 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Subtle Ideological Manipulation of Large Language Models
Apr 19, 2025Large Language Models (LLMs) have transformed natural language processing, but concerns have emerged about their susceptibility to ideological manipulation, particularly in politically sensitive areas. Prior work has focused on binary Left-Right LLM biases, using explicit prompts and fine-tuning on political QA datasets. In this work, we move beyond this binary approach to explore the extent to which LLMs can be influenced across a spectrum of political ideologies, from Progressive-Left to Conservative-Right. We introduce a novel multi-task dataset designed to reflect diverse ideological positions through tasks such as ideological QA, statement ranking, manifesto cloze completion, and Congress bill comprehension. By fine-tuning three LLMs-Phi-2, Mistral, and Llama-3-on this dataset, we evaluate their capacity to adopt and express these nuanced ideologies. Our findings indicate that fine-tuning significantly enhances nuanced ideological alignment, while explicit prompts provide only minor refinements. This highlights the models' susceptibility to subtle ideological manipulation, suggesting a need for more robust safeguards to mitigate these risks.
Large Language Models For Text Classification: Case Study And Comprehensive Review
Jan 14, 2025Unlocking the potential of Large Language Models (LLMs) in data classification represents a promising frontier in natural language processing. In this work, we evaluate the performance of different LLMs in comparison with state-of-the-art deep-learning and machine-learning models, in two different classification scenarios: i) the classification of employees' working locations based on job reviews posted online (multiclass classification), and 2) the classification of news articles as fake or not (binary classification). Our analysis encompasses a diverse range of language models differentiating in size, quantization, and architecture. We explore the impact of alternative prompting techniques and evaluate the models based on the weighted F1-score. Also, we examine the trade-off between performance (F1-score) and time (inference response time) for each language model to provide a more nuanced understanding of each model's practical applicability. Our work reveals significant variations in model responses based on the prompting strategies. We find that LLMs, particularly Llama3 and GPT-4, can outperform traditional methods in complex classification tasks, such as multiclass classification, though at the cost of longer inference times. In contrast, simpler ML models offer better performance-to-time trade-offs in simpler binary classification tasks.
Check-It: A Plugin for Detecting and Reducing the Spread of Fake News and Misinformation on the Web
May 10, 2019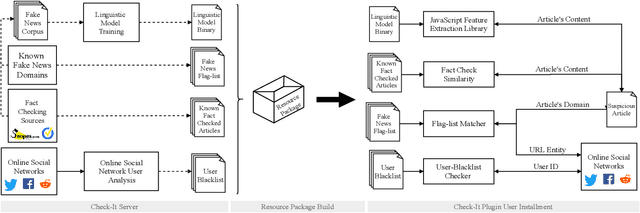

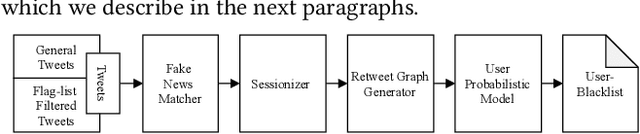

Over the past few years, we have been witnessing the rise of misinformation on the Web. People fall victims of fake news during their daily lives and assist their further propagation knowingly and inadvertently. There have been many initiatives that are trying to mitigate the damage caused by fake news, focusing on signals from either domain flag-lists, online social networks or artificial intelligence. In this work, we present Check-It, a system that combines, in an intelligent way, a variety of signals into a pipeline for fake news identification. Check-It is developed as a web browser plugin with the objective of efficient and timely fake news detection, respecting the user's privacy. Experimental results show that Check-It is able to outperform the state-of-the-art methods. On a dataset, consisting of 9 millions of articles labeled as fake and real, Check-It obtains classification accuracies that exceed 99%.