 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-mtML: Coupled Projection multi-task Metric Learning for Large Scale Face Retrieval
Apr 11, 2016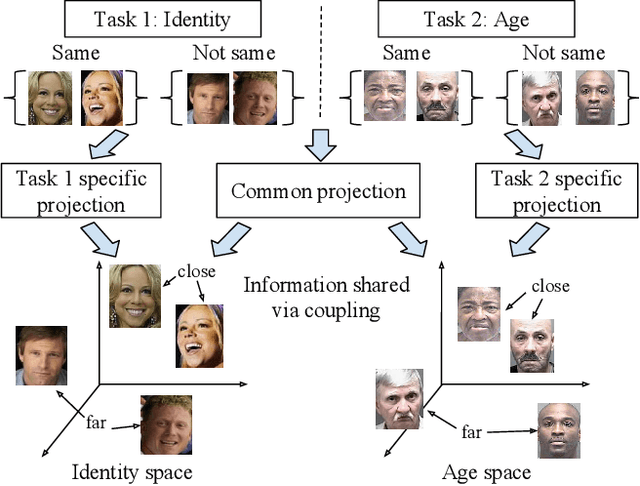
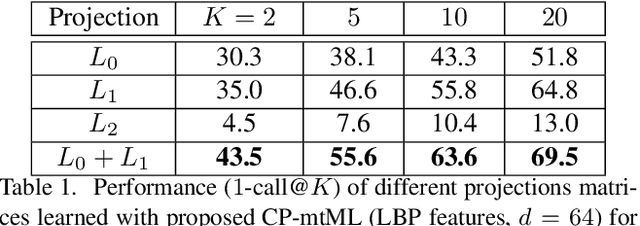
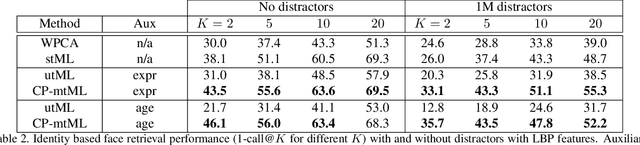
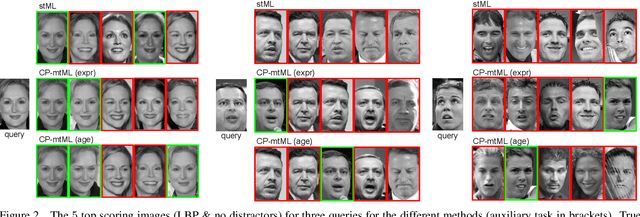
We propose a novel Coupled Projection multi-task Metric Learning (CP-mtML) method for large scale face retrieval. In contrast to previous works which were limited to low dimensional features and small datasets, the proposed method scales to large datasets with high dimensional face descriptors. It utilises pairwise (dis-)similarity constraints as supervision and hence does not require exhaustive class annotation for every training image. While, traditionally, multi-task learning methods have been validated on same dataset but different tasks, we work on the more challenging setting with heterogeneous datasets and different tasks. We show empirical validation on multiple face image datasets of different facial traits, e.g. identity, age and expression. We use classic Local Binary Pattern (LBP) descriptors along with the recent Deep Convolutional Neural Network (CNN) features. The experiments clearly demonstrate the scalability and improved performance of the proposed method on the tasks of identity and age based face image retrieval compared to competitive existing methods, on the standard datasets and with the presence of a million distractor face images.
