 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Collocations in Hierarchical Latent Tree Analysis for Topic Modeling
Jul 10, 2020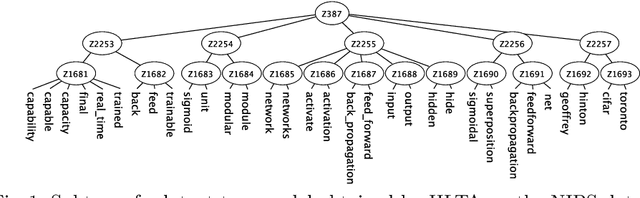

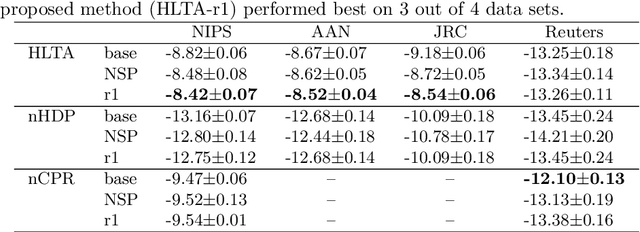
Topic modeling has been one of the most active research areas in machine learning in recent years. Hierarchical latent tree analysis (HLTA) has been recently proposed for hierarchical topic modeling and has shown superior performance over state-of-the-art methods. However, the models used in HLTA have a tree structure and cannot represent the different meanings of multiword expressions sharing the same word appropriately. Therefore, we propose a method for extracting and selecting collocations as a preprocessing step for HLTA. The selected collocations are replaced with single tokens in the bag-of-words model before running HLTA. Our empirical evaluation shows that the proposed method led to better performance of HLTA on three of the four data sets tested.
Frank-Wolfe Algorithm for Exemplar Selection
Nov 06, 2018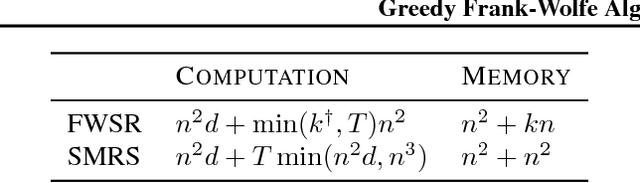
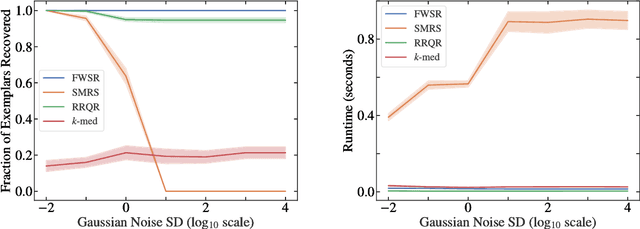
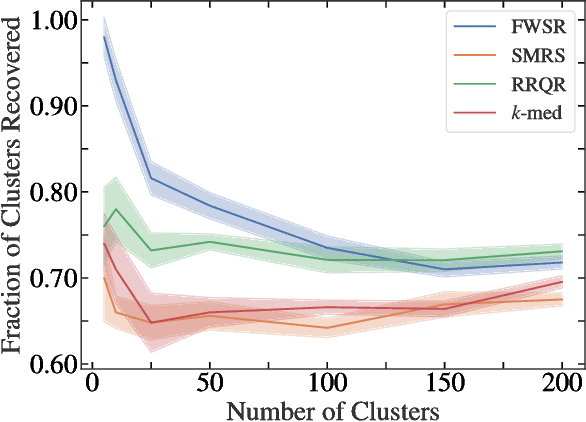
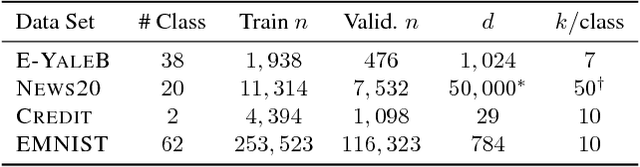
In this paper, we consider the problem of selecting representatives from a data set for arbitrary supervised/unsupervised learning tasks. We identify a subset $S$ of a data set $A$ such that 1) the size of $S$ is much smaller than $A$ and 2) $S$ efficiently describes the entire data set, in a way formalized via auto-regression. The set $S$, also known as the exemplars of the data set $A$, is constructed by solving a convex auto-regressive version of dictionary learning where the dictionary and measurements are given by the data matrix. We show that in order to generate $|S| = k$ exemplars, our algorithm, Frank-Wolfe Sparse Representation (FWSR), only requires $\approx k$ iterations with a per-iteration cost that is quadratic in the size of $A$, an order of magnitude faster than state of the art methods. We test our algorithm against current methods on 4 different data sets and are able to outperform other exemplar finding methods in almost all scenarios. We also test our algorithm qualitatively by selecting exemplars from a corpus of Donald Trump and Hillary Clinton's twitter posts.