 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Catastrophic Forgetting in Continual Knowledge Graph Embedding
Apr 21, 2026Knowledge Graph Embeddings (KGEs) support a wide range of downstream tasks over Knowledge Graphs (KGs). In practice, KGs evolve as new entities and facts are added, motivating Continual Knowledge Graph Embedding (CKGE) methods that update embeddings over time. Current CKGE approaches address catastrophic forgetting (i.e., the performance degradation on previously learned tasks) primarily by limiting changes to existing embeddings. However, we show that this view is incomplete. When new entities are introduced, their embeddings can interfere with previously learned ones, causing the model to predict them in place of previously correct answers. This phenomenon, which we call entity interference, has been largely overlooked and is not accounted for in current CKGE evaluation protocols. As a result, the assessment of catastrophic forgetting becomes misleading, and CKGE methods performance is systematically overestimated. To address this issue, we introduce a corrected CKGE evaluation protocol that accounts for entity interference. Through experiments on multiple benchmarks, we show that ignoring this effect can lead to performance overestimation of up to 25%, particularly in scenarios with significant entity growth. We further analyze how different CKGE methods and KGE models are affected by the different sources of forgetting, and introduce a catastrophic forgetting metric tailored to CKGE.
Improving Continual Learning of Knowledge Graph Embeddings via Informed Initialization
Nov 14, 2025Many Knowledege Graphs (KGs) are frequently updated, forcing their Knowledge Graph Embeddings (KGEs) to adapt to these changes. To address this problem, continual learning techniques for KGEs incorporate embeddings for new entities while updating the old ones. One necessary step in these methods is the initialization of the embeddings, as an input to the KGE learning process, which can have an important impact in the accuracy of the final embeddings, as well as in the time required to train them. This is especially relevant for relatively small and frequent updates. We propose a novel informed embedding initialization strategy, which can be seamlessly integrated into existing continual learning methods for KGE, that enhances the acquisition of new knowledge while reducing catastrophic forgetting. Specifically, the KG schema and the previously learned embeddings are utilized to obtain initial representations for the new entities, based on the classes the entities belong to. Our extensive experimental analysis shows that the proposed initialization strategy improves the predictive performance of the resulting KGEs, while also enhancing knowledge retention. Furthermore, our approach accelerates knowledge acquisition, reducing the number of epochs, and therefore time, required to incrementally learn new embeddings. Finally, its benefits across various types of KGE learning models are demonstrated.
Capturing and Anticipating User Intents in Data Analytics via Knowledge Graphs
Nov 01, 2024



In today's data-driven world, the ability to extract meaningful information from data is becoming essential for businesses, organizations and researchers alike. For that purpose, a wide range of tools and systems exist addressing data-related tasks, from data integration, preprocessing and modeling, to the interpretation and evaluation of the results. As data continues to grow in volume, variety, and complexity, there is an increasing need for advanced but user-friendly tools, such as intelligent discovery assistants (IDAs) or automated machine learning (AutoML) systems, that facilitate the user's interaction with the data. This enables non-expert users, such as citizen data scientists, to leverage powerful data analytics techniques effectively. The assistance offered by IDAs or AutoML tools should not be guided only by the analytical problem's data but should also be tailored to each individual user. To this end, this work explores the usage of Knowledge Graphs (KG) as a basic framework for capturing in a human-centered manner complex analytics workflows, by storing information not only about the workflow's components, datasets and algorithms but also about the users, their intents and their feedback, among others. The data stored in the generated KG can then be exploited to provide assistance (e.g., recommendations) to the users interacting with these systems. To accomplish this objective, two methods are explored in this work. Initially, the usage of query templates to extract relevant information from the KG is studied. However, upon identifying its main limitations, the usage of link prediction with knowledge graph embeddings is explored, which enhances flexibility and allows leveraging the entire structure and components of the graph. The experiments show that the proposed method is able to capture the graph's structure and to produce sensible suggestions.
VICSOM: VIsual Clues from SOcial Media for psychological assessment
May 15, 2019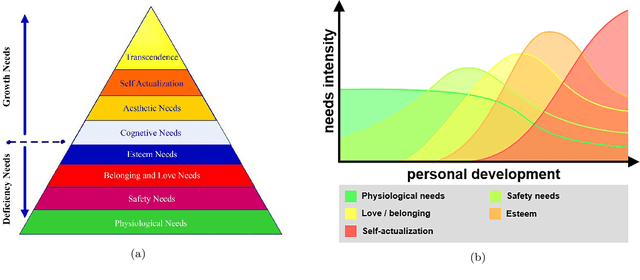
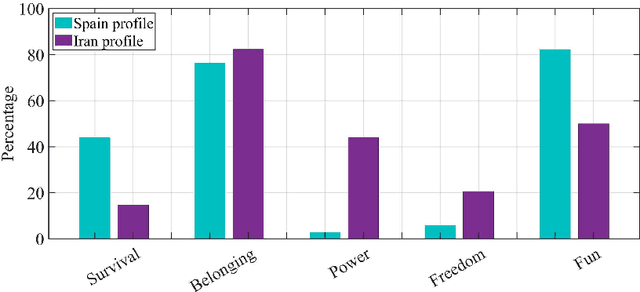
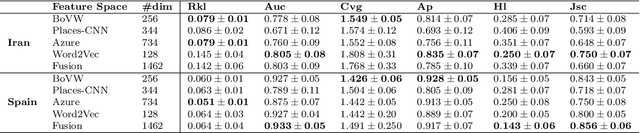

