 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing RNN States with Predictive Semantic Encodings
Aug 01, 2019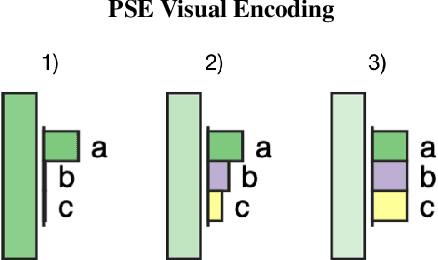
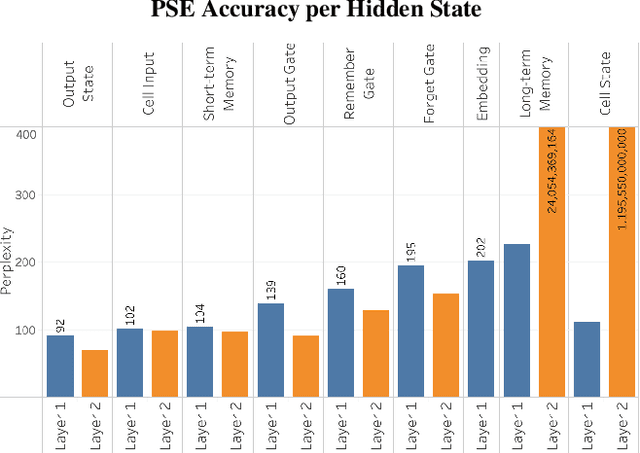
Recurrent Neural Networks are an effective and prevalent tool used to model sequential data such as natural language text. However, their deep nature and massive number of parameters pose a challenge for those intending to study precisely how they work. We present a visual technique that gives a high level intuition behind the semantics of the hidden states within Recurrent Neural Networks. This semantic encoding allows for hidden states to be compared throughout the model independent of their internal details. The proposed technique is displayed in a proof of concept visualization tool which is demonstrated to visualize the natural language processing task of language modelling.
Self-Attention: A Better Building Block for Sentiment Analysis Neural Network Classifiers
Dec 19, 2018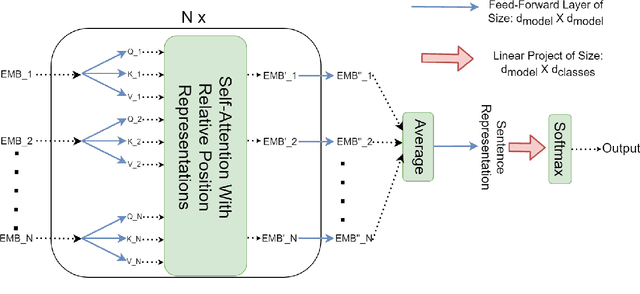
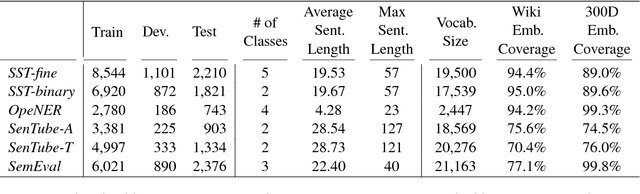
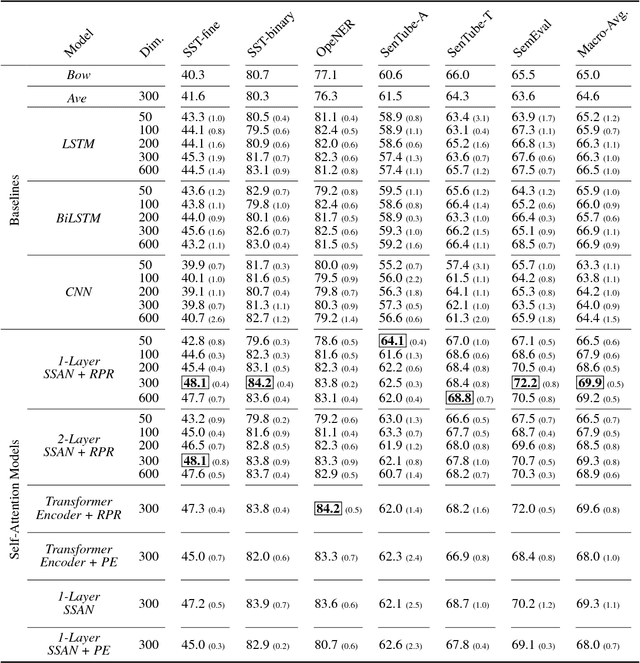
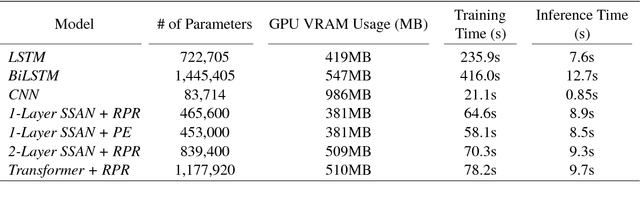
Sentiment Analysis has seen much progress in the past two decades. For the past few years, neural network approaches, primarily RNNs and CNNs, have been the most successful for this task. Recently, a new category of neural networks, self-attention networks (SANs), have been created which utilizes the attention mechanism as the basic building block. Self-attention networks have been shown to be effective for sequence modeling tasks, while having no recurrence or convolutions. In this work we explore the effectiveness of the SANs for sentiment analysis. We demonstrate that SANs are superior in performance to their RNN and CNN counterparts by comparing their classification accuracy on six datasets as well as their model characteristics such as training speed and memory consumption. Finally, we explore the effects of various SAN modifications such as multi-head attention as well as two methods of incorporating sequence position information into SANs.
