 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Appropriate size of the Mongolian general corpus
Jul 12, 2023This study aims to determine the appropriate size of the Mongolian general corpus. This study used the Heaps function and Type Token Ratio to determine the appropriate size of the Mongolian general corpus. The sample corpus of 906,064 tokens comprised texts from 10 domains of newspaper politics, economy, society, culture, sports, world articles and laws, middle and high school literature textbooks, interview articles, and podcast transcripts. First, we estimated the Heaps function with this sample corpus. Next, we observed changes in the number of types and TTR values while increasing the number of tokens by one million using the estimated Heaps function. As a result of observation, we found that the TTR value hardly changed when the number of tokens exceeded from 39 to 42 million. Thus, we conclude that an appropriate size for a Mongolian general corpus is from 39 to 42 million tokens.
Effective Computer Model For Recognizing Nationality From Frontal Image
Mar 15, 2016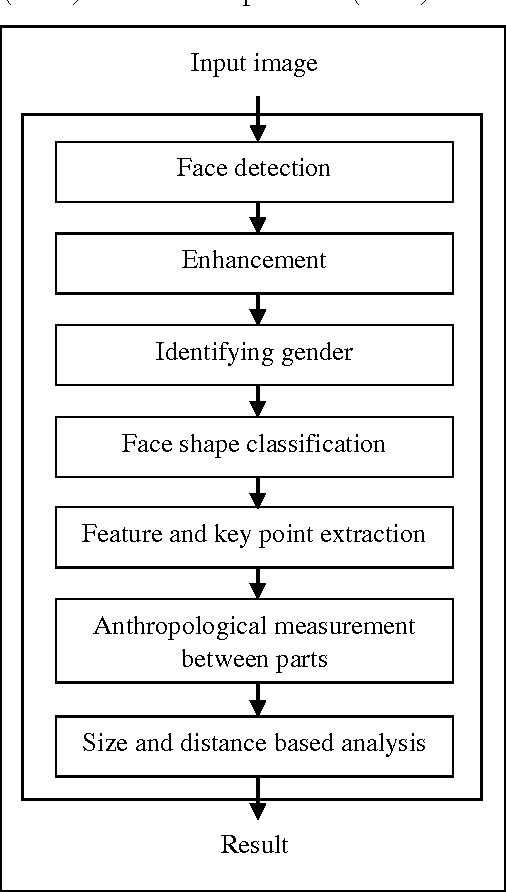



We are introducing new effective computer model for extracting nationality from frontal image candidate using face part color, size and distances based on deep research. Determining face part size, color, and distances is depending on a variety of factors including image quality, lighting condition, rotation angle, occlusion and facial emotion. Therefore, first we need to detect a face on the image then convert an image into the real input. After that, we can determine image candidate gender, face shape, key points and face parts. Finally, we will return the result, based on the comparison of sizes and distances with the sample measurement table database. While we were measuring samples, there were big differences between images by their gender and face shapes. Input images must be the frontal face image that has smooth lighting and does not have any rotation angle. The model can be used in military, police, defense, healthcare, and technology sectors. Finally, Computer can distinguish nationality from the face image.