 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel network for classification of cuneiform tablet metadata
Mar 04, 2026In this paper, we present a network structure for classifying metadata of cuneiform tablets. The problem is of practical importance, as the size of the existing corpus far exceeds the number of experts available to analyze it. But the task is made difficult by the combination of limited annotated datasets and the high-resolution point-cloud representation of each tablet. To address this, we develop a convolution-inspired architecture that gradually down-scales the point cloud while integrating local neighbor information. The final down-scaled point cloud is then processed by computing neighbors in the feature space to include global information. Our method is compared with the state-of-the-art transformer-based network Point-BERT, and consistently obtains the best performance. Source code and datasets will be released at publication.
Estimation of Confidence Bounds in Binary Classification using Wilson Score Kernel Density Estimation
Feb 24, 2026The performance and ease of use of deep learning-based binary classifiers have improved significantly in recent years. This has opened up the potential for automating critical inspection tasks, which have traditionally only been trusted to be done manually. However, the application of binary classifiers in critical operations depends on the estimation of reliable confidence bounds such that system performance can be ensured up to a given statistical significance. We present Wilson Score Kernel Density Classification, which is a novel kernel-based method for estimating confidence bounds in binary classification. The core of our method is the Wilson Score Kernel Density Estimator, which is a function estimator for estimating confidence bounds in Binomial experiments with conditionally varying success probabilities. Our method is evaluated in the context of selective classification on four different datasets, illustrating its use as a classification head of any feature extractor, including vision foundation models. Our proposed method shows similar performance to Gaussian Process Classification, but at a lower computational complexity.
Object Pose Distribution Estimation for Determining Revolution and Reflection Uncertainty in Point Clouds
Dec 08, 2025Object pose estimation is crucial to robotic perception and typically provides a single-pose estimate. However, a single estimate cannot capture pose uncertainty deriving from visual ambiguity, which can lead to unreliable behavior. Existing pose distribution methods rely heavily on color information, often unavailable in industrial settings. We propose a novel neural network-based method for estimating object pose uncertainty using only 3D colorless data. To the best of our knowledge, this is the first approach that leverages deep learning for pose distribution estimation without relying on RGB input. We validate our method in a real-world bin picking scenario with objects of varying geometric ambiguity. Our current implementation focuses on symmetries in reflection and revolution, but the framework is extendable to full SE(3) pose distribution estimation. Source code available at opde3d.github.io
Good Grasps Only: A data engine for self-supervised fine-tuning of pose estimation using grasp poses for verification
Sep 17, 2024In this paper, we present a novel method for self-supervised fine-tuning of pose estimation for bin-picking. Leveraging zero-shot pose estimation, our approach enables the robot to automatically obtain training data without manual labeling. After pose estimation the object is grasped, and in-hand pose estimation is used for data validation. Our pipeline allows the system to fine-tune while the process is running, removing the need for a learning phase. The motivation behind our work lies in the need for rapid setup of pose estimation solutions. Specifically, we address the challenging task of bin picking, which plays a pivotal role in flexible robotic setups. Our method is implemented on a robotics work-cell, and tested with four different objects. For all objects, our method increases the performance and outperforms a state-of-the-art method trained on the CAD model of the objects.
Off-the-shelf bin picking workcell with visual pose estimation: A case study on the world robot summit 2018 kitting task
Sep 28, 2023



The World Robot Summit 2018 Assembly Challenge included four different tasks. The kitting task, which required bin-picking, was the task in which the fewest points were obtained. However, bin-picking is a vital skill that can significantly increase the flexibility of robotic set-ups, and is, therefore, an important research field. In recent years advancements have been made in sensor technology and pose estimation algorithms. These advancements allow for better performance when performing visual pose estimation. This paper shows that by utilizing new vision sensors and pose estimation algorithms pose estimation in bins can be performed successfully. We also implement a workcell for bin picking along with a force based grasping approach to perform the complete bin picking. Our set-up is tested on the World Robot Summit 2018 Assembly Challenge and successfully obtains a higher score compared with all teams at the competition. This demonstrate that current technology can perform bin-picking at a much higher level compared with previous results.
GP3D: Generalized Pose Estimation in 3D Point Clouds: A case study on bin picking
Mar 28, 2023In this paper, we present GP3D, a novel network for generalized pose estimation in 3D point clouds. The method generalizes to new objects by using both the scene point cloud and the object point cloud with keypoint indexes as input. The network is trained to match the object keypoints to scene points. To address the pose estimation of novel objects we also present a new approach for training pose estimation. The typical solution is a single model trained for pose estimation of a specific object in any scenario. This has several drawbacks: training a model for each object is time-consuming, energy consuming, and by excluding the scenario information the task becomes more difficult. In this paper, we present the opposite solution; a scenario-specific pose estimation method for novel objects that do not require retraining. The network is trained on 1500 objects and is able to learn a generalized solution. We demonstrate that the network is able to correctly predict novel objects, and demonstrate the ability of the network to perform outside of the trained class. We believe that the demonstrated method is a valuable solution for many real-world scenarios. Code and trained network will be made available after publication.
