 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Energy Consumption Forecasting in Puno using Parallel Computing and ARIMA Models: An Innovative Approach to Big Data Processing
Jul 27, 2024This research presents an innovative use of parallel computing with the ARIMA (AutoRegressive Integrated Moving Average) model to forecast energy consumption in Peru's Puno region. The study conducts a thorough and multifaceted analysis, focusing on the execution speed, prediction accuracy, and scalability of both sequential and parallel implementations. A significant emphasis is placed on efficiently managing large datasets. The findings demonstrate notable improvements in computational efficiency and data processing capabilities through the parallel approach, all while maintaining the accuracy and integrity of predictions. This new method provides a versatile and reliable solution for real-time predictive analysis and enhances energy resource management, which is particularly crucial for developing areas. In addition to highlighting the technical advantages of parallel computing in this field, the study explores its practical impacts on energy planning and sustainable development in regions like Puno.
Machine Learning Applied to Peruvian Vegetables Imports
Jan 08, 2023The current research work is being developed as a training and evaluation object. the performance of a predictive model to apply it to the imports of vegetable products into Peru using artificial intelligence algorithms, specifying for this study the Machine Learning models: LSTM and PROPHET. The forecast is made with data from the monthly record of imports of vegetable products(in kilograms) from Peru, collected from the years 2021 to 2022. As part of applying the training methodology for automatic learning algorithms, the exploration and construction of an appropriate dataset according to the parameters of a Time Series. Subsequently, the model with better performance will be selected, evaluating the precision of the predicted values so that they account for sufficient reliability to consider it a useful resource in the forecast of imports in Peru.
Noise Reduction in Medical Images
Jan 04, 2023Objectives: Analyze the types of studies and algorithms that are most applied, Identify the anatomical regions treated. Determine the application of parallel techniques used in studies carried out between 2010 and 2022 in research on noise reduction in medical images. Methodology: A systematic review of the literature on noise reduction in medical images in the last 12 years was carried out. The observation technique was applied to extract the information and the indicators (type of study, treated anatomical region, algorithm and or method and the application of parallel computing) were recorded in a data sheet. Results: Most of the studies have been developed in anatomical regions such as: Brain, Bones, Heart, Breast, Lung and Visual system. In the articles investigated, 14 are applied through parallel computing. Conclution: Noise reduction in medical images can contribute to better quality images and thus make a more accurate and effective diagnosis.
Quantum Machine Learning Applied to the Classification of Diabetes
Dec 31, 2022Quantum Machine Learning (QML) shows how it maintains certain significant advantages over machine learning methods. It now shows that hybrid quantum methods have great scope for deployment and optimisation, and hold promise for future industries. As a weakness, quantum computing does not have enough qubits to justify its potential. This topic of study gives us encouraging results in the improvement of quantum coding, being the data preprocessing an important point in this research we employ two dimensionality reduction techniques LDA and PCA applying them in a hybrid way Quantum Support Vector Classifier (QSVC) and Variational Quantum Classifier (VQC) in the classification of Diabetes.
Unsupervised Learning Algorithms for Keyword Extraction in an Undergraduate Thesis
Jun 23, 2022
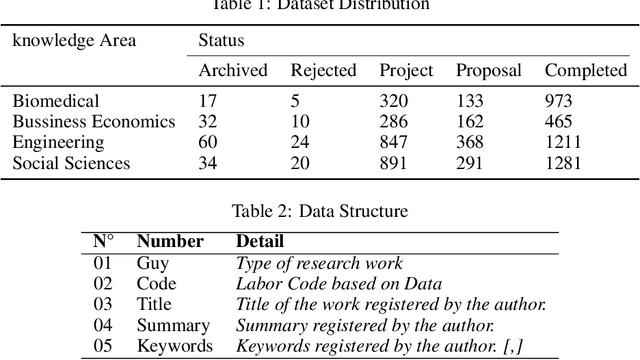
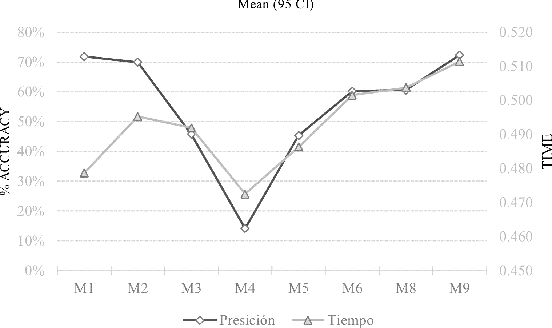
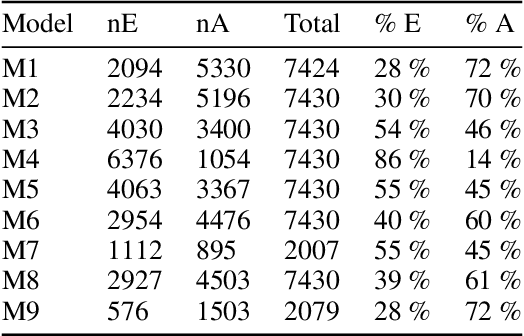
The amount of data managed in many academic institutions has increased in recent years, particularly in all the research work done by undergraduate students, who simply use empirical techniques for keyword selection, forgetting existing technical methods to assist their students in this process. Information and communication technologies, such as the platform for integrated research and academic work with responsibility (PILAR), which records information about research projects, such as titles, summaries, and keywords in their various modalities, have gained relevance and importance in the management of these. We proved algorithms with these records of research projects that have been analysed in this study, and predictions were made for each of the nine (09) models of unsupervised machine learning algorithms that were implemented for each of the 7430 records from the dataset. The most efficient way of extracting keywords for this dataset was the TF-IDF method, obtaining 72% accuracy and [0.4786, SD 0.0501] in average extraction time for each thesis file processed by this model.