Expanded Parts Model for Semantic Description of Humans in Still Images
Feb 25, 2016
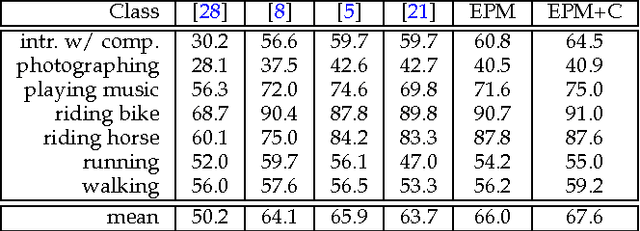
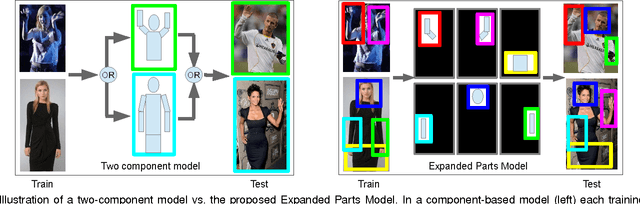
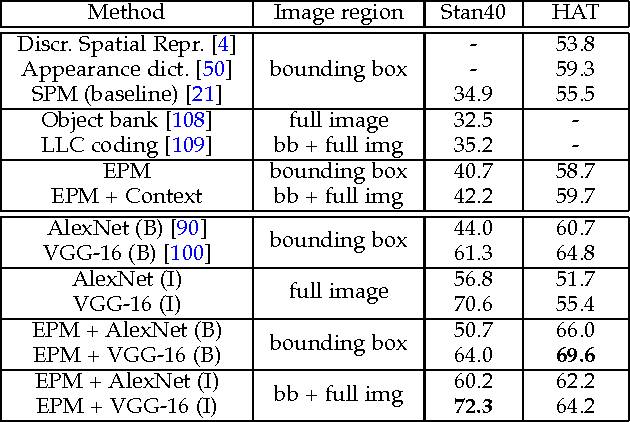
We introduce an Expanded Parts Model (EPM) for recognizing human attributes (e.g. young, short hair, wearing suit) and actions (e.g. running, jumping) in still images. An EPM is a collection of part templates which are learnt discriminatively to explain specific scale-space regions in the images (in human centric coordinates). This is in contrast to current models which consist of a relatively few (i.e. a mixture of) 'average' templates. EPM uses only a subset of the parts to score an image and scores the image sparsely in space, i.e. it ignores redundant and random background in an image. To learn our model, we propose an algorithm which automatically mines parts and learns corresponding discriminative templates together with their respective locations from a large number of candidate parts. We validate our method on three recent challenging datasets of human attributes and actions. We obtain convincing qualitative and state-of-the-art quantitative results on the three datasets.
Local Higher-Order Statistics (LHS) describing images with statistics of local non-binarized pixel patterns
Oct 02, 2015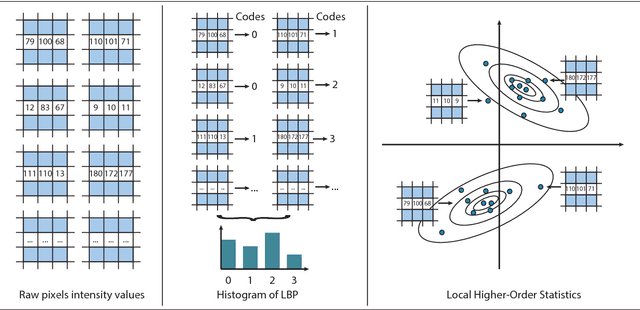
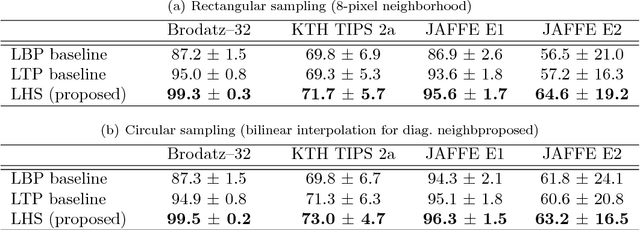
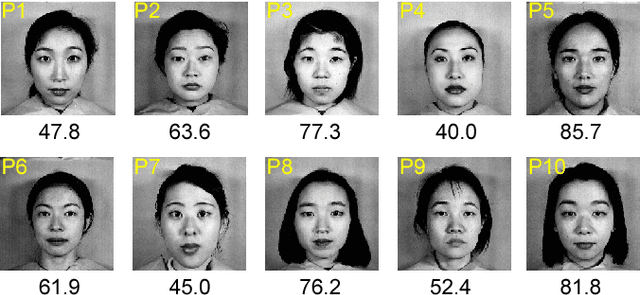
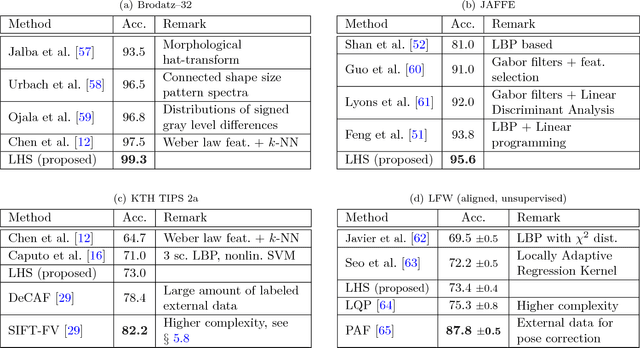
We propose a new image representation for texture categorization and facial analysis, relying on the use of higher-order local differential statistics as features. It has been recently shown that small local pixel pattern distributions can be highly discriminative while being extremely efficient to compute, which is in contrast to the models based on the global structure of images. Motivated by such works, we propose to use higher-order statistics of local non-binarized pixel patterns for the image description. The proposed model does not require either (i) user specified quantization of the space (of pixel patterns) or (ii) any heuristics for discarding low occupancy volumes of the space. We propose to use a data driven soft quantization of the space, with parametric mixture models, combined with higher-order statistics, based on Fisher scores. We demonstrate that this leads to a more expressive representation which, when combined with discriminatively learned classifiers and metrics, achieves state-of-the-art performance on challenging texture and facial analysis datasets, in low complexity setup. Further, it is complementary to higher complexity features and when combined with them improves performance.
