 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Option Learning in Sparse Rewards with Hindsight Experience Replay
Feb 14, 2026Hierarchical Reinforcement Learning (HRL) frameworks like Option-Critic (OC) and Multi-updates Option Critic (MOC) have introduced significant advancements in learning reusable options. However, these methods underperform in multi-goal environments with sparse rewards, where actions must be linked to temporally distant outcomes. To address this limitation, we first propose MOC-HER, which integrates the Hindsight Experience Replay (HER) mechanism into the MOC framework. By relabeling goals from achieved outcomes, MOC-HER can solve sparse reward environments that are intractable for the original MOC. However, this approach is insufficient for object manipulation tasks, where the reward depends on the object reaching the goal rather than on the agent's direct interaction. This makes it extremely difficult for HRL agents to discover how to interact with these objects. To overcome this issue, we introduce Dual Objectives Hindsight Experience Replay (2HER), a novel extension that creates two sets of virtual goals. In addition to relabeling goals based on the object's final state (standard HER), 2HER also generates goals from the agent's effector positions, rewarding the agent for both interacting with the object and completing the task. Experimental results in robotic manipulation environments show that MOC-2HER achieves success rates of up to 90%, compared to less than 11% for both MOC and MOC-HER. These results highlight the effectiveness of our dual objective relabeling strategy in sparse reward, multi-goal tasks.
Evaluation of Convolutional Neural Networks for COVID-19 Classification on Chest X-Rays
Sep 06, 2021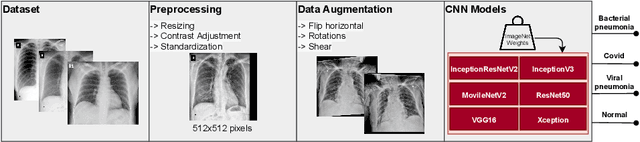



Early identification of patients with COVID-19 is essential to enable adequate treatment and to reduce the burden on the health system. The gold standard for COVID-19 detection is the use of RT-PCR tests. However, due to the high demand for tests, these can take days or even weeks in some regions of Brazil. Thus, an alternative for detecting COVID-19 is the analysis of Digital Chest X-rays (XR). Changes due to COVID-19 can be detected in XR, even in asymptomatic patients. In this context, models based on deep learning have great potential to be used as support systems for diagnosis or as screening tools. In this paper, we propose the evaluation of convolutional neural networks to identify pneumonia due to COVID-19 in XR. The proposed methodology consists of a preprocessing step of the XR, data augmentation, and classification by the convolutional architectures DenseNet121, InceptionResNetV2, InceptionV3, MovileNetV2, ResNet50, and VGG16 pre-trained with the ImageNet dataset. The obtained results demonstrate that the VGG16 architecture obtained superior performance in the classification of XR for the evaluation metrics using the methodology proposed in this article. The obtained results for our methodology demonstrate that the VGG16 architecture presented a superior performance in the classification of XR, with an Accuracy of 85.11%, Sensitivity of 85.25%, Specificity of $85.16%, F1-score of $85.03%, and an AUC of 0.9758.
Experience Sharing Between Cooperative Reinforcement Learning Agents
Nov 06, 2019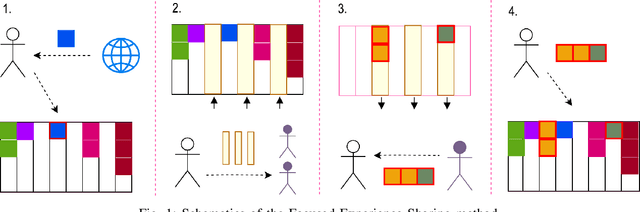

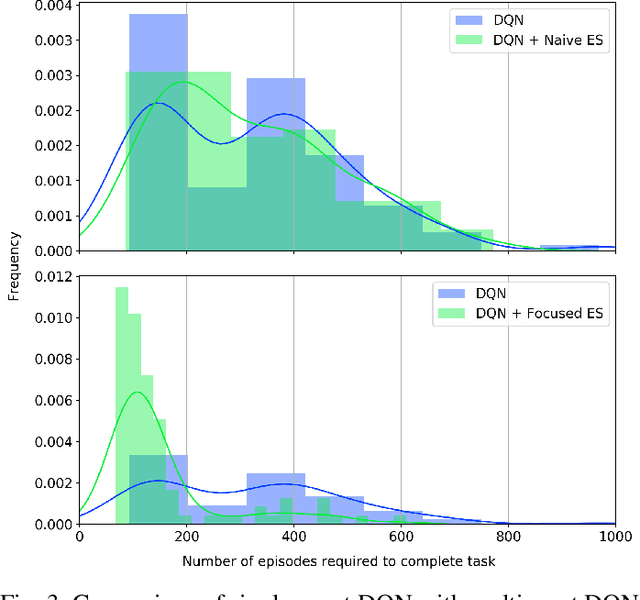
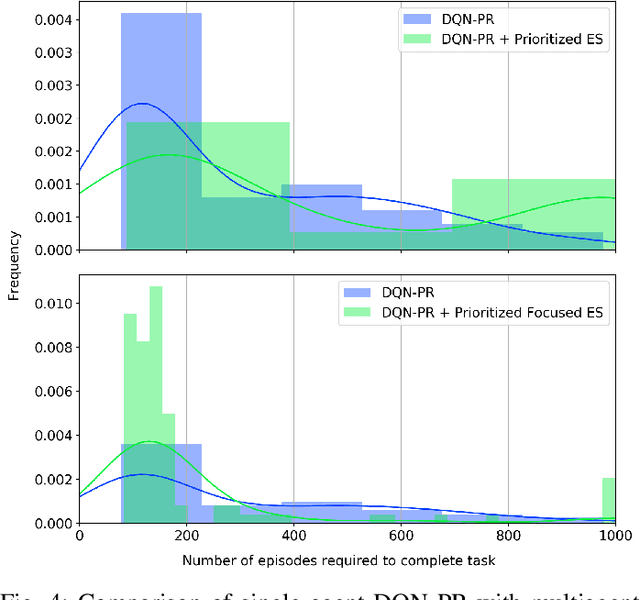
The idea of experience sharing between cooperative agents naturally emerges from our understanding of how humans learn. Our evolution as a species is tightly linked to the ability to exchange learned knowledge with one another. It follows that experience sharing (ES) between autonomous and independent agents could become the key to accelerate learning in cooperative multiagent settings. We investigate if randomly selecting experiences to share can increase the performance of deep reinforcement learning agents, and propose three new methods for selecting experiences to accelerate the learning process. Firstly, we introduce Focused ES, which prioritizes unexplored regions of the state space. Secondly, we present Prioritized ES, in which temporal-difference error is used as a measure of priority. Finally, we devise Focused Prioritized ES, which combines both previous approaches. The methods are empirically validated in a control problem. While sharing randomly selected experiences between two Deep Q-Network agents shows no improvement over a single agent baseline, we show that the proposed ES methods can successfully outperform the baseline. In particular, the Focused ES accelerates learning by a factor of 2, reducing by 51% the number of episodes required to complete the task.