 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Domain Adaptive Approach for Multimodal 2D Object Detection in Adverse Weather Conditions
Mar 07, 2022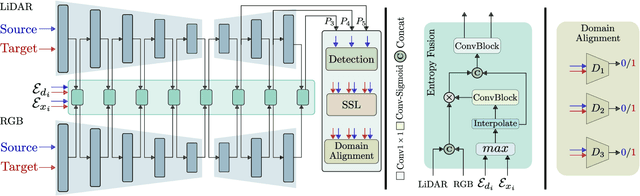
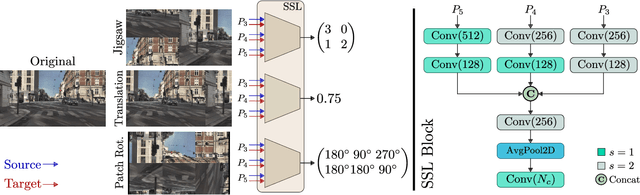
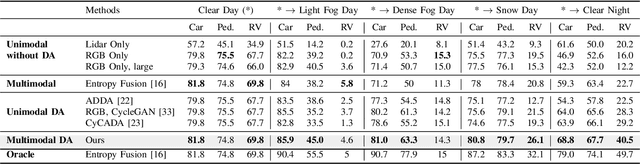
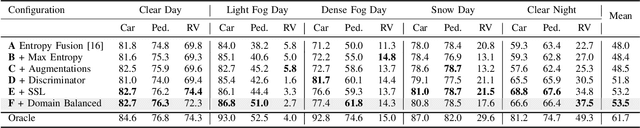
Integrating different representations from complementary sensing modalities is crucial for robust scene interpretation in autonomous driving. While deep learning architectures that fuse vision and range data for 2D object detection have thrived in recent years, the corresponding modalities can degrade in adverse weather or lighting conditions, ultimately leading to a drop in performance. Although domain adaptation methods attempt to bridge the domain gap between source and target domains, they do not readily extend to heterogeneous data distributions. In this work, we propose an unsupervised domain adaptation framework, which adapts a 2D object detector for RGB and lidar sensors to one or more target domains featuring adverse weather conditions. Our proposed approach consists of three components. First, a data augmentation scheme that simulates weather distortions is devised to add domain confusion and prevent overfitting on the source data. Second, to promote cross-domain foreground object alignment, we leverage the complementary features of multiple modalities through a multi-scale entropy-weighted domain discriminator. Finally, we use carefully designed pretext tasks to learn a more robust representation of the target domain data. Experiments performed on the DENSE dataset show that our method can substantially alleviate the domain gap under the single-target domain adaptation (STDA) setting and the less explored yet more general multi-target domain adaptation (MTDA) setting.
GLPU: A Geometric Approach For Lidar Pointcloud Upsampling
Feb 08, 2022



In autonomous driving, lidar is inherent for the understanding of the 3D environment. Lidar sensors vary in vertical resolutions, where a denser pointcloud depicts a more detailed environment, albeit at a significantly higher cost. Pointcloud upsampling predicts high-resolution pointclouds from sparser ones to bridge this performance gap at a lower cost. Although many upsampling frameworks have achieved a robust performance, a fair comparison is difficult as they were tested on different datasets and metrics. In this work, we first conduct a consistent comparative study to benchmark the existing algorithms on the KITTI dataset. Then, we observe that there are three common factors that hinder the performance: an inefficient data representation, a small receptive field, and low-frequency losses. By leveraging the scene geometry, a new self-supervised geometric lidar pointcloud upsampling (GLPU) framework is proposed to address the aforementioned limitations. Our experiments demonstrate the effectiveness and superior performance of GLPU compared to other techniques on the KITTI benchmark.
