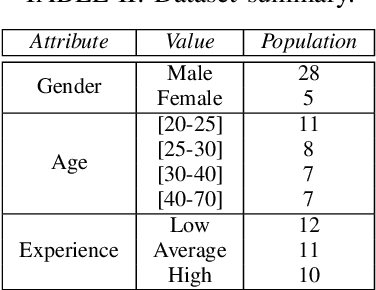
Data generated by cars is growing at an unprecedented scale. As cars gradually become part of the Internet of Things (IoT) ecosystem, several stakeholders discover the value of in-vehicle network logs containing the measurements of the multitude of sensors deployed within the car. This wealth of data is also expected to be exploitable by third parties for the purpose of profiling drivers in order to provide personalized, valueadded services. Although several prior works have successfully demonstrated the feasibility of driver re-identification using the in-vehicle network data captured on the vehicle's CAN (Controller Area Network) bus, they inferred the identity of the driver only from known sensor signals (such as the vehicle's speed, brake pedal position, steering wheel angle, etc.) extracted from the CAN messages. However, car manufacturers intentionally do not reveal exact signal location and semantics within CAN logs. We show that the inference of driver identity is possible even with off-the-shelf machine learning techniques without reverse-engineering the CAN protocol. We demonstrate our approach on a dataset of 33 drivers and show that a driver can be re-identified and distinguished from other drivers with an accuracy of 75-85%.