Sharing multimodal information (typically images, videos or text) in Social Network Sites (SNS) occupies a relevant part of our time. The particular way how users expose themselves in SNS can provide useful information to infer human behaviors. This paper proposes to use multimodal data gathered from Instagram accounts to predict the perceived prototypical needs described in Glasser's choice theory. The contribution is two-fold: (i) we provide a large multimodal database from Instagram public profiles (more than 30,000 images and text captions) annotated by expert Psychologists on each perceived behavior according to Glasser's theory, and (ii) we propose to automate the recognition of the (unconsciously) perceived needs by the users. Particularly, we propose a baseline using three different feature sets: visual descriptors based on pixel images (SURF and Visual Bag of Words), a high-level descriptor based on the automated scene description using Convolutional Neural Networks, and a text-based descriptor (Word2vec) obtained from processing the captions provided by the users. Finally, we propose a multimodal fusion of these descriptors obtaining promising results in the multi-label classification problem.
Multi-task, multi-label and multi-domain learning with residual convolutional networks for emotion recognition
Feb 19, 2018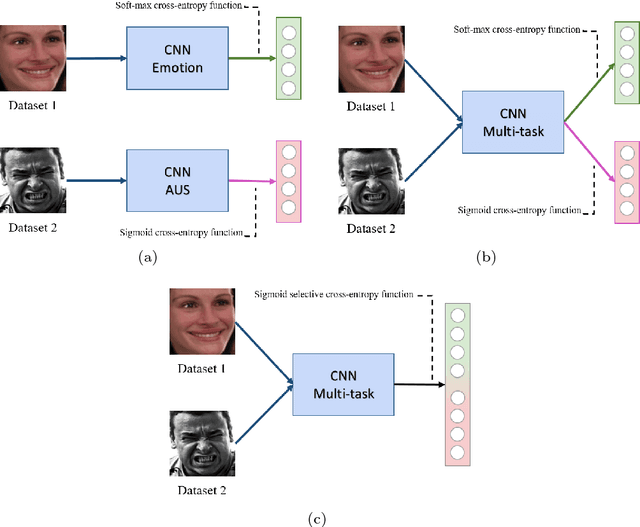
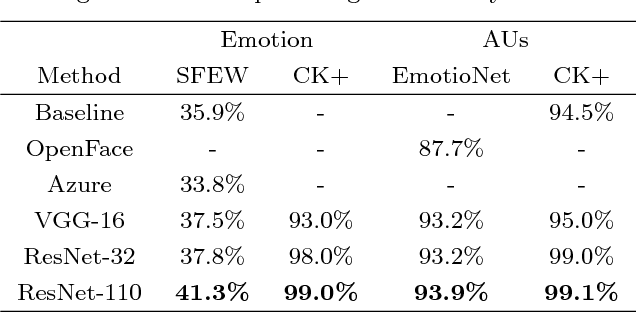
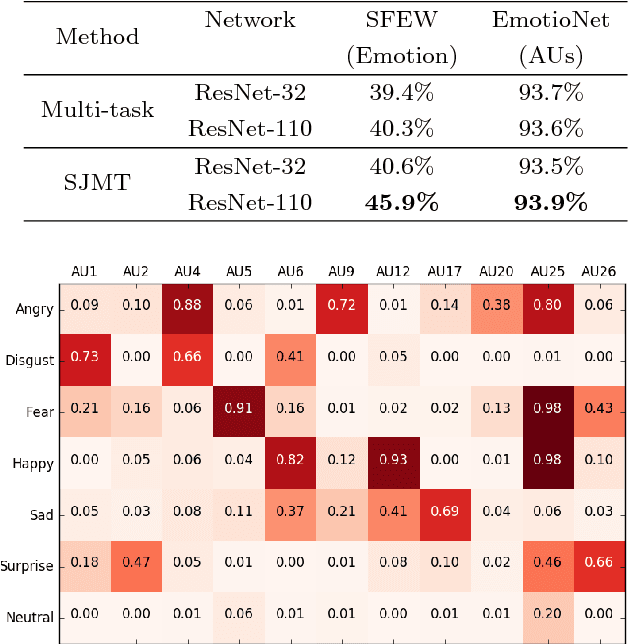

Automated emotion recognition in the wild from facial images remains a challenging problem. Although recent advances in Deep Learning have supposed a significant breakthrough in this topic, strong changes in pose, orientation and point of view severely harm current approaches. In addition, the acquisition of labeled datasets is costly, and current state-of-the-art deep learning algorithms cannot model all the aforementioned difficulties. In this paper, we propose to apply a multi-task learning loss function to share a common feature representation with other related tasks. Particularly we show that emotion recognition benefits from jointly learning a model with a detector of facial Action Units (collective muscle movements). The proposed loss function addresses the problem of learning multiple tasks with heterogeneously labeled data, improving previous multi-task approaches. We validate the proposal using two datasets acquired in non controlled environments, and an application to predict compound facial emotion expressions.