 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Readability Analysis Of Turkish Elementary School Textbooks
Feb 11, 2018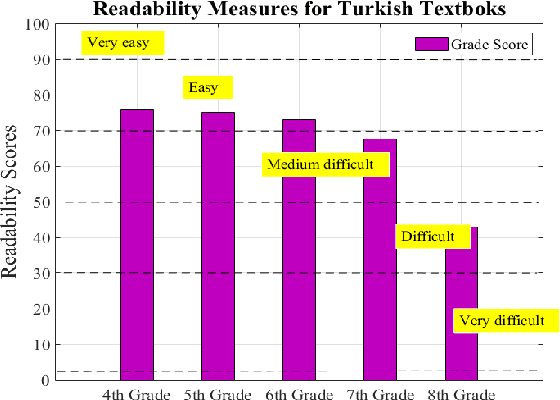
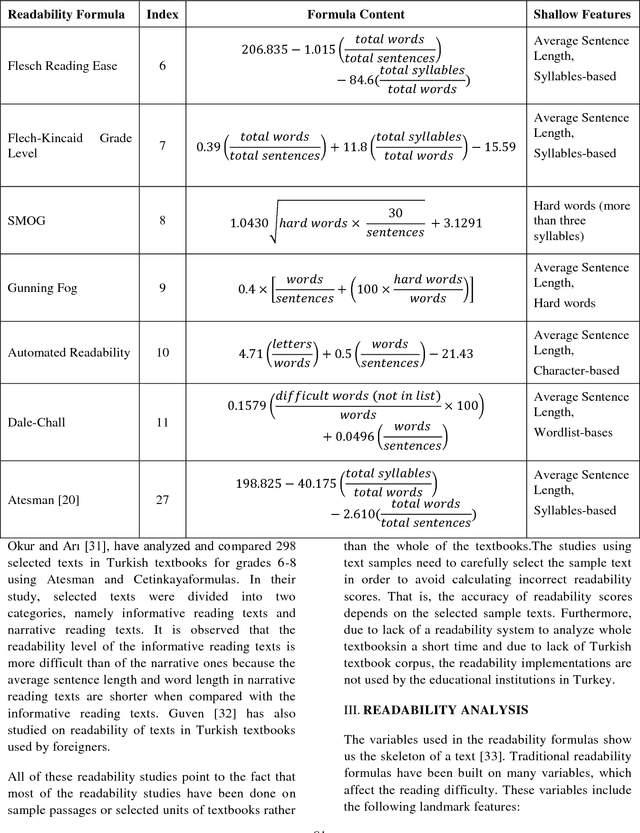
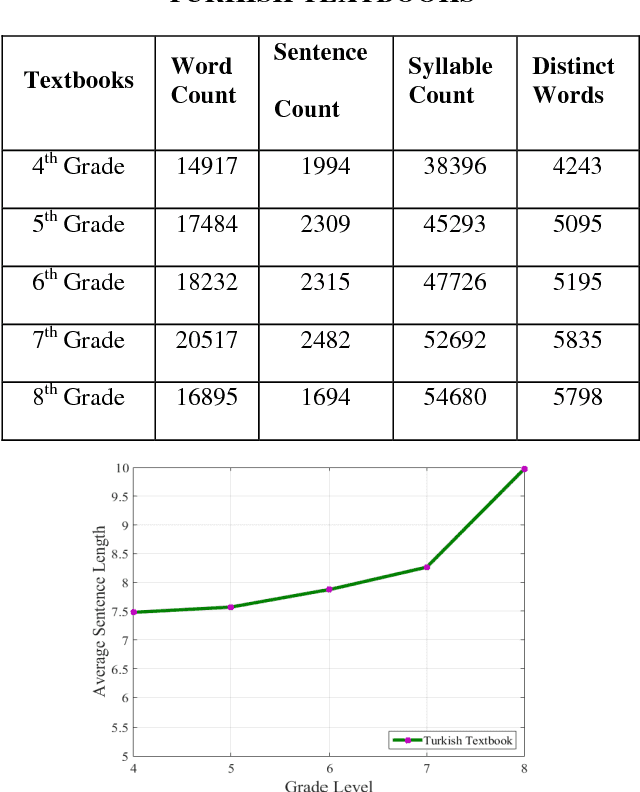
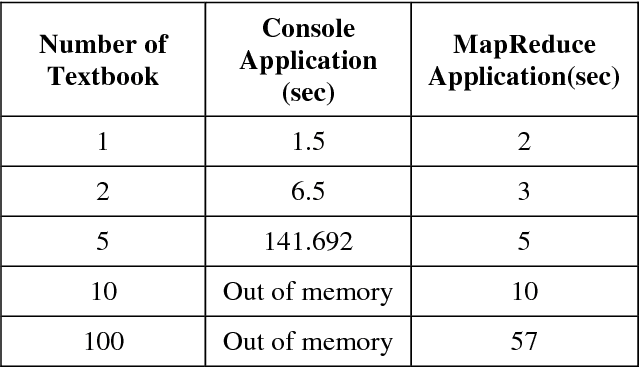
The readability assessment deals with estimating the level of difficulty in reading texts.Many readability tests, which do not indicate execution efficiency, have been applied on specific texts to measure the reading grade level in science textbooks. In this paper, we analyze the content covered in elementary school Turkish textbooks by employing a distributed parallel processing framework based on popular MapReduce paradigm. We outline the architecture of a distributed Big Data processing system which uses Hadoop for full-text readability analysis. The readability scores of the textbooks and system performance measurements are also given in the paper.