Opinion Polarity Identification through Adjectives
Nov 21, 2010
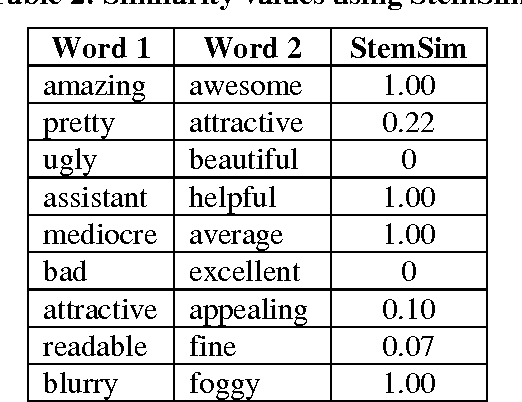
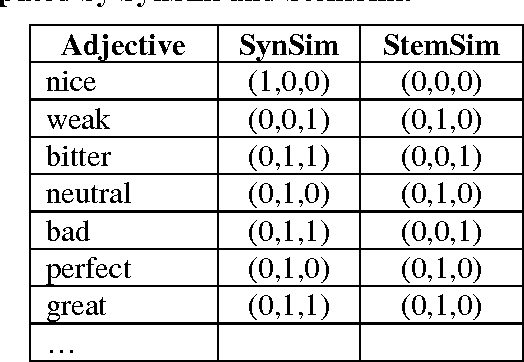

"What other people think" has always been an important piece of information during various decision-making processes. Today people frequently make their opinions available via the Internet, and as a result, the Web has become an excellent source for gathering consumer opinions. There are now numerous Web resources containing such opinions, e.g., product reviews forums, discussion groups, and Blogs. But, due to the large amount of information and the wide range of sources, it is essentially impossible for a customer to read all of the reviews and make an informed decision on whether to purchase the product. It is also difficult for the manufacturer or seller of a product to accurately monitor customer opinions. For this reason, mining customer reviews, or opinion mining, has become an important issue for research in Web information extraction. One of the important topics in this research area is the identification of opinion polarity. The opinion polarity of a review is usually expressed with values 'positive', 'negative' or 'neutral'. We propose a technique for identifying polarity of reviews by identifying the polarity of the adjectives that appear in them. Our evaluation shows the technique can provide accuracy in the area of 73%, which is well above the 58%-64% provided by naive Bayesian classifiers.
A Bootstrap Approach to Automatically Generating Lexical Transfer Rules
Jul 09, 1999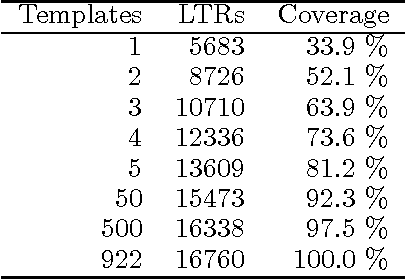
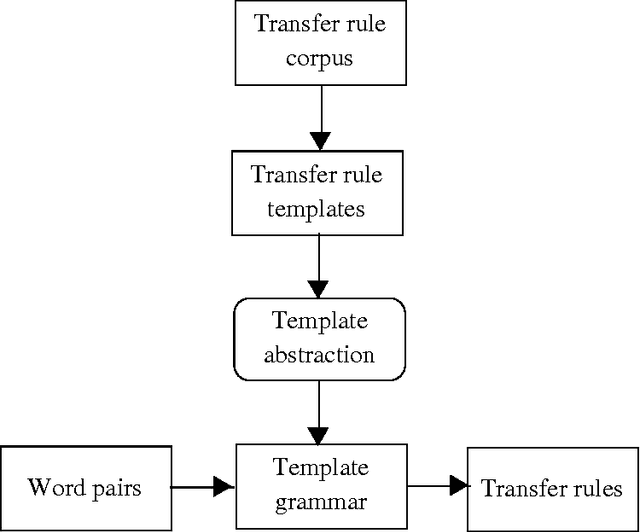

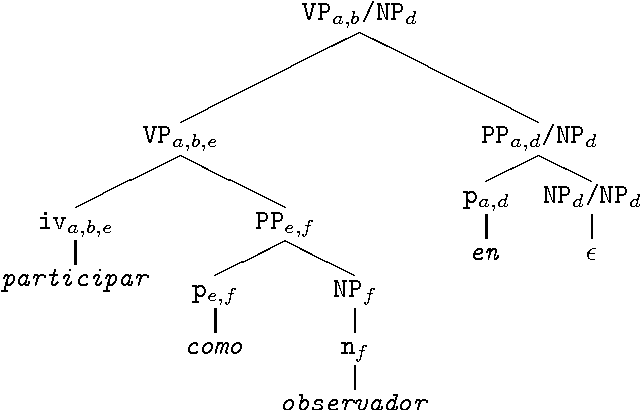
We describe a method for automatically generating Lexical Transfer Rules (LTRs) from word equivalences using transfer rule templates. Templates are skeletal LTRs, unspecified for words. New LTRs are created by instantiating a template with words, provided that the words belong to the appropriate lexical categories required by the template. We define two methods for creating an inventory of templates and using them to generate new LTRs. A simpler method consists of extracting a finite set of templates from a sample of hand coded LTRs and directly using them in the generation process. A further method consists of abstracting over the initial finite set of templates to define higher level