 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreddie Kalaitzis
Exploring DINO: Emergent Properties and Limitations for Synthetic Aperture Radar Imagery
Oct 05, 2023
Self-supervised learning (SSL) models have recently demonstrated remarkable performance across various tasks, including image segmentation. This study delves into the emergent characteristics of the Self-Distillation with No Labels (DINO) algorithm and its application to Synthetic Aperture Radar (SAR) imagery. We pre-train a vision transformer (ViT)-based DINO model using unlabeled SAR data, and later fine-tune the model to predict high-resolution land cover maps. We rigorously evaluate the utility of attention maps generated by the ViT backbone, and compare them with the model's token embedding space. We observe a small improvement in model performance with pre-training compared to training from scratch, and discuss the limitations and opportunities of SSL for remote sensing and land cover segmentation. Beyond small performance increases, we show that ViT attention maps hold great intrinsic value for remote sensing, and could provide useful inputs to other algorithms. With this, our work lays the ground-work for bigger and better SSL models for Earth Observation.
Exploring Generalisability of Self-Distillation with No Labels for SAR-Based Vegetation Prediction
Oct 03, 2023In this work we pre-train a DINO-ViT based model using two Synthetic Aperture Radar datasets (S1GRD or GSSIC) across three regions (China, Conus, Europe). We fine-tune the models on smaller labeled datasets to predict vegetation percentage, and empirically study the connection between the embedding space of the models and their ability to generalize across diverse geographic regions and to unseen data. For S1GRD, embedding spaces of different regions are clearly separated, while GSSIC's overlaps. Positional patterns remain during fine-tuning, and greater distances in embeddings often result in higher errors for unfamiliar regions. With this, our work increases our understanding of generalizability for self-supervised models applied to remote sensing.
Large Scale Masked Autoencoding for Reducing Label Requirements on SAR Data
Oct 02, 2023Satellite-based remote sensing is instrumental in the monitoring and mitigation of the effects of anthropogenic climate change. Large scale, high resolution data derived from these sensors can be used to inform intervention and policy decision making, but the timeliness and accuracy of these interventions is limited by use of optical data, which cannot operate at night and is affected by adverse weather conditions. Synthetic Aperture Radar (SAR) offers a robust alternative to optical data, but its associated complexities limit the scope of labelled data generation for traditional deep learning. In this work, we apply a self-supervised pretraining scheme, masked autoencoding, to SAR amplitude data covering 8.7\% of the Earth's land surface area, and tune the pretrained weights on two downstream tasks crucial to monitoring climate change - vegetation cover prediction and land cover classification. We show that the use of this pretraining scheme reduces labelling requirements for the downstream tasks by more than an order of magnitude, and that this pretraining generalises geographically, with the performance gain increasing when tuned downstream on regions outside the pretraining set. Our findings significantly advance climate change mitigation by facilitating the development of task and region-specific SAR models, allowing local communities and organizations to deploy tailored solutions for rapid, accurate monitoring of climate change effects.
Fewshot learning on global multimodal embeddings for earth observation tasks
Sep 29, 2023In this work we pretrain a CLIP/ViT based model using three different modalities of satellite imagery across five AOIs covering over ~10\% of the earth total landmass, namely Sentinel 2 RGB optical imagery, Sentinel 1 SAR amplitude and Sentinel 1 SAR interferometric coherence. This model uses $\sim 250$ M parameters. Then, we use the embeddings produced for each modality with a classical machine learning method to attempt different downstream tasks for earth observation related to vegetation, built up surface, croplands and permanent water. We consistently show how we reduce the need for labeled data by 99\%, so that with ~200-500 randomly selected labeled examples (around 4K-10K km$^2$) we reach performance levels analogous to those achieved with the full labeled datasets (about 150K image chips or 3M km$^2$ in each AOI) on all modalities, AOIs and downstream tasks. This leads us to think that the model has captured significant earth features useful in a wide variety of scenarios. To enhance our model's usability in practice, its architecture allows inference in contexts with missing modalities and even missing channels within each modality. Additionally, we visually show that this embedding space, obtained with no labels, is sensible to the different earth features represented by the labelled datasets we selected.
