 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing socio-economic climate impacts from text data
May 20, 2026Recent advances in natural language processing (NLP) and large language models (LLMs) have enabled the systematic use of large-scale textual data from news, social media, and reports to create datasets with socio-economic impacts of climate hazards such as floods, droughts, storms, and multi-hazard events. As the field of text-as-data for impact assessment expands, so does its methodological complexity. Yet research remains fragmented, with no clear guidelines for defining what constitutes an impact, handling temporal and spatial biases, and selecting appropriate modeling and post-processing strategies. This lack of coherence limits transparency and comparability across studies. Here, we address this gap by synthesising common practices, describing key challenges specific to the use of text-as-data methods for analyzing socio-economic impact data, and proposing recommendations to address them. By providing guidance on best practices, we aim to support the construction of robust text-derived socio-economic impact datasets that can more accurately inform disaster risk management and attribution studies.
Climate-Eval: A Comprehensive Benchmark for NLP Tasks Related to Climate Change
May 24, 2025Climate-Eval is a comprehensive benchmark designed to evaluate natural language processing models across a broad range of tasks related to climate change. Climate-Eval aggregates existing datasets along with a newly developed news classification dataset, created specifically for this release. This results in a benchmark of 25 tasks based on 13 datasets, covering key aspects of climate discourse, including text classification, question answering, and information extraction. Our benchmark provides a standardized evaluation suite for systematically assessing the performance of large language models (LLMs) on these tasks. Additionally, we conduct an extensive evaluation of open-source LLMs (ranging from 2B to 70B parameters) in both zero-shot and few-shot settings, analyzing their strengths and limitations in the domain of climate change.
Ensemble neural network forecasts with singular value decomposition
Feb 13, 2020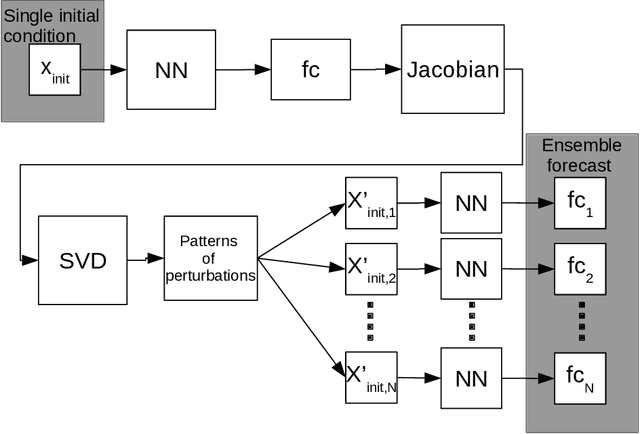

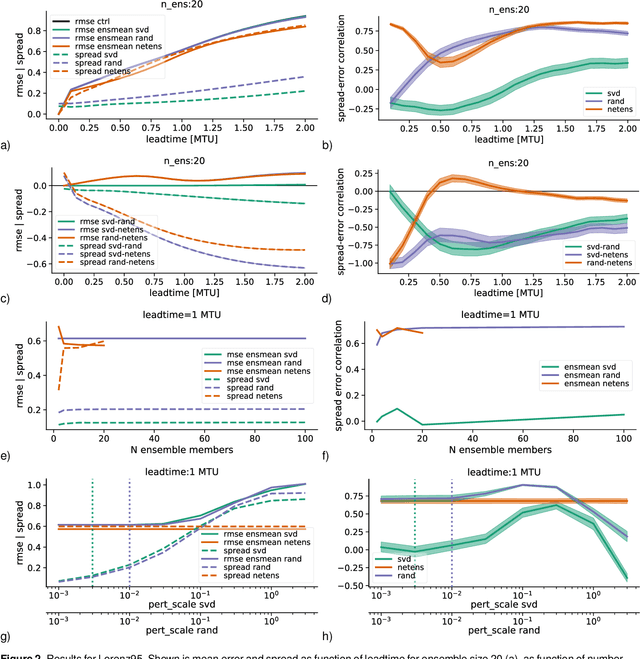
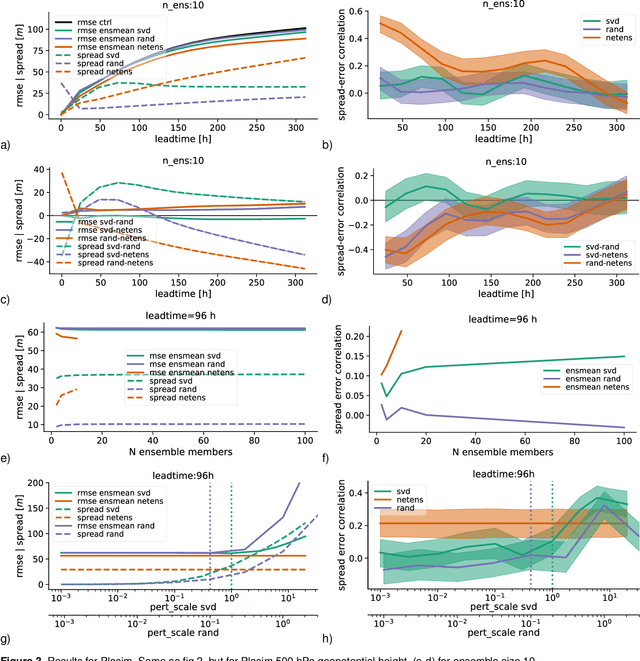
Ensemble weather forecasts enable a measure of uncertainty to be attached to each forecast by computing the ensemble's spread. However, generating an ensemble with a good error-spread relationship is far from trivial, and a wide range of approaches to achieve this have been explored. Random perturbations of the initial model state typically provide unsatisfactory results when applied to numerical weather prediction models. Singular value decomposition has proved more successful in this context, and as a result has been widely used for creating perturbed initial states of weather prediction models. We demonstrate how to apply the technique of singular value decomposition to purely neural-network based forecasts. Additionally, we explore the use of random initial perturbations for neural network ensembles, and the creation of neural network ensembles via retraining the network. We find that the singular value decomposition results in ensemble forecasts that have some probabilistic skill, but are inferior to the ensemble created by retraining the neural network several times. Compared to random initial perturbations, the singular value technique performs better when forecasting a simple general circulation model, comparably when forecasting atmospheric reanalysis data, and worse when forecasting the lorenz95 system - a highly idealized model designed to mimic certain aspects of the mid-latitude atmosphere.