Hybrid multi-layer Deep CNN/Aggregator feature for image classification
Mar 13, 2015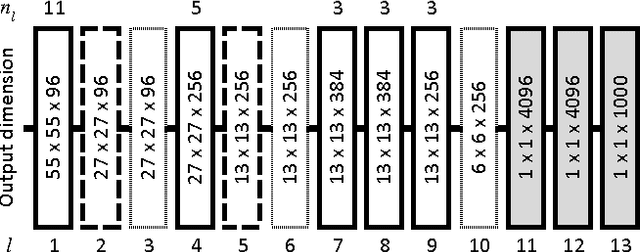

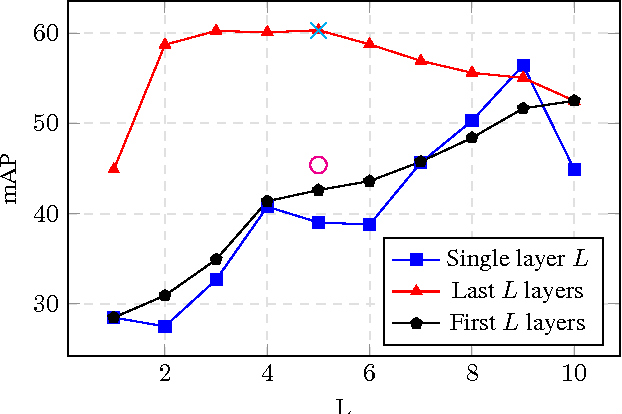
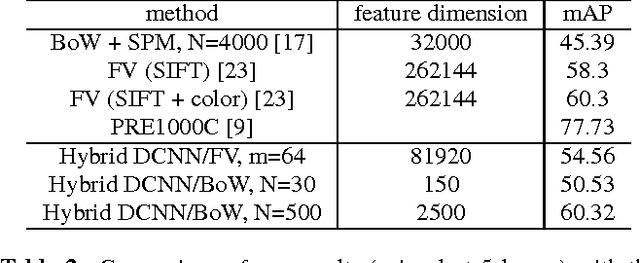
Deep Convolutional Neural Networks (DCNN) have established a remarkable performance benchmark in the field of image classification, displacing classical approaches based on hand-tailored aggregations of local descriptors. Yet DCNNs impose high computational burdens both at training and at testing time, and training them requires collecting and annotating large amounts of training data. Supervised adaptation methods have been proposed in the literature that partially re-learn a transferred DCNN structure from a new target dataset. Yet these require expensive bounding-box annotations and are still computationally expensive to learn. In this paper, we address these shortcomings of DCNN adaptation schemes by proposing a hybrid approach that combines conventional, unsupervised aggregators such as Bag-of-Words (BoW), with the DCNN pipeline by treating the output of intermediate layers as densely extracted local descriptors. We test a variant of our approach that uses only intermediate DCNN layers on the standard PASCAL VOC 2007 dataset and show performance significantly higher than the standard BoW model and comparable to Fisher vector aggregation but with a feature that is 150 times smaller. A second variant of our approach that includes the fully connected DCNN layers significantly outperforms Fisher vector schemes and performs comparably to DCNN approaches adapted to Pascal VOC 2007, yet at only a small fraction of the training and testing cost.