 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Temporal Granularity on Socio-Demographic Inference from Household Load Profiles
Jun 02, 2026Smart meter data can reveal sensitive socio-demographic characteristics of households, raising privacy concerns. While this risk has been demonstrated at fixed granularities, the role of temporal resolution in shaping inference performance remains insufficiently explored. This paper addresses this gap by analyzing how load profiles with granularities from 15 minutes to 7 days affect the predictability of eight socio-demographic attributes in a dataset of 1,589 households over one year. We introduce an evaluation framework where classifiers are trained on year-round data but tested on arbitrary weeks, forcing generalization across seasonal and weekly variations. Our results show three main findings. First, while coarsening granularity reduces predictive accuracy, two plateaus emerge: performance is stable between 15 minutes and 1 hour, and again between 1 and 7 days. This reveals opportunities for data minimization without sacrificing utility. Second, interpretable handcrafted and tsfresh features remain competitive with CNN-based autoencoder embeddings, while XGBoost consistently outperforms alternative classifiers. Third, feature importance analysis highlights differences between static and dynamic attributes: dwelling size can be inferred even from coarse data, whereas swimming pool usage requires fine-grained temporal signals. Overall, our study provides new insights into the privacy-utility trade-off in smart metering, showing how temporal resolution, feature extraction, and classifier choice jointly influence socio-demographic inference.
Quantifying identifiability to choose and audit $ε$ in differentially private deep learning
Mar 05, 2021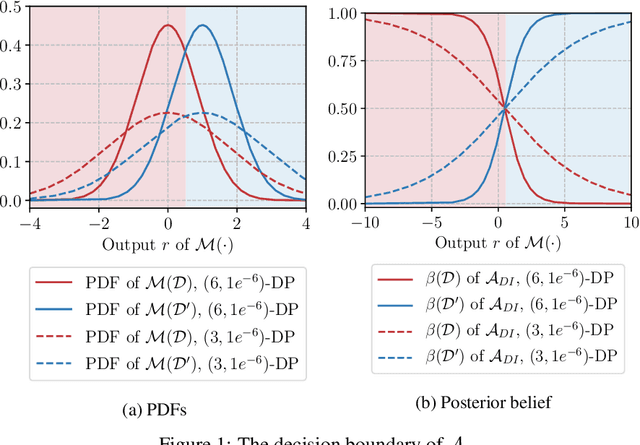
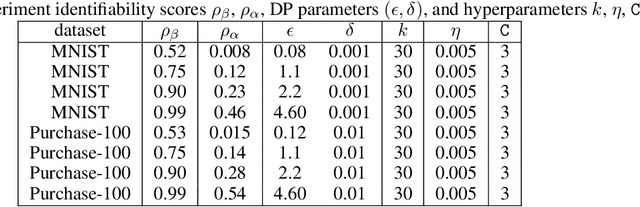
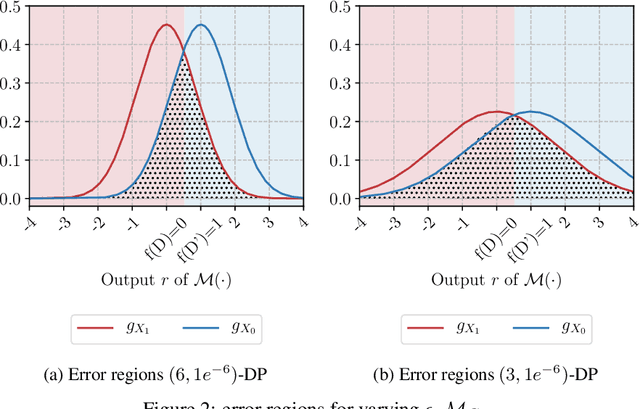
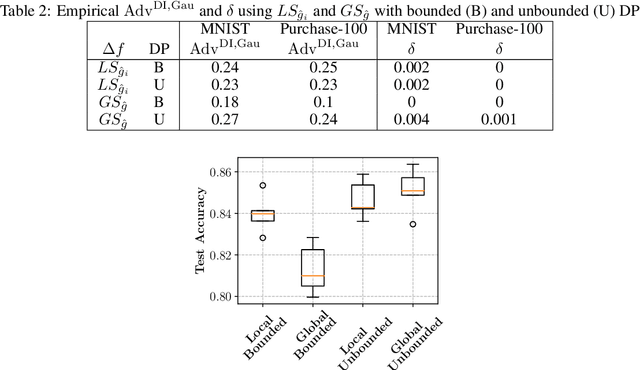
Differential privacy allows bounding the influence that training data records have on a machine learning model. To use differential privacy in machine learning, data scientists must choose privacy parameters $(\epsilon,\delta)$. Choosing meaningful privacy parameters is key since models trained with weak privacy parameters might result in excessive privacy leakage, while strong privacy parameters might overly degrade model utility. However, privacy parameter values are difficult to choose for two main reasons. First, the upper bound on privacy loss $(\epsilon,\delta)$ might be loose, depending on the chosen sensitivity and data distribution of practical datasets. Second, legal requirements and societal norms for anonymization often refer to individual identifiability, to which $(\epsilon,\delta)$ are only indirectly related. We transform $(\epsilon,\delta)$ to a bound on the Bayesian posterior belief of the adversary assumed by differential privacy concerning the presence of any record in the training dataset. The bound holds for multidimensional queries under composition, and we show that it can be tight in practice. Furthermore, we derive an identifiability bound, which relates the adversary assumed in differential privacy to previous work on membership inference adversaries. We formulate an implementation of this differential privacy adversary that allows data scientists to audit model training and compute empirical identifiability scores and empirical $(\epsilon,\delta)$.