 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhraseStereo: The First Open-Vocabulary Stereo Image Segmentation Dataset
Oct 01, 2025Understanding how natural language phrases correspond to specific regions in images is a key challenge in multimodal semantic segmentation. Recent advances in phrase grounding are largely limited to single-view images, neglecting the rich geometric cues available in stereo vision. For this, we introduce PhraseStereo, the first novel dataset that brings phrase-region segmentation to stereo image pairs. PhraseStereo builds upon the PhraseCut dataset by leveraging GenStereo to generate accurate right-view images from existing single-view data, enabling the extension of phrase grounding into the stereo domain. This new setting introduces unique challenges and opportunities for multimodal learning, particularly in leveraging depth cues for more precise and context-aware grounding. By providing stereo image pairs with aligned segmentation masks and phrase annotations, PhraseStereo lays the foundation for future research at the intersection of language, vision, and 3D perception, encouraging the development of models that can reason jointly over semantics and geometry. The PhraseStereo dataset will be released online upon acceptance of this work.
SCR: Smooth Contour Regression with Geometric Priors
Feb 08, 2022

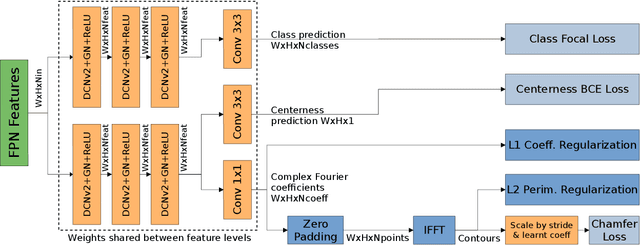

While object detection methods traditionally make use of pixel-level masks or bounding boxes, alternative representations such as polygons or active contours have recently emerged. Among them, methods based on the regression of Fourier or Chebyshev coefficients have shown high potential on freeform objects. By defining object shapes as polar functions, they are however limited to star-shaped domains. We address this issue with SCR: a method that captures resolution-free object contours as complex periodic functions. The method offers a good compromise between accuracy and compactness thanks to the design of efficient geometric shape priors. We benchmark SCR on the popular COCO 2017 instance segmentation dataset, and show its competitiveness against existing algorithms in the field. In addition, we design a compact version of our network, which we benchmark on embedded hardware with a wide range of power targets, achieving up to real-time performance.
Road Extraction from Overhead Images with Graph Neural Networks
Dec 09, 2021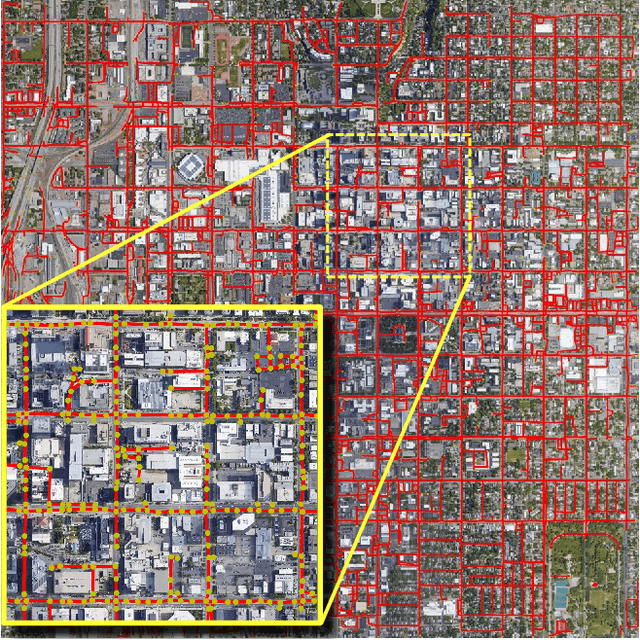
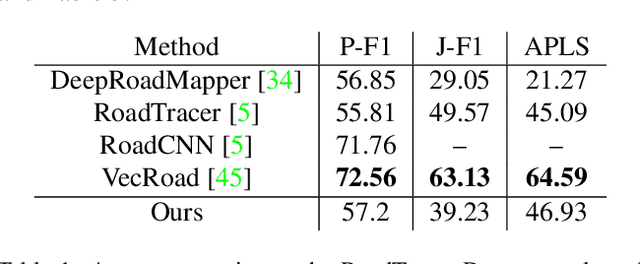
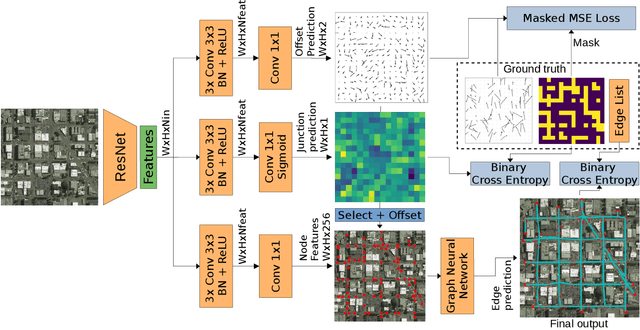
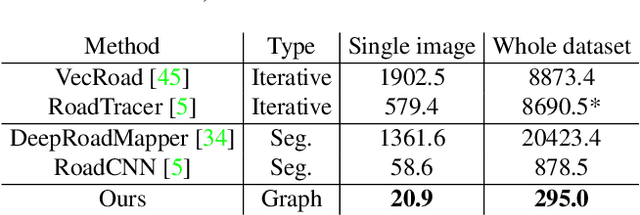
Automatic road graph extraction from aerial and satellite images is a long-standing challenge. Existing algorithms are either based on pixel-level segmentation followed by vectorization, or on iterative graph construction using next move prediction. Both of these strategies suffer from severe drawbacks, in particular high computing resources and incomplete outputs. By contrast, we propose a method that directly infers the final road graph in a single pass. The key idea consists in combining a Fully Convolutional Network in charge of locating points of interest such as intersections, dead ends and turns, and a Graph Neural Network which predicts links between these points. Such a strategy is more efficient than iterative methods and allows us to streamline the training process by removing the need for generation of starting locations while keeping the training end-to-end. We evaluate our method against existing works on the popular RoadTracer dataset and achieve competitive results. We also benchmark the speed of our method and show that it outperforms existing approaches. This opens the possibility of in-flight processing on embedded devices.