SpyroPose: Importance Sampling Pyramids for Object Pose Distribution Estimation in SE(3)
Mar 09, 2023



Object pose estimation is a core computer vision problem and often an essential component in robotics. Pose estimation is usually approached by seeking the single best estimate of an object's pose, but this approach is ill-suited for tasks involving visual ambiguity. In such cases it is desirable to estimate the uncertainty as a pose distribution to allow downstream tasks to make informed decisions. Pose distributions can have arbitrary complexity which motivates estimating unparameterized distributions, however, until now they have only been used for orientation estimation on SO(3) due to the difficulty in training on and normalizing over SE(3). We propose a novel method for pose distribution estimation on SE(3). We use a hierarchical grid, a pyramid, which enables efficient importance sampling during training and sparse evaluation of the pyramid at inference, allowing real time 6D pose distribution estimation. Our method outperforms state-of-the-art methods on SO(3), and to the best of our knowledge, we provide the first quantitative results on pose distribution estimation on SE(3). Code will be available at spyropose.github.io
PointPoseNet: Accurate Object Detection and 6 DoF Pose Estimation in Point Clouds
Dec 19, 2019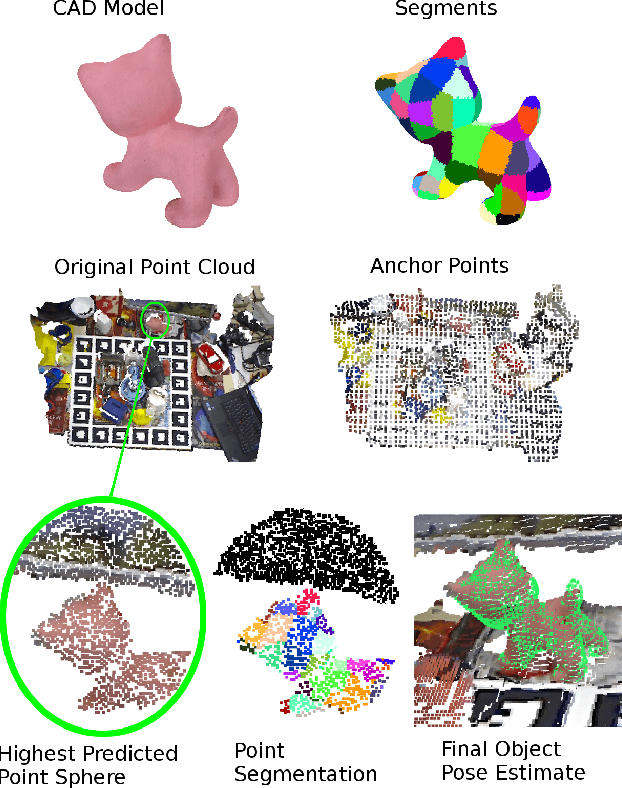
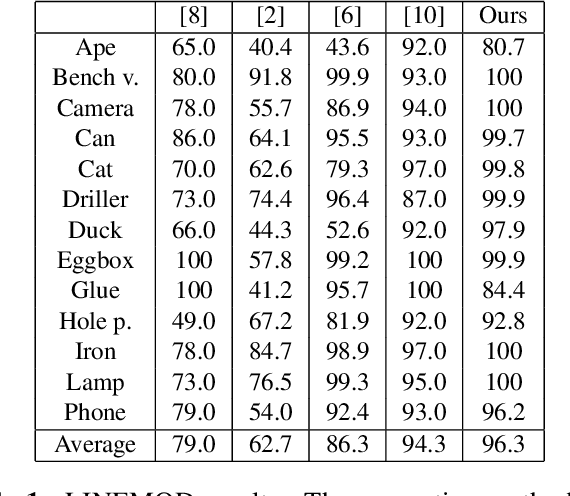
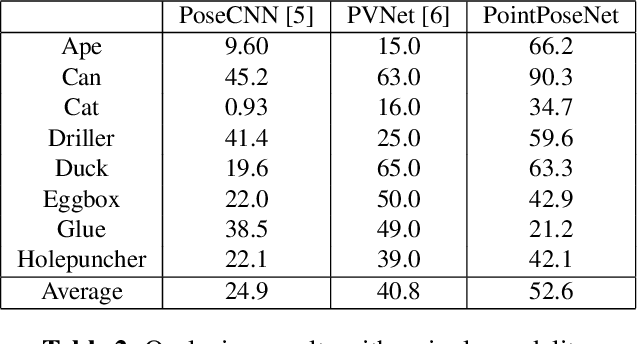
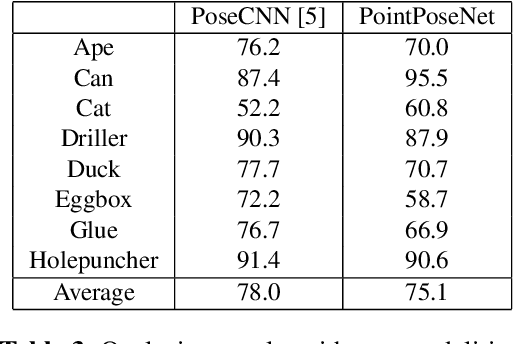
We present a learning-based method for 6 DoF pose estimation of rigid objects in point cloud data. Many recent learning-based approaches use primarily RGB information for detecting objects, in some cases with an added refinement step using depth data. Our method consumes unordered point sets with/without RGB information, from initial detection to the final transformation estimation stage. This allows us to achieve accurate pose estimates, in some cases surpassing state of the art methods trained on the same data.