 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Distributed Representations of Tweets - Present and Future
Jun 29, 2017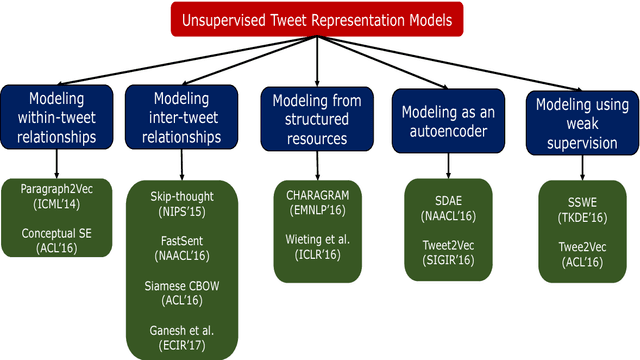
Unsupervised representation learning for tweets is an important research field which helps in solving several business applications such as sentiment analysis, hashtag prediction, paraphrase detection and microblog ranking. A good tweet representation learning model must handle the idiosyncratic nature of tweets which poses several challenges such as short length, informal words, unusual grammar and misspellings. However, there is a lack of prior work which surveys the representation learning models with a focus on tweets. In this work, we organize the models based on its objective function which aids the understanding of the literature. We also provide interesting future directions, which we believe are fruitful in advancing this field by building high-quality tweet representation learning models.
Improving Tweet Representations using Temporal and User Context
Dec 19, 2016
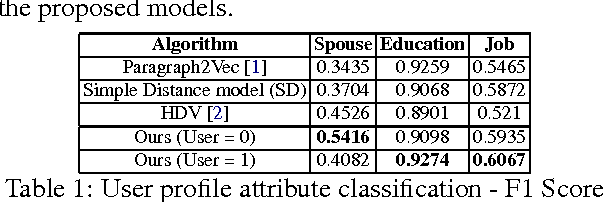
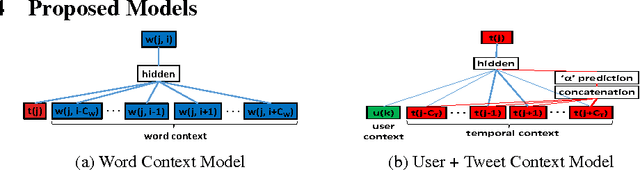
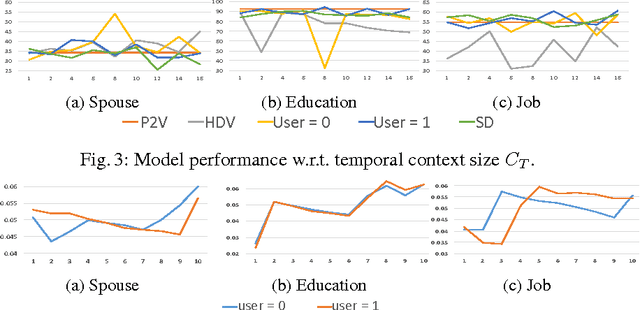
In this work we propose a novel representation learning model which computes semantic representations for tweets accurately. Our model systematically exploits the chronologically adjacent tweets ('context') from users' Twitter timelines for this task. Further, we make our model user-aware so that it can do well in modeling the target tweet by exploiting the rich knowledge about the user such as the way the user writes the post and also summarizing the topics on which the user writes. We empirically demonstrate that the proposed models outperform the state-of-the-art models in predicting the user profile attributes like spouse, education and job by 19.66%, 2.27% and 2.22% respectively.