A Contrastive Method Based on Elevation Data for Remote Sensing with Scarce and High Level Semantic Labels
Apr 17, 2023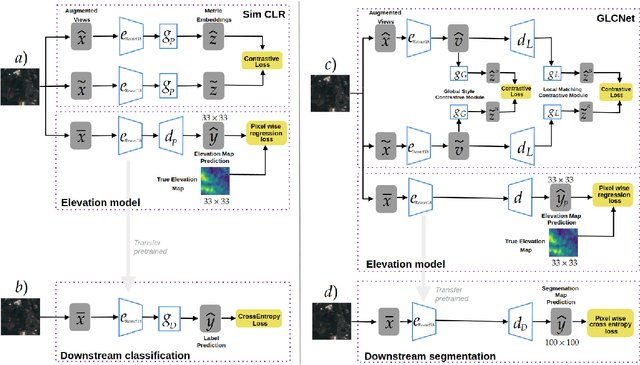
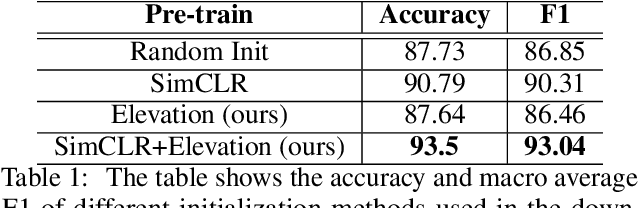
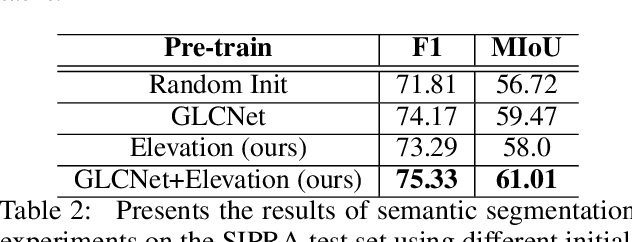
This work proposes a hybrid unsupervised/supervised learning method to pretrain models applied in earth observation downstream tasks where only a handful of labels denoting very general semantic concepts are available. We combine a contrastive approach to pretrain models with a pretext task to predict spatially coarse elevation maps which are commonly available worldwide. The intuition behind is that there is generally some correlation between the elevation and targets in many remote sensing tasks, allowing the model to pre-learn useful representations. We assess the performance of our approach on a segmentation downstream task on labels gathering many possible subclasses (pixel level classification of farmlands vs. other) and an image binary classification task derived from the former, on a dataset on the north-east of Colombia. On both cases we pretrain our models with 39K unlabeled images, fine tune the downstream task only with 80 labeled images and test it with 2944 labeled images. Our experiments show that our methods, GLCNet+Elevation for segmentation and SimCLR+Elevation for classification, outperform their counterparts without the elevation pretext task in terms of accuracy and macro-average F1, which supports the notion that including additional information correlated to targets in downstream tasks can lead to improved performance.
Deep learning based landslide density estimation on SAR data for rapid response
Nov 18, 2022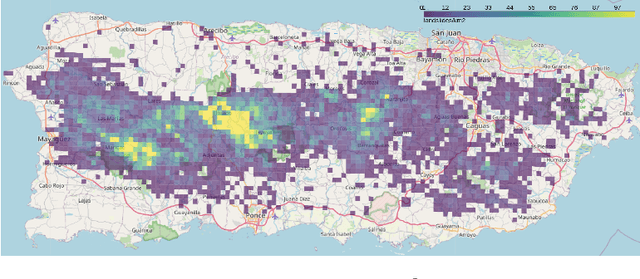
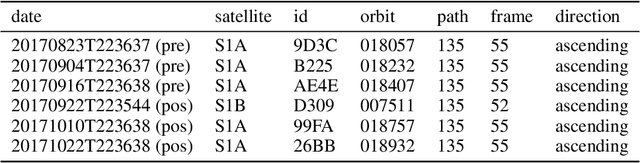
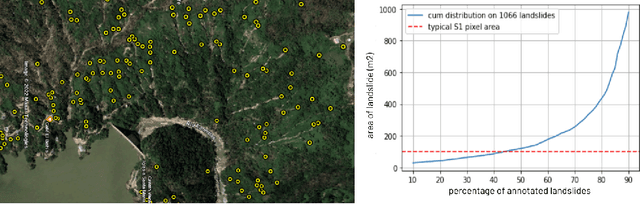
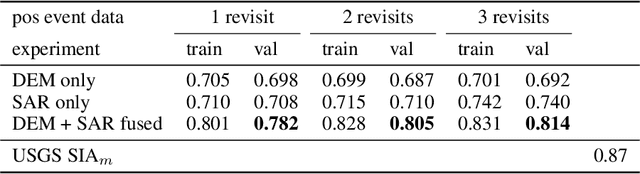
This work aims to produce landslide density estimates using Synthetic Aperture Radar (SAR) satellite imageries to prioritise emergency resources for rapid response. We use the United States Geological Survey (USGS) Landslide Inventory data annotated by experts after Hurricane Mar\'ia in Puerto Rico on Sept 20, 2017, and their subsequent susceptibility study which uses extensive additional information such as precipitation, soil moisture, geological terrain features, closeness to waterways and roads, etc. Since such data might not be available during other events or regions, we aimed to produce a landslide density map using only elevation and SAR data to be useful to decision-makers in rapid response scenarios. The USGS Landslide Inventory contains the coordinates of 71,431 landslide heads (not their full extent) and was obtained by manual inspection of aerial