 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing linear initialisation to improve speed of convergence and fully-trained error in Autoencoders
Nov 17, 2023



Good weight initialisation is an important step in successful training of Artificial Neural Networks. Over time a number of improvements have been proposed to this process. In this paper we introduce a novel weight initialisation technique called the Straddled Matrix Initialiser. This initialisation technique is motivated by our assumption that major, global-scale relationships in data are linear with only smaller effects requiring complex non-linearities. Combination of Straddled Matrix and ReLU activation function initialises a Neural Network as a de facto linear model, which we postulate should be a better starting point for optimisation given our assumptions. We test this by training autoencoders on three datasets using Straddled Matrix and seven other state-of-the-art weight initialisation techniques. In all our experiments the Straddeled Matrix Initialiser clearly outperforms all other methods.
Instability of computer vision models is a necessary result of the task itself
Oct 26, 2023Adversarial examples resulting from instability of current computer vision models are an extremely important topic due to their potential to compromise any application. In this paper we demonstrate that instability is inevitable due to a) symmetries (translational invariance) of the data, b) the categorical nature of the classification task, and c) the fundamental discrepancy of classifying images as objects themselves. The issue is further exacerbated by non-exhaustive labelling of the training data. Therefore we conclude that instability is a necessary result of how the problem of computer vision is currently formulated. While the problem cannot be eliminated, through the analysis of the causes, we have arrived at ways how it can be partially alleviated. These include i) increasing the resolution of images, ii) providing contextual information for the image, iii) exhaustive labelling of training data, and iv) preventing attackers from frequent access to the computer vision system.
Demonstrating Rosa: the fairness solution for any Data Analytic pipeline
Feb 28, 2020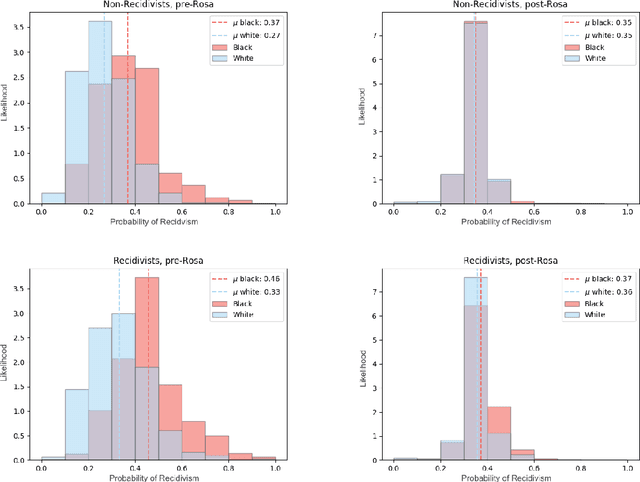
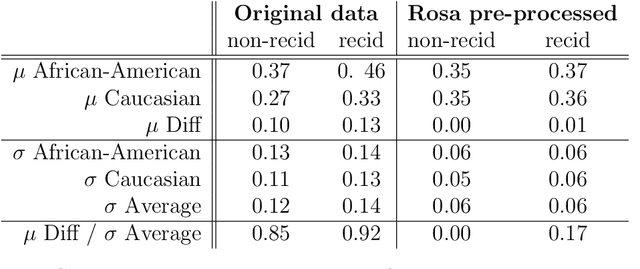