USIS: Unsupervised Semantic Image Synthesis
Sep 29, 2021
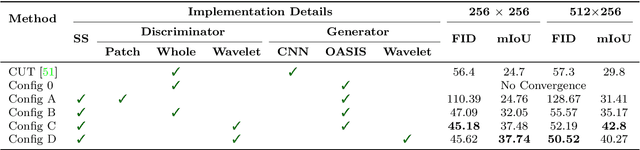
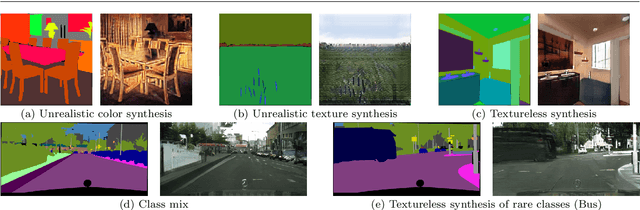

Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a photorealistic image is synthesized from a segmentation mask. SIS has mostly been addressed as a supervised problem. However, state-of-the-art methods depend on a huge amount of labeled data and cannot be applied in an unpaired setting. On the other hand, generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and feed them to traditional convolutional networks, which then learn correspondences in appearance instead of semantic content. In this initial work, we propose a new Unsupervised paradigm for Semantic Image Synthesis (USIS) as a first step towards closing the performance gap between paired and unpaired settings. Notably, the framework deploys a SPADE generator that learns to output images with visually separable semantic classes using a self-supervised segmentation loss. Furthermore, in order to match the color and texture distribution of real images without losing high-frequency information, we propose to use whole image wavelet-based discrimination. We test our methodology on 3 challenging datasets and demonstrate its ability to generate multimodal photorealistic images with an improved quality in the unpaired setting.
SLPC: a VRNN-based approach for stochastic lidar prediction and completion in autonomous driving
Feb 19, 2021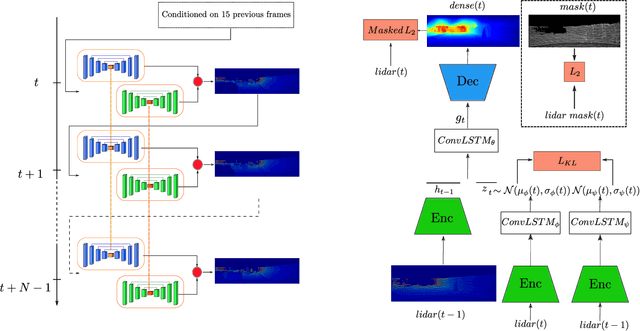
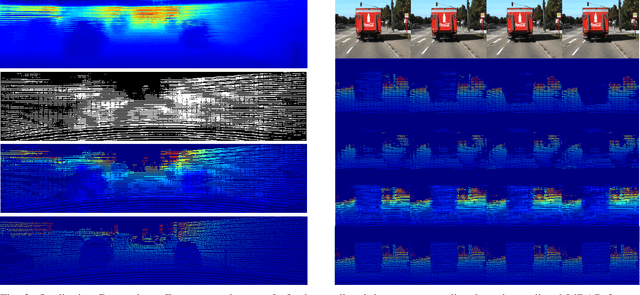
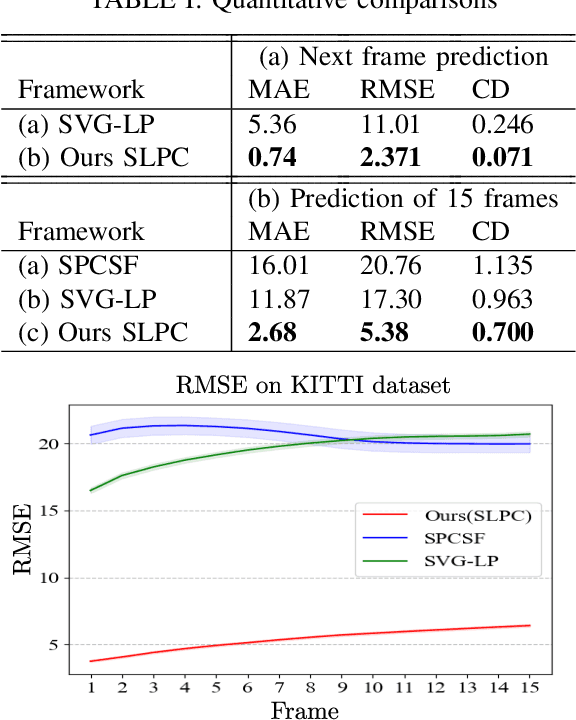
Predicting future 3D LiDAR pointclouds is a challenging task that is useful in many applications in autonomous driving such as trajectory prediction, pose forecasting and decision making. In this work, we propose a new LiDAR prediction framework that is based on generative models namely Variational Recurrent Neural Networks (VRNNs), titled Stochastic LiDAR Prediction and Completion (SLPC). Our algorithm is able to address the limitations of previous video prediction frameworks when dealing with sparse data by spatially inpainting the depth maps in the upcoming frames. Our contributions can thus be summarized as follows: we introduce the new task of predicting and completing depth maps from spatially sparse data, we present a sparse version of VRNNs and an effective self-supervised training method that does not require any labels. Experimental results illustrate the effectiveness of our framework in comparison to the state of the art methods in video prediction.