 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Disfluency Detection, Uh No, Disfluency Generation for the Masses
Nov 16, 2022Existing approaches for disfluency detection typically require the existence of large annotated datasets. However, current datasets for this task are limited, suffer from class imbalance, and lack some types of disfluencies that can be encountered in real-world scenarios. This work proposes LARD, a method for automatically generating artificial disfluencies from fluent text. LARD can simulate all the different types of disfluencies (repetitions, replacements and restarts) based on the reparandum/interregnum annotation scheme. In addition, it incorporates contextual embeddings into the disfluency generation to produce realistic context-aware artificial disfluencies. Since the proposed method requires only fluent text, it can be used directly for training, bypassing the requirement of annotated disfluent data. Our empirical evaluation demonstrates that LARD can indeed be effectively used when no or only a few data are available. Furthermore, our detailed analysis suggests that the proposed method generates realistic disfluencies and increases the accuracy of existing disfluency detectors.
LARD: Large-scale Artificial Disfluency Generation
Jan 13, 2022

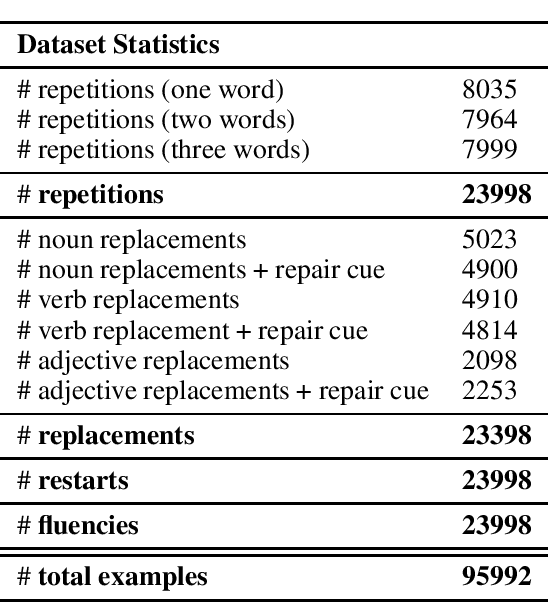
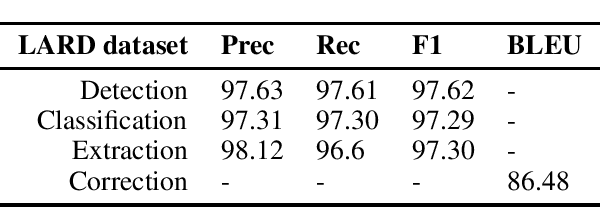
Disfluency detection is a critical task in real-time dialogue systems. However, despite its importance, it remains a relatively unexplored field, mainly due to the lack of appropriate datasets. At the same time, existing datasets suffer from various issues, including class imbalance issues, which can significantly affect the performance of the model on rare classes, as it is demonstrated in this paper. To this end, we propose LARD, a method for generating complex and realistic artificial disfluencies with little effort. The proposed method can handle three of the most common types of disfluencies: repetitions, replacements and restarts. In addition, we release a new large-scale dataset with disfluencies that can be used on four different tasks: disfluency detection, classification, extraction and correction. Experimental results on the LARD dataset demonstrate that the data produced by the proposed method can be effectively used for detecting and removing disfluencies, while also addressing limitations of existing datasets.