templates, where bilingual equivalences are defined in terms of correspondences involving phrasal categories. Phrasal templates are then mapped onto sets of lexical templates with the aid of grammars. In this way an infinite set of lexical templates is recursively defined. New LTRs are created by parsing input words, matching a template at the phrasal level and using the corresponding lexical categories to instantiate the lexical template. The definition of an infinite set of templates enables the automatic creation of LTRs for multi-word, non-compositional word equivalences of any cardinality.
Explanation-based Learning for Machine Translation
Jul 06, 1999
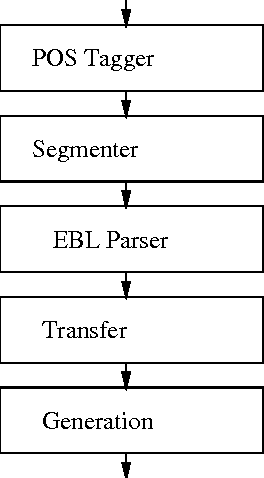

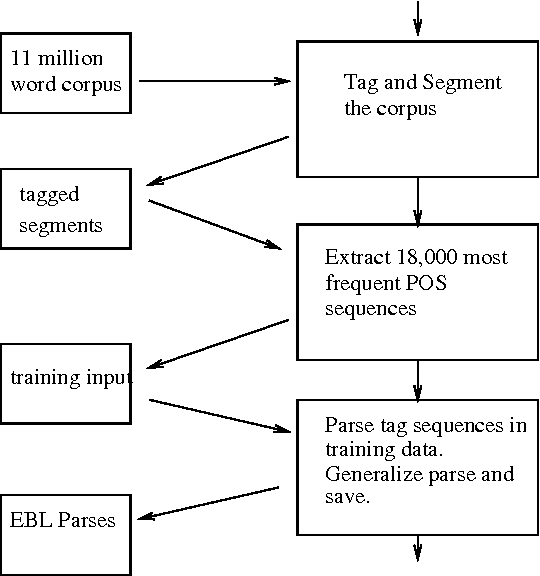
In this paper we present an application of explanation-based learning (EBL) in the parsing module of a real-time English-Spanish machine translation system designed to translate closed captions. We discuss the efficiency/coverage trade-offs available in EBL and introduce the techniques we use to increase coverage while maintaining a high level of space and time efficiency. Our performance results indicate that this approach is effective.
A Unified Example-Based and Lexicalist Approach to Machine Translation
Jun 30, 1999We present an approach to Machine Translation that combines the ideas and methodologies of the Example-Based and Lexicalist theoretical frameworks. The approach has been implemented in a multilingual Machine Translation system.
A Lexicalist Approach to the Translation of Colloquial Text
Jun 18, 1997


Colloquial English (CE) as found in television programs or typical conversations is different than text found in technical manuals, newspapers and books. Phrases tend to be shorter and less sophisticated. In this paper, we look at some of the theoretical and implementational issues involved in translating CE. We present a fully automatic large-scale multilingual natural language processing system for translation of CE input text, as found in the commercially transmitted closed-caption television signal, into simple target sentences. Our approach is based on the Whitelock's Shake and Bake machine translation paradigm, which relies heavily on lexical resources. The system currently translates from English to Spanish with the translation modules for Brazilian Portuguese under development.