and satellite imagery. It is estimated that around 45\% of the landslides are smaller than a Sentinel-1 typical pixel which is 10m $\times$ 10m, although many are long and thin, probably leaving traces across several pixels. Our method obtains 0.814 AUC in predicting the correct density estimation class at the chip level (128$\times$128 pixels, at Sentinel-1 resolution) using only elevation data and up to three SAR acquisitions pre- and post-hurricane, thus enabling rapid assessment after a disaster. The USGS Susceptibility Study reports a 0.87 AUC, but it is measured at the landslide level and uses additional information sources (such as proximity to fluvial channels, roads, precipitation, etc.) which might not regularly be available in an rapid response emergency scenario.
SAR-based landslide classification pretraining leads to better segmentation
Nov 17, 2022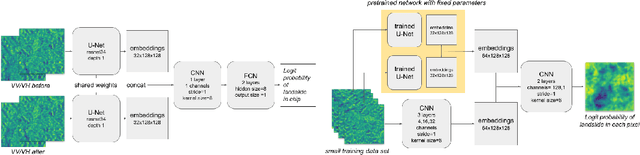
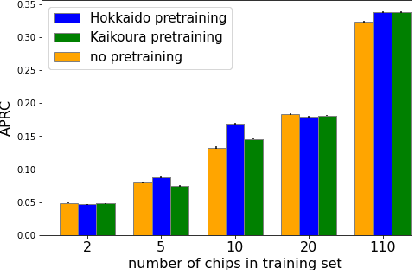
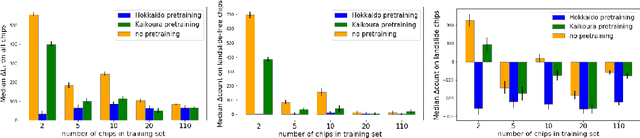
Rapid assessment after a natural disaster is key for prioritizing emergency resources. In the case of landslides, rapid assessment involves determining the extent of the area affected and measuring the size and location of individual landslides. Synthetic Aperture Radar (SAR) is an active remote sensing technique that is unaffected by weather conditions. Deep Learning algorithms can be applied to SAR data, but training them requires large labeled datasets. In the case of landslides, these datasets are laborious to produce for segmentation, and often they are not available for the specific region in which the event occurred. Here, we study how deep learning algorithms for landslide segmentation on SAR products can benefit from pretraining on a simpler task and from data from different regions. The method we explore consists of two training stages. First, we learn the task of identifying whether a SAR image contains any landslides or not. Then, we learn to segment in a sparsely labeled scenario where half of the data do not contain landslides. We test whether the inclusion of feature embeddings derived from stage-1 helps with landslide detection in stage-2. We find that it leads to minor improvements in the Area Under the Precision-Recall Curve, but also to a significantly lower false positive rate in areas without landslides and an improved estimate of the average number of landslide pixels in a chip. A more accurate pixel count allows to identify the most affected areas with higher confidence. This could be valuable in rapid response scenarios where prioritization of resources at a global scale is important. We make our code publicly available at https://github.com/VMBoehm/SAR-landslide-detection-pretraining.
Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes
Nov 05, 2022

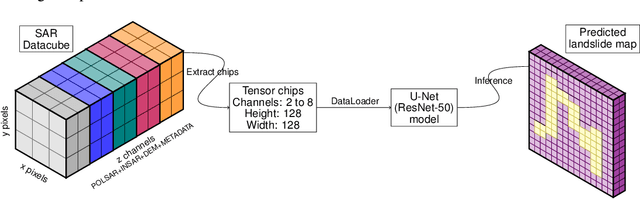
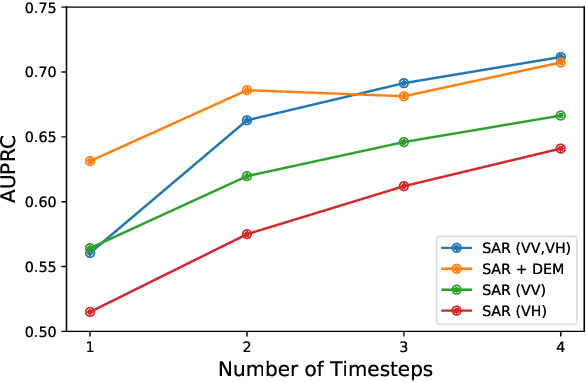
With climate change predicted to increase the likelihood of landslide events, there is a growing need for rapid landslide detection technologies that help inform emergency responses. Synthetic Aperture Radar (SAR) is a remote sensing technique that can provide measurements of affected areas independent of weather or lighting conditions. Usage of SAR, however, is hindered by domain knowledge that is necessary for the pre-processing steps and its interpretation requires expert knowledge. We provide simplified, pre-processed, machine-learning ready SAR datacubes for four globally located landslide events obtained from several Sentinel-1 satellite passes before and after a landslide triggering event together with segmentation maps of the landslides. From this dataset, using the Hokkaido, Japan datacube, we study the feasibility of SAR-based landslide detection with supervised deep learning (DL). Our results demonstrate that DL models can be used to detect landslides from SAR data, achieving an Area under the Precision-Recall curve exceeding 0.7. We find that additional satellite visits enhance detection performance, but that early detection is possible when SAR data is combined with terrain information from a digital elevation model. This can be especially useful for time-critical emergency interventions. Code is made publicly available at https://github.com/iprapas/landslide-sar-unet.
Open High-Resolution Satellite Imagery: The WorldStrat Dataset -- With Application to Super-Resolution
Jul 13, 2022

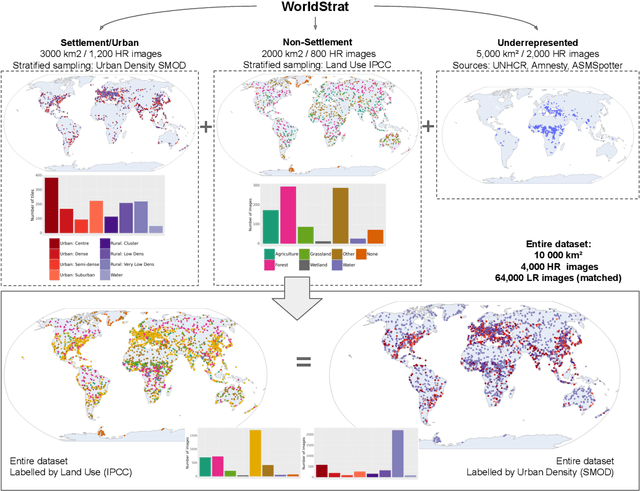
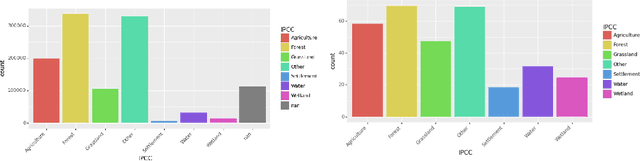
Analyzing the planet at scale with satellite imagery and machine learning is a dream that has been constantly hindered by the cost of difficult-to-access highly-representative high-resolution imagery. To remediate this, we introduce here the WorldStrat dataset. The largest and most varied such publicly available dataset, at Airbus SPOT 6/7 satellites' high resolution of up to 1.5 m/pixel, empowered by European Space Agency's Phi-Lab as part of the ESA-funded QueryPlanet project, we curate nearly 10,000 sqkm of unique locations to ensure stratified representation of all types of land-use across the world: from agriculture to ice caps, from forests to multiple urbanization densities. We also enrich those with locations typically under-represented in ML datasets: sites of humanitarian interest, illegal mining sites, and settlements of persons at risk. We temporally-match each high-resolution image with multiple low-resolution images from the freely accessible lower-resolution Sentinel-2 satellites at 10 m/pixel. We accompany this dataset with an open-source Python package to: rebuild or extend the WorldStrat dataset, train and infer baseline algorithms, and learn with abundant tutorials, all compatible with the popular EO-learn toolbox. We hereby hope to foster broad-spectrum applications of ML to satellite imagery, and possibly develop from free public low-resolution Sentinel2 imagery the same power of analysis allowed by costly private high-resolution imagery. We illustrate this specific point by training and releasing several highly compute-efficient baselines on the task of Multi-Frame Super-Resolution. High-resolution Airbus imagery is CC BY-NC, while the labels and Sentinel2 imagery are CC BY, and the source code and pre-trained models under BSD. The dataset is available at https://zenodo.org/record/6810792 and the software package at https://github.com/worldstrat/worldstrat .
Multi-Spectral Multi-Image Super-Resolution of Sentinel-2 with Radiometric Consistency Losses and Its Effect on Building Delineation
Nov 05, 2021
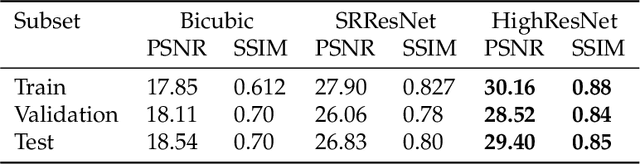
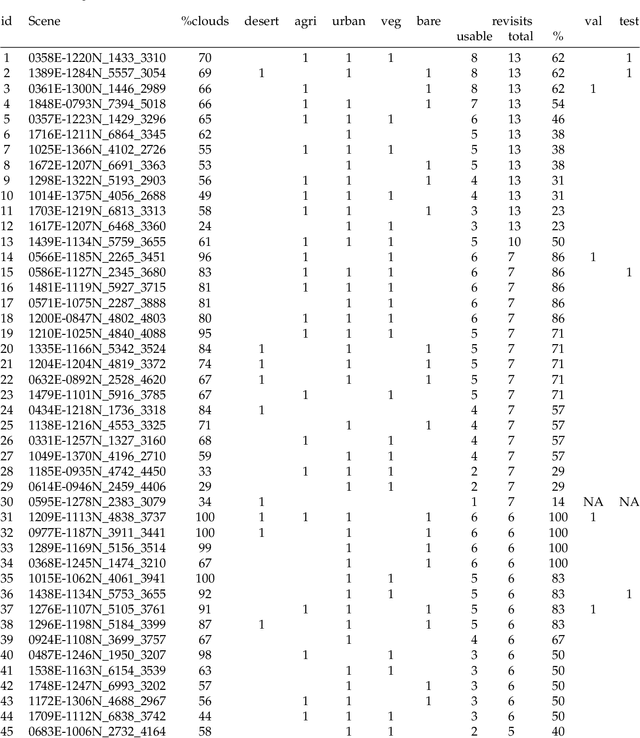
High resolution remote sensing imagery is used in broad range of tasks, including detection and classification of objects. High-resolution imagery is however expensive, while lower resolution imagery is often freely available and can be used by the public for range of social good applications. To that end, we curate a multi-spectral multi-image super-resolution dataset, using PlanetScope imagery from the SpaceNet 7 challenge as the high resolution reference and multiple Sentinel-2 revisits of the same imagery as the low-resolution imagery. We present the first results of applying multi-image super-resolution (MISR) to multi-spectral remote sensing imagery. We, additionally, introduce a radiometric consistency module into MISR model the to preserve the high radiometric resolution of the Sentinel-2 sensor. We show that MISR is superior to single-image super-resolution and other baselines on a range of image fidelity metrics. Furthermore, we conduct the first assessment of the utility of multi-image super-resolution on building delineation, showing that utilising multiple images results in better performance in these downstream tasks.