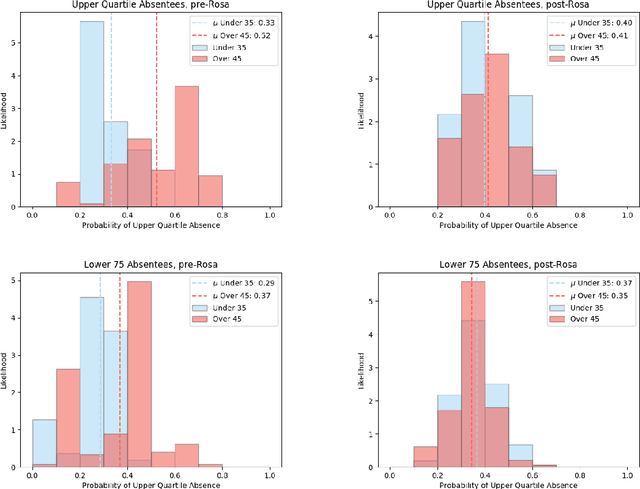
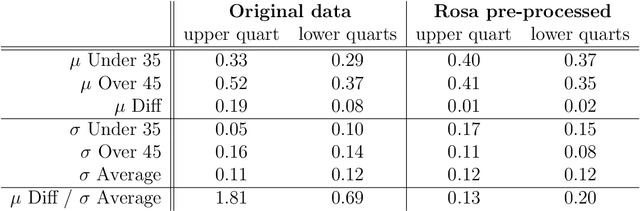
Most datasets of interest to the analytics industry are impacted by various forms of human bias. The outcomes of Data Analytics [DA] or Machine Learning [ML] on such data are therefore prone to replicating the bias. As a result, a large number of biased decision-making systems based on DA/ML have recently attracted attention. In this paper we introduce Rosa, a free, web-based tool to easily de-bias datasets with respect to a chosen characteristic. Rosa is based on the principles of Fair Adversarial Networks, developed by illumr Ltd., and can therefore remove interactive, non-linear, and non-binary bias. Rosa is stand-alone pre-processing step / API, meaning it can be used easily with any DA/ML pipeline. We test the efficacy of Rosa in removing bias from data-driven decision making systems by performing standard DA tasks on five real-world datasets, selected for their relevance to current DA problems, and also their high potential for bias. We use simple ML models to model a characteristic of analytical interest, and compare the level of bias in the model output both with and without Rosa as a pre-processing step. We find that in all cases there is a substantial decrease in bias of the data-driven decision making systems when the data is pre-processed with Rosa.
Fair Adversarial Networks
Feb 23, 2020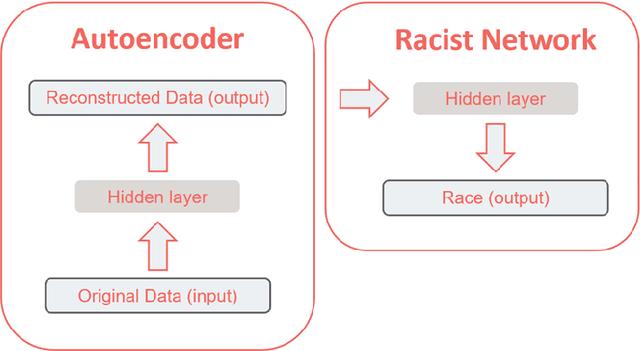
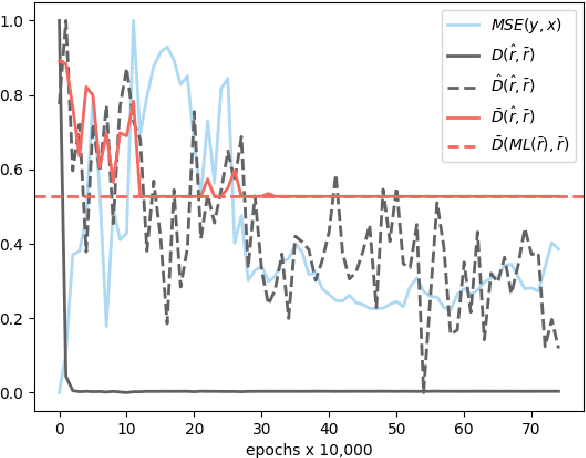
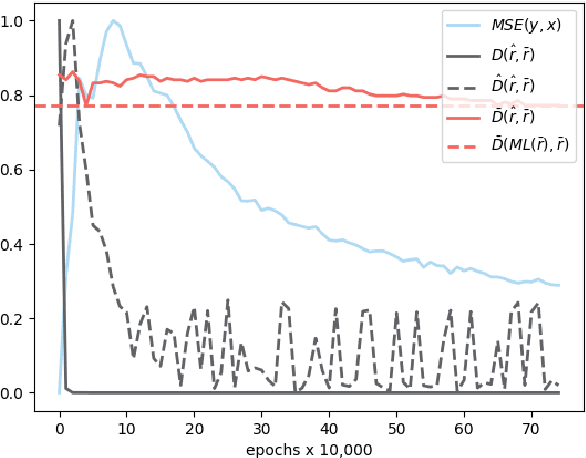
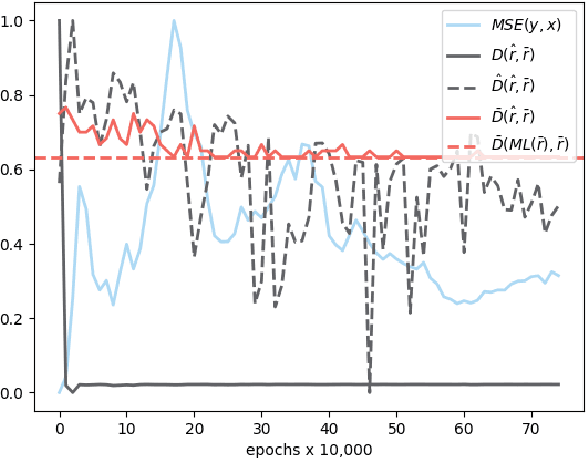
The influence of human judgement is ubiquitous in datasets used across the analytics industry, yet humans are known to be sub-optimal decision makers prone to various biases. Analysing biased datasets then leads to biased outcomes of the analysis. Bias by protected characteristics (e.g. race) is of particular interest as it may not only make the output of analytical process sub-optimal, but also illegal. Countering the bias by constraining the analytical outcomes to be fair is problematic because A) fairness lacks a universally accepted definition, while at the same time some definitions are mutually exclusive, and B) the use of optimisation constraints ensuring fairness is incompatible with most analytical pipelines. Both problems are solved by methods