 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian CART models for aggregate claim modeling
Sep 03, 2024This paper proposes three types of Bayesian CART (or BCART) models for aggregate claim amount, namely, frequency-severity models, sequential models and joint models. We propose a general framework for the BCART models applicable to data with multivariate responses, which is particularly useful for the joint BCART models with a bivariate response: the number of claims and aggregate claim amount. To facilitate frequency-severity modeling, we investigate BCART models for the right-skewed and heavy-tailed claim severity data by using various distributions. We discover that the Weibull distribution is superior to gamma and lognormal distributions, due to its ability to capture different tail characteristics in tree models. Additionally, we find that sequential BCART models and joint BCART models, which incorporate dependence between the number of claims and average severity, are beneficial and thus preferable to the frequency-severity BCART models in which independence is assumed. The effectiveness of these models' performance is illustrated by carefully designed simulations and real insurance data.
Bayesian CART models for insurance claims frequency
Mar 03, 2023



Accuracy and interpretability of a (non-life) insurance pricing model are essential qualities to ensure fair and transparent premiums for policy-holders, that reflect their risk. In recent years, the classification and regression trees (CARTs) and their ensembles have gained popularity in the actuarial literature, since they offer good prediction performance and are relatively easily interpretable. In this paper, we introduce Bayesian CART models for insurance pricing, with a particular focus on claims frequency modelling. Additionally to the common Poisson and negative binomial (NB) distributions used for claims frequency, we implement Bayesian CART for the zero-inflated Poisson (ZIP) distribution to address the difficulty arising from the imbalanced insurance claims data. To this end, we introduce a general MCMC algorithm using data augmentation methods for posterior tree exploration. We also introduce the deviance information criterion (DIC) for the tree model selection. The proposed models are able to identify trees which can better classify the policy-holders into risk groups. Some simulations and real insurance data will be discussed to illustrate the applicability of these models.
Automatic model training under restrictive time constraints
Apr 21, 2021
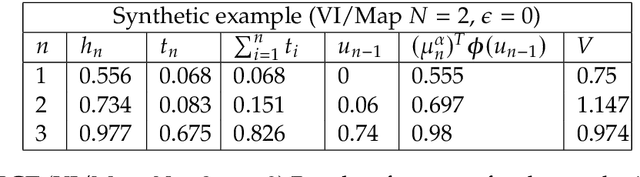
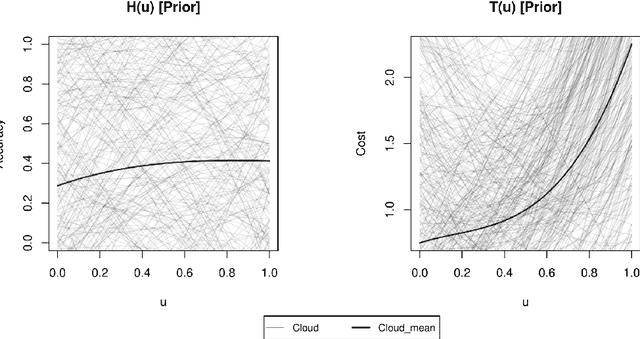

We develop a hyperparameter optimisation algorithm, Automated Budget Constrained Training (AutoBCT), which balances the quality of a model with the computational cost required to tune it. The relationship between hyperparameters, model quality and computational cost must be learnt and this learning is incorporated directly into the optimisation problem. At each training epoch, the algorithm decides whether to terminate or continue training, and, in the latter case, what values of hyperparameters to use. This decision weighs optimally potential improvements in the quality with the additional training time and the uncertainty about the learnt quantities. The performance of our algorithm is verified on a number of machine learning problems encompassing random forests and neural networks. Our approach is rooted in the theory of Markov decision processes with partial information and we develop a numerical method to compute the value function and an optimal strategy.