Distributed NLP
Feb 10, 2018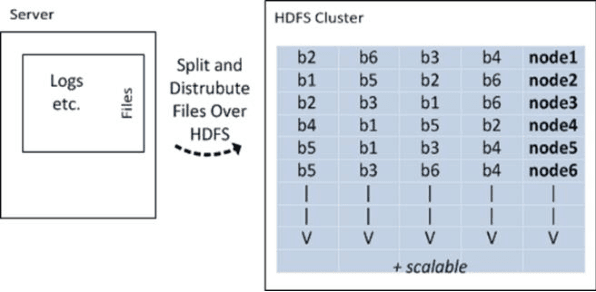

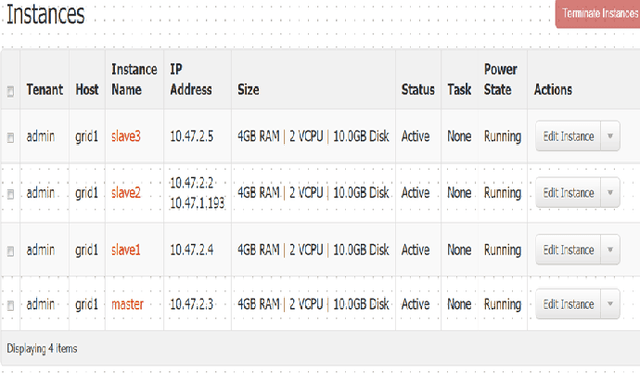
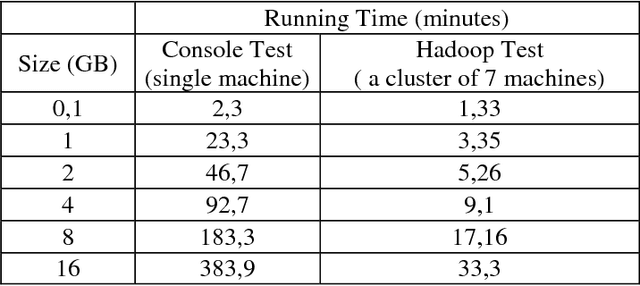
In this paper we present the performance of parallel text processing with Map Reduce on a cloud platform. Scientific papers in Turkish language are processed using Zemberek NLP library. Experiments were run on a Hadoop cluster and compared with the single machines performance.
Preparation of Improved Turkish DataSet for Sentiment Analysis in Social Media
Jan 31, 2018
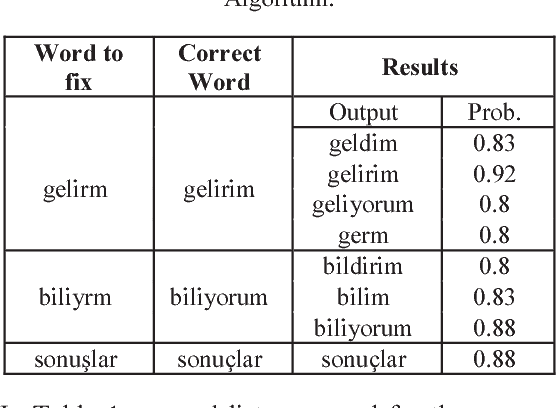


A public dataset, with a variety of properties suitable for sentiment analysis [1], event prediction, trend detection and other text mining applications, is needed in order to be able to successfully perform analysis studies. The vast majority of data on social media is text-based and it is not possible to directly apply machine learning processes into these raw data, since several different processes are required to prepare the data before the implementation of the algorithms. For example, different misspellings of same word enlarge the word vector space unnecessarily, thereby it leads to reduce the success of the algorithm and increase the computational power requirement. This paper presents an improved Turkish dataset with an effective spelling correction algorithm based on Hadoop [2]. The collected data is recorded on the Hadoop Distributed File System and the text based data is processed by MapReduce programming model. This method is suitable for the storage and processing of large sized text based social media data. In this study, movie reviews have been automatically recorded with Apache ManifoldCF (MCF) [3] and data clusters have been created. Various methods compared such as Levenshtein and Fuzzy String Matching have been proposed to create a public dataset from collected data. Experimental results show that the proposed algorithm, which can be used as an open source dataset in sentiment analysis studies, have been performed successfully to the detection and correction of spelling errors.