* 11 pages, LaTeX, uses tmi.sty
Concept Clustering and Knowledge Integration from a Children's Dictionary
Mar 05, 1997


Knowledge structures called Concept Clustering Knowledge Graphs (CCKGs) are introduced along with a process for their construction from a machine readable dictionary. CCKGs contain multiple concepts interrelated through multiple semantic relations together forming a semantic cluster represented by a conceptual graph. The knowledge acquisition is performed on a children's first dictionary. A collection of conceptual clusters together can form the basis of a lexical knowledge base, where each CCKG contains a limited number of highly connected words giving useful information about a particular domain or situation.
* uses colap.sty
A Chart Generator for Shake and Bake Machine Translation
May 10, 1996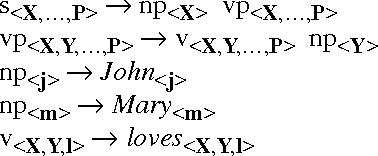
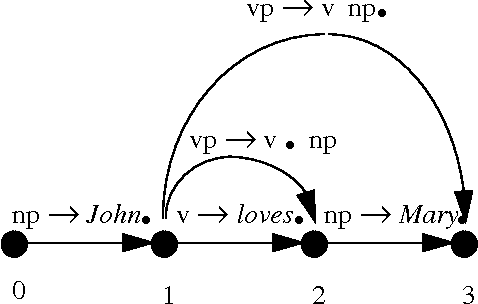
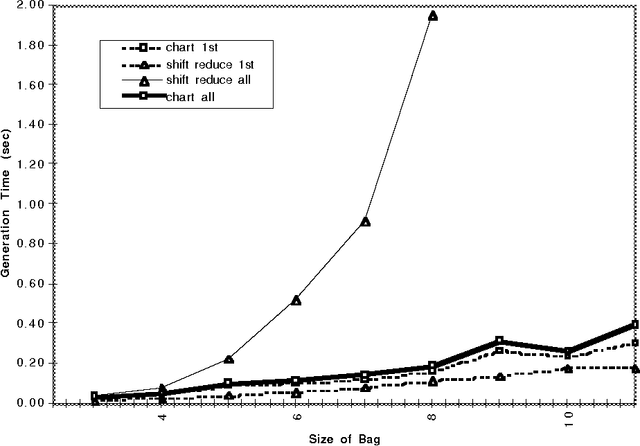
A generation algorithm based on an active chart parsing algorithm is introduced which can be used in conjunction with a Shake and Bake machine translation system. A concise Prolog implementation of the algorithm is provided, and some performance comparisons with a shift-reduce based algorithm are given which show the chart generator is much more efficient for generating all possible sentences from an input specification.
Improving the Efficiency of a Generation Algorithm for Shake and Bake Machine Translation Using Head-Driven Phrase Structure Grammar
May 09, 1995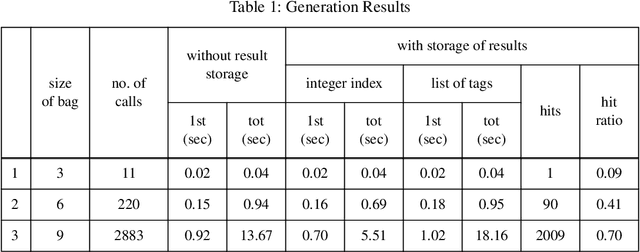
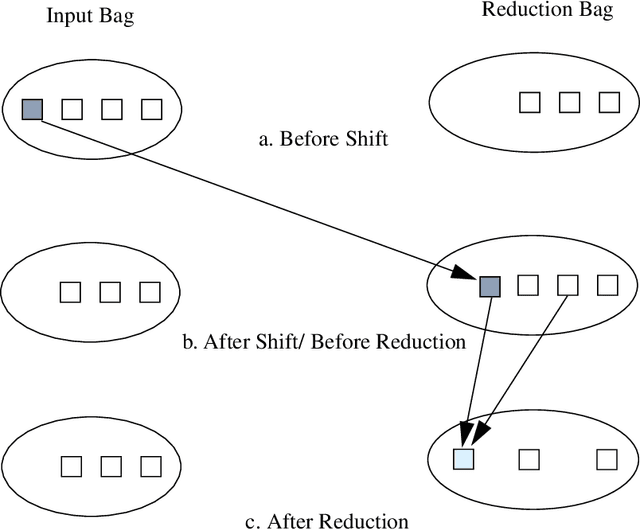
A Shake and Bake machine translation algorithm for Head-Driven Phrase Structure Grammar is introduced based on the algorithm proposed by Whitelock for unification categorial grammar. The translation process is then analysed to determine where the potential sources of inefficiency reside, and some proposals are introduced which greatly improve the efficiency of the generation algorithm. Preliminary empirical results from tests involving a small grammar are presented, and suggestions for greater improvement to the algorithm are provided.