which remove bias from the data and returning an altered dataset. This approach aims to not only remove the actual bias variable (e.g. race), but also alter all proxy variables (e.g. postcode) so the bias variable is not detectable from the rest of the data. The advantage of using this approach is that the definition of fairness as a lack of detectable bias in the data (as opposed to the output of analysis) is universal and therefore solves problem (A). Furthermore, as the data is altered to remove bias the problem (B) disappears because the analytical pipelines can remain unchanged. This approach has been adopted by several technical solutions. None of them, however, seems to be satisfactory in terms of ability to remove multivariate, non-linear and non-binary biases. Therefore, in this paper I propose the concept of Fair Adversarial Networks as an easy-to-implement general method for removing bias from data. This paper demonstrates that Fair Adversarial Networks achieve this aim.
The relationship between Biological and Artificial Intelligence
May 01, 2019
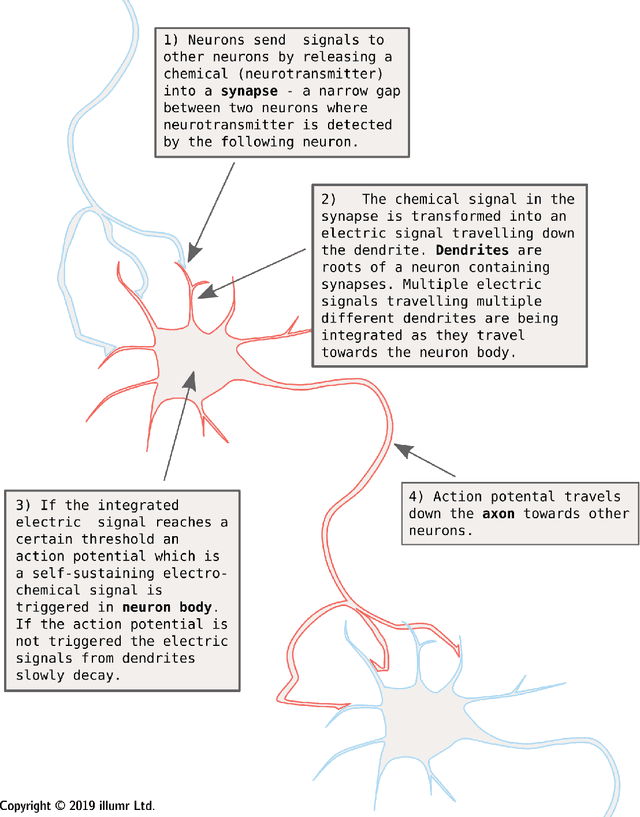

Intelligence can be defined as a predominantly human ability to accomplish tasks that are generally hard for computers and animals. Artificial Intelligence [AI] is a field attempting to accomplish such tasks with computers. AI is becoming increasingly widespread, as are claims of its relationship with Biological Intelligence. Often these claims are made to imply higher chances of a given technology succeeding, working on the assumption that AI systems which mimic the mechanisms of Biological Intelligence should be more successful. In this article I will discuss the similarities and differences between AI and the extent of our knowledge about the mechanisms of intelligence in biology, especially within humans. I will also explore the validity of the assumption that biomimicry in AI systems aids their advancement, and I will argue that existing similarity to biological systems in the way Artificial Neural Networks [ANNs] tackle tasks is due to design decisions, rather than inherent similarity of underlying mechanisms. This article is aimed at people who understand the basics of AI (especially ANNs), and would like to be better able to evaluate the often wild claims about the value